




本文算是一个学习笔记,是基于我看过的资料和书的整理,目的是把自己的知识更加连贯的串起来。废话不多说我们开始。
一 什么是决策树
百闻不如一见,我们直接上图更好理解。
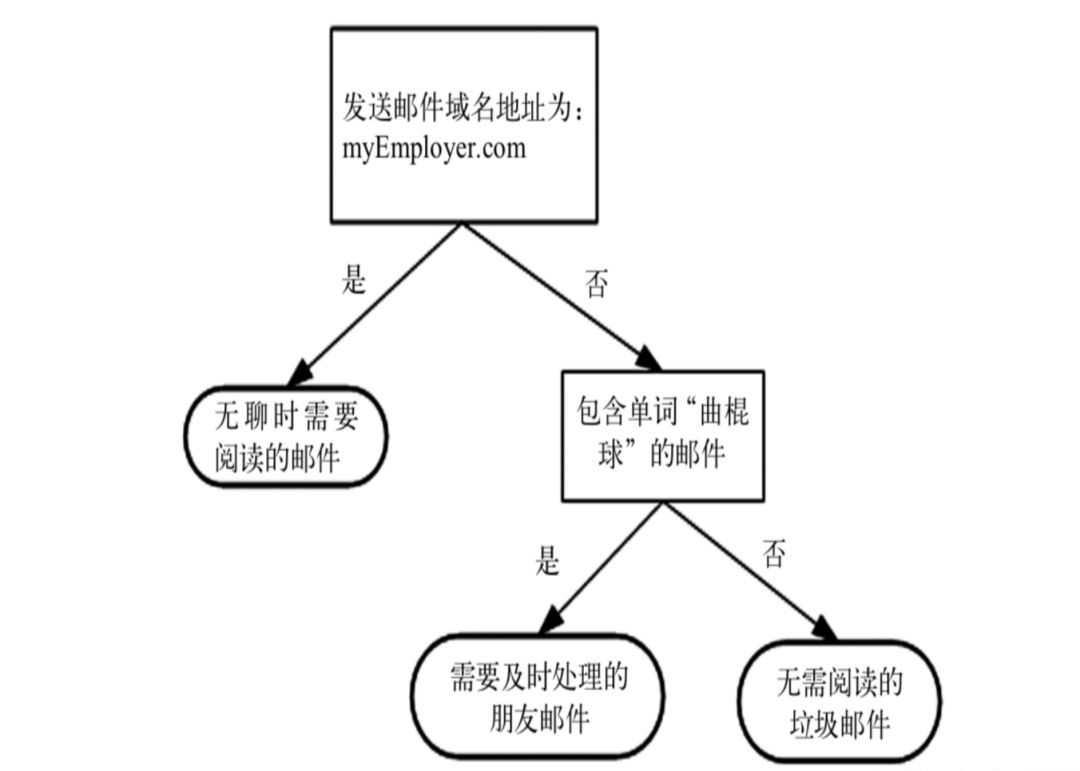
如上图所示,这是一颗树(这个的例子是一颗二叉树,其实它可以是任意的树),我们可以看到树的父节点(包括根结点在内的所有非叶子节点)也就是图中长方形节点,都是一些判断条件(域名是否是myEmployer.com,是否包含单词“曲棍球”等)。树的叶子节点也就是椭圆形的节点都是一些分类信息,其中图中根据父节点的判断条件可以把收到的邮件分为三类:“无聊时需要阅读的邮件”,“需要及时处理的朋友的邮件”和“无需阅读的垃圾邮件”。
这就是一颗决策树最直观的感受,当来了一封邮件,你把这个邮件扔到这颗树里,这封邮件从根节点开始迭代直到落到了叶子节点,这时候叶子节点所表示的类别就是这份邮件的类别。
二 决策树的构建
通过第一小节,我们已经大概了解了什么是决策树。那么我们怎么构建这么一颗决策树呢?我们来回顾一下机器学习的基本套路。首先我们要拿到样本数据,通过一些“规则”来训练这些样本数据,从中找出规律得出模型,再用这个模型去做预测。对于决策树来说,同样的我们首先获取一些样本数据,利用这些样本数据根据某些规则来构建出这么一颗决策树,然后再用这颗决策树来预测。
这里我用《机器学习实战》中的一个场景来举例说明,假设我们现在有下表这么4个样本。
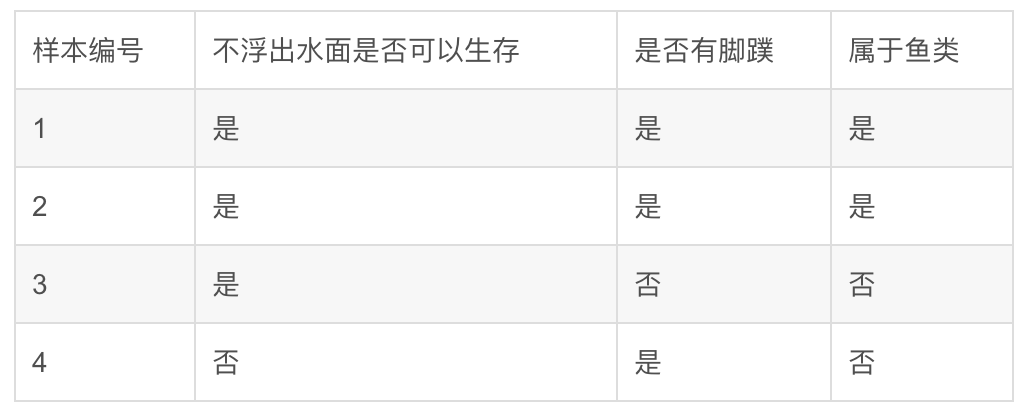
简单解释一下表格中的数据含义,其实就是通过两个特征:“不浮出水面是否可以生存”和“是否有脚蹼”,来判断一个动物属于不属于鱼类。很显然这是一个分类问题。
现在我们尝试这用这4条样本数据来构建决策树。我们一步步来,假设我们构建来一个深度为1的决策树,(这里画图的时候,节点我都用圆形了)
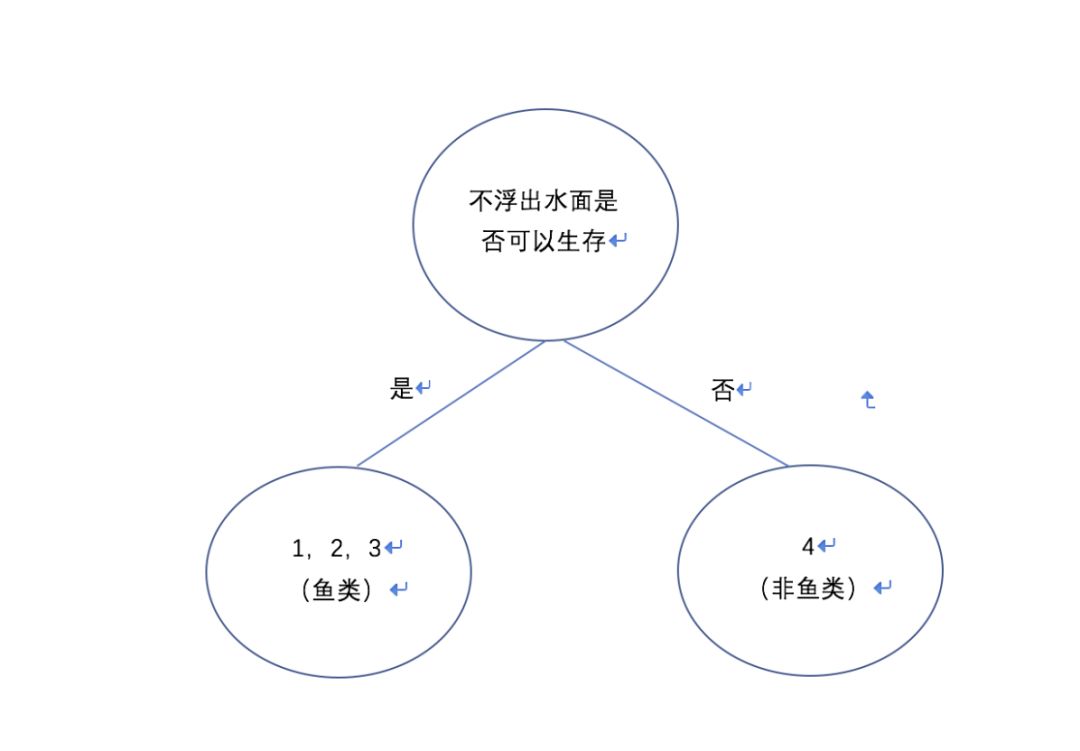
这里我们限定了决策树的深度是1(其实这是预剪枝的方式之一)
我们来看这颗树。我们可以看到根据这一个特征,我们可以划分出是否属于鱼类。划分的结果就是,样本编号为1,2,3的动物属于鱼类,编号4不属于鱼类。为什么会这样呢?根据上面的样本数据表,编号3的样本是不属于鱼类的。
当1,2,3被划分到同一个叶子节点,1,2是属于鱼类,3不属于鱼类,根据多数投票或者概率来说,这个叶子节点属于鱼类的概率要大,所以这个叶子节点的类别就被划分为鱼类。
那么怎么做才能提高划分的准确率呢? 我们试着加大树的深度,我们来构建一个深度为2的决策树,如下图:
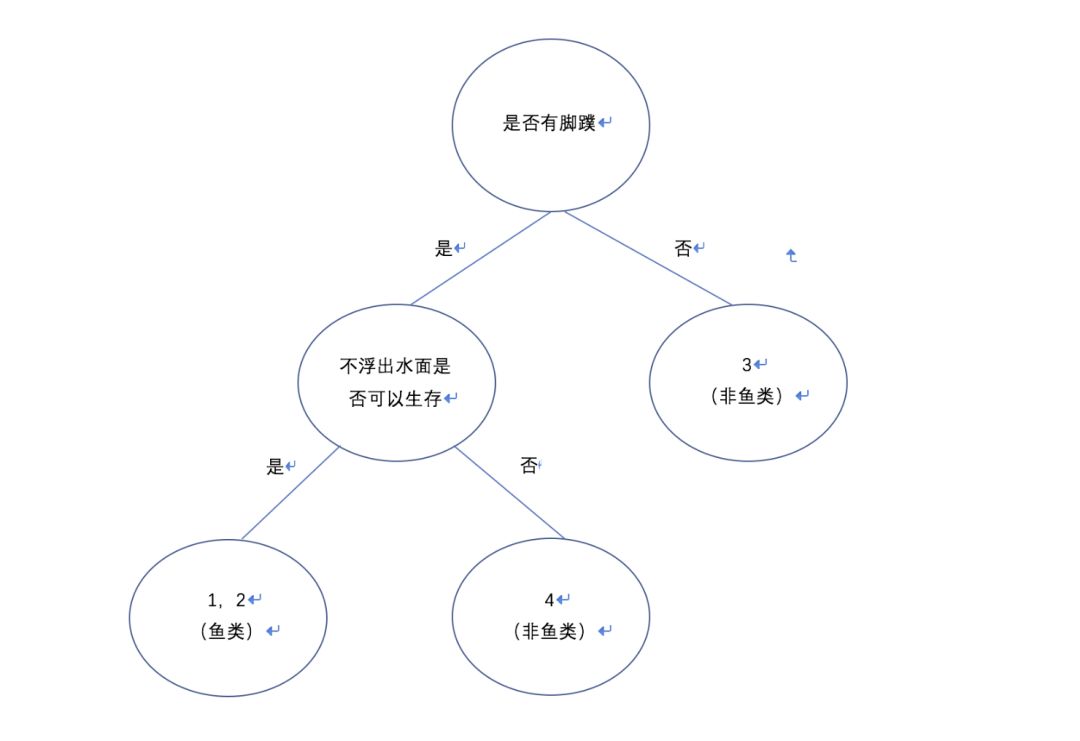
我们可以看到加深了树的深度,可以有效的提高决策树的准确率。但是又会带来新的问题,过拟合的问题。什么是过拟合,就是说模型太契合训练的样本了,好像为了追求在训练样本的准确率不惜一切代价,那么训练出来的模型就具有特殊性了,不具备广泛性。那么这个模型在训练集上可能准确率很高,但是在测试集预测的时候准确率就可能下降很多。
目前为止我们还是不知道怎么构建决策树,拿刚才构建的深度是2的决策树举例。为什么树的根节点是“是否有脚蹼”而不是“不浮出水面是否可以生存”呢?
这是涉及到了一个名词叫做“纯度”,我们先来看深度为1的那颗树,左边是鱼类的叶子节点里面包含了1,2,3,但是编号3的种类并不是鱼类,右边不是鱼类的叶子节点里包含了编号4,编号4确实不是鱼类。那么我们可以说右节点比左节点要“纯”。
在划分节点的时候也是同样的,所有样本既有鱼类又有非鱼类,我们的目的就是要把它们区分开,换句话说也就是让每一个节点更纯。假如说原始的样本鱼龙混杂,纯度是0,我们想要它变的纯,那么就开始尝试计算,假设我们按照“是否有脚蹼”划分一次,纯度会变成百分之60,按照“不浮出水面是否可以生存”划分一次纯度变成了百分之50. 按照前者划分纯度会提升的更高,我们肯定要选择提升更高的特征来先划分。(这里的纯度是伪概念,帮助大家理解,用到的数据也都虚构。)
那么问题又来了,我们是知道了可以“纯度”来做划分的依据,但是这个纯度是怎么得出来的,该怎么量化比较呢?那么就引出来了下一个概念叫做“熵”。
三 用熵来量化
前两节,我们都是从“感性”的角度来了解决策树,这一节我们要用量化的方式构建一颗决策树。总的来说我们在构建决策树的时候大的目标就是:“将无序的数据变的更加有序”,拿第二节的鱼类的划分举例,将4个样本一下子全呈现在你的面前,你并不知道哪些是鱼类,哪些不是鱼类,因为这些样本数据是没有杂乱的,无序的。如果我们将这4个样本,按照某种规律划分成两堆,那么你就能轻易的说出哪些是鱼类,哪些不是鱼类。
那么组织杂乱无章数据的一种方法就是使用信息论度量信息。在划分数据集之前之后信息发生的变化称为信息增益(纯度的提升),知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测哪种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事物可能划分在多个分类之中,则符号xi信息定义为:
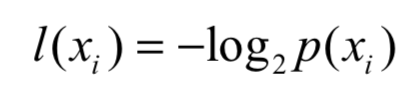
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
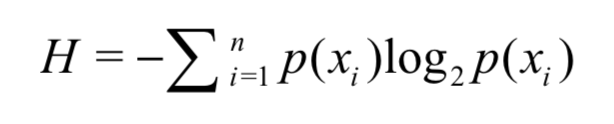
拿第二节的鱼类举例计算没有划分之前的熵:
p(鱼类)=2/4=0.5,p(非鱼类)=2/4=0.5,h总=-(0.5*log0.5+0.5*log0.5)=1, 可以得出总的信息熵为1。
如果以“不浮出水面是否可以生存”的特征进行划分后的熵:
左叶子节点的信息熵 p左(鱼类)=2/3,p左(非鱼类)=1/3,h左=-(2/3*log2/3+1/3*log1/3)=0.9182958340544896
右叶子节点的信息熵 p左(鱼类)=0 p左(非鱼类)=1 h右=-(0*log0+1*log1)=0(我们认为0*log0=0)
那么h浮=h左+h右=0.9182958340544896,信息增益为H浮=h总-h浮=0.08170416594551
如果以“是否有脚蹼”的特征进行划分后的熵:
左叶子节点的信息熵 p左(鱼类)=2/3,p左(非鱼类)=1/3,h左=-(2/3*log2/3+1/3*log1/3)=0.9182958340544896
右叶子节点的信息熵p左(鱼类)=0,p左(非鱼类)=1 h右=-(0*log0+1*log1)=0(我们认为0*log0=0)
那么h蹼=h左+h右=0.9182958340544896,信息增益为H蹼=h总-h蹼=0.08170416594551
当我们将两个特征的信息增益都计算出来后,就要开始比较,基本原则是:
1.H浮>H蹼,那么就按照““不浮出水面是否可以生存”来划分
2.H浮<H蹼,那么就按照““是否有脚蹼”来划分
3.H浮=H蹼,信息增益度相等的情况下,随意哪种划分方式都可以。
总结:到此我们决策树的概念和决策树的构建都已经了解。这里我们将的是比较简单的决策树供大家了解决策树的概念。关于决策树一些其他的细节,比如说,决策时的特征是多个离散值的时候,怎么选取划分的阈值,还有树的预剪枝和后剪枝预防过拟合的问题就再单独写一篇博客来介绍。
