




HASH JOIN:
MySQL 8.0.18 版本增加了一个新的特性hash join,关于hash join,通常其执行过程如下,首先基于join操作的一个表,在内存中创建一个对应的hash表,然后再一行一行的读另外一张表,通过计算哈希值,查找内存中的哈希表
hash join仅仅在join的字段上没有索引时才起作用,在此之前,不建议在没有索引的字段上做join操作,因为通常中这种操作会执行得很慢,但是有了hash join,它能够创建一个内存中的hash 表,代替之前的nested loop,使得没有索引的等值join性能提升很多。
准备数据:
####创建表
CREATE TABLE `t1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
key (name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
key (name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
##创建批量数据 10000行数据
delimiter //
DROP PROCEDURE IF EXISTS proc_batch_insert;
CREATE PROCEDURE proc_batch_insert()
BEGIN
DECLARE pre_name BIGINT;
DECLARE ageVal INT;
DECLARE i INT;
SET pre_name=139;
SET ageVal=100;
SET i=1;
WHILE i <= 10000 DO
INSERT INTO t1(`name`,age,create_time,update_time) VALUES(CONCAT(pre_name,'@qq.com'),(ageVal+1)*rand()%30,NOW(),NOW());
INSERT INTO t2(`name`,age,create_time,update_time) VALUES(CONCAT(pre_name,'@qq.com'),(ageVal+1)*rand()%30,NOW(),NOW());
SET pre_name=pre_name+100;
SET i=i+1;
END WHILE;
END //
delimiter ;
##执行存储过程
call proc_batch_insert();
Hash Join怎样确认:
通过 explain format=tree 能够看到hash join是否被使用,这是新加的功能,而传统的explain仍然会显示nested loop,这种情况容易产生误解。
mysql> EXPLAIN FORMAT=TREE SELECT COUNT(*) FROM t1 INNER JOIN t2 ON t1.age=t2.age;
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Inner hash join (t1.age = t2.age) (cost=9824728.58 rows=9823708)
-> Table scan on t1 (cost=0.01 rows=9939)
-> Hash
-> Table scan on t2 (cost=1012.65 rows=9884)
|
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
测试:
MySQL8.0.19版本
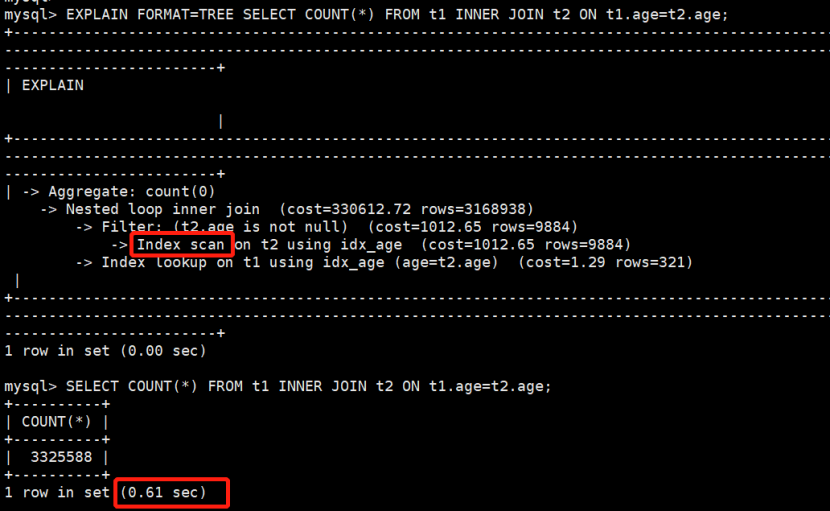
1)索引情况下
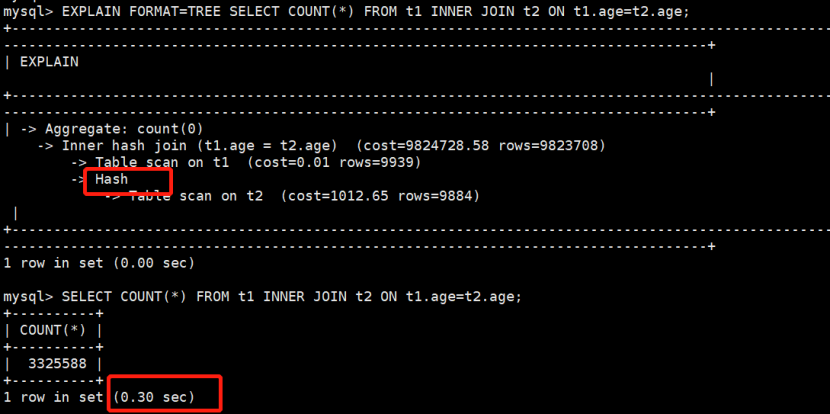
2)Hash情况下
3)不走hash join 的性能因版本问题就没法测试。不管设置参数optimizer_switch=‘hash_join=off’ 也还是默认使用hash join开启的
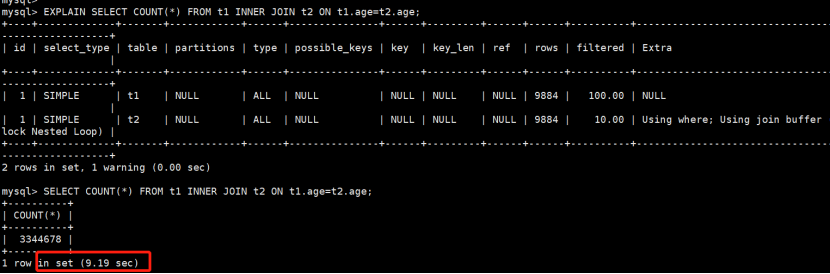
下面是5.7.28版本的
结果对比:
hash join:0.3秒
基于索引的join:0.6秒
非hash join: 9秒
以上测试因为是本机的虚拟机,仅作为参考,但从结果对比可以看出,hash join执行性能确实提升很多。
配置hash join:
1.optimizer_switch 中的 hash_join=on/off,默认为onsql语句中指定HASH_JOIN或者NO_HASH_JOIN,
2.mysql 8.0.3引入的SET_VAR优化器提示还是很好用的,可用来设置语句级参数(oracle支持,mariadb记得也支持了的)
SELECT/*+ set_var(optimizer_switch='hash_join=off') set_var(join_buffer_size=4M) */ COUNT(*) FROM t1 INNER JOIN t2 ON t1.age=t2.age;
SELECT/*+ set_var(optimizer_switch='hash_join=off') set_var(join_buffer_size=4M) */ COUNT(*) FROM t1 INNER JOIN t2 ON t1.age=t2.age;
8.0.19版本测试过,基本无用。就是说无索引的字段默认走hash索引
官方解释如下:(HASH_JOIN, NO_HASH_JOIN: Enable or disable use of a hash join for the specified tables (MySQL 8.0.18 only; has no effect in MySQL 8.0.19 or later).
限制:
hash join只能在没有索引的字段上有效
hash join只在等值join条件中有效
hash join不能用于left join和right join最后:
hash join 是一个比较强大的join选项,也许这仅仅是一个开头,在不久的将来,基于它可能会延伸出更多更强大的特性,比如支持left join和right join等等。Hash join看到他的优点,在考虑一下缺点。毕竟刚上线需要实践中进行磨炼。希望对大家有所帮助
