




我们知道这个结果缓存可以用来缓解db压力
,但是你知道db的压力在哪里吗,他有多大压力?
以mysql为例。
下面我先贴上阿里云购买Mysql服务时默认的配置
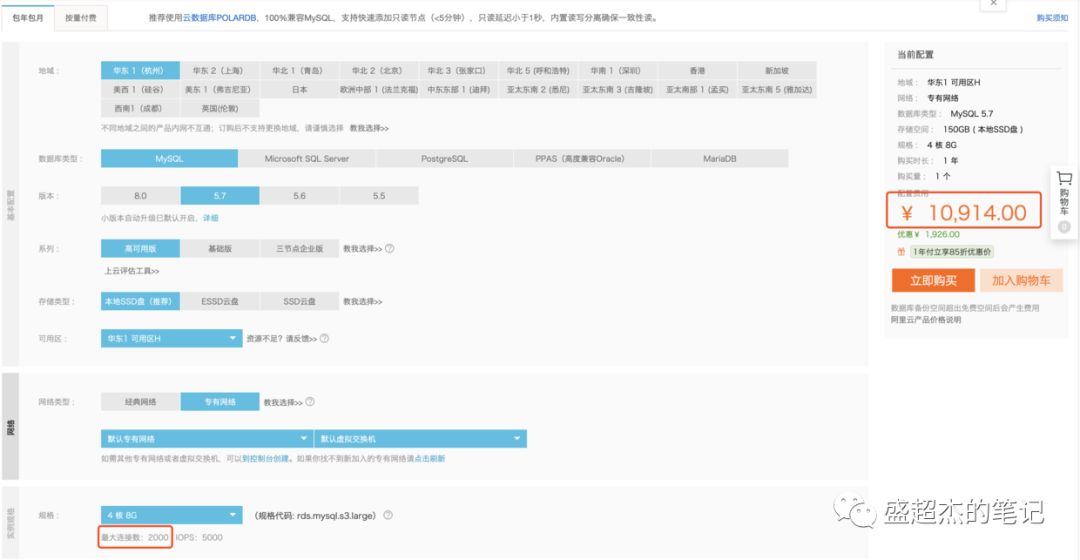
2个关键的参数,最大连接数2000,以及价格10000一年。我不是运维,不知道我们线上是怎么样的配置,这个应该算是企业入门款吧。
最大连接数2000代表什么,如果这2000个连接被一个应用独占,也就是说我的应用能有2000个线程同时访问数据库。
在理想环境的计算下,我一个db操作算他2ms的时间,tps能有多少,2000*1000/2=100w。
看起来很美吧。但是现实很残酷。
其一,上面这个理想tps,不管你应用集群多大,整个集群的服务能力就100wtps,你集群扩充再多也没用,连接数你必须均摊到各个应用。
其二,上面的tps是在理想环境下,我们没有考虑下面情况会影响db操作耗时的因素
一个事务不可能只有一个db操作
db资源的竞争
buffer_pool大小有限
回滚段也有限
索引没命中
…其他应该很多
我们来考虑极端情况,假设每个db操作要1秒,那么tps退化为2000,可见完全依赖db性能的服务势必不稳定,不可控
其三,大部分应用都在一个数据库实例下,分配的连接数很有线,以我目前在的应用为例
<property name="maxActive" value="20"/>
一个应用只给了20个数据库连接,按照理想环境测算tps,我们单个应用最大tps为20*1000/2=1w(实际肯定远小于这个数)
现在我们在有限的条件下,想把这个tps提高上去怎么办,使用缓存
本地缓存完全不花钱。
当然集群部署的机器肯定优先分布式缓存为主,本地缓存兜底。
我们的DB操作按照二八原则,80%都是读请求,这部分压力不需要全给到DB。
如果有很多写请求怎么办,分数据库实例。
emmmm,其实redis也是挺贵的,但能多应用公用。(50000连接数就问你够不够)
下面选择一个我个人认为企业级的配置。
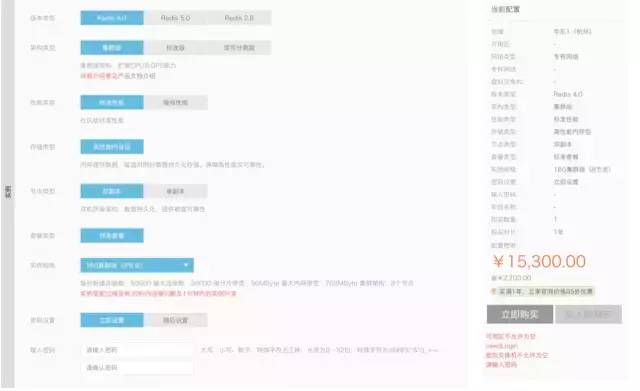
贵归贵,我来算下16个G能存储多大的数据量。
以我们的商品表为例子,我现在要缓存它。
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`wares_code` varchar(16) DEFAULT NULL COMMENT '商品CODE',
`wares_name` varchar(64) DEFAULT NULL COMMENT '商品名称',
`product_code` varchar(16) DEFAULT NULL COMMENT '父产品CODE',
`wares_simple_introduce` varchar(256) DEFAULT NULL COMMENT '商品简介',
`goods_no` varchar(32) DEFAULT NULL COMMENT '货号',
`wares_unit_price` int(11) DEFAULT NULL COMMENT '商品单价',
`discount` int(11) DEFAULT NULL COMMENT '商品折扣',
`wares_sales_volume` int(10) DEFAULT '0' COMMENT '商品销量',
`valid_flag` tinyint(1) DEFAULT '1' COMMENT '状态(0:禁用,1:启用)',
`date_create` datetime DEFAULT NULL COMMENT '创建时间',
`date_update` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
我粗略估计下字节数,varchar算汉字3个字节
4+3*(16+64+16+256+32)+2+2+2+1+4+4 = 1171Byte
16*1024*1024*1024 /1171 =1467w
可以存储1467w条商品信息,但是我们只需要把热点数据存到redis中去,算我们系统有10w个商品,还是根据二八原则,只需要2w个商品存储到redis。(实际上没那么多商品,我们系统不说了)
2:1467 可见这个redis 还是挺经用的。
百分之80的请求都走redis的话,把资源让给写请求,整体系统的性能就提升了。(自己脑补)
从另一个角度看缓存为何减轻压力。我们应用使用的缓存是对数据库缓存(buffer_pool)的一个扩展,并且也减少资源竞争(但是引入一致性问题)。
总结一下。
db提供的能力是有限并且不稳定的,也许你的应用,现在db的能力可以满足。但是到了某个阶段,与其花大价钱去提升db配置(可能也减少不了竞争),使用缓存回报更大(性能更好),更廉价。
以上存储瞎扯,并不精确,请意会我的思想。有想法可以留言交流。
点击原文交流哈
