





思维决定行为,行为决定结果,结果产生数据,数据驱动PPT。
阶段性跟领导汇报了一版PPT后,潭主感觉自己走了不少弯路。
有些路注定是要自己走的,不过路上也有一些心得。
本期凿墙的主角是牛X闪闪的华为Gauss。
学好数理化,走遍天下都不怕
高斯是谁?潭主还真说不清,只好百度一下。
高斯,英文名Gauss,德国数学家,有数学王子的美誉,与阿基米德、牛顿和欧拉齐名。
联想到openEuler,不禁在想华为的品牌经理都是数学系毕业的?
说是高斯的肖像曾被印在从1989年至2001年流通的10元德国马克纸币上,可惜无缘相见。
看着高斯前辈的学术成果,除了正态分布的高斯曲线,其他什么质数分布定理和最小二乘法,一脸茫然。
顿感自己的数理化白学了。
言归正传。
枝繁叶茂的GuassDB
华为的数据库产品线采用了GaussDB的品牌。
官网显示:GaussDB(for openGauss)是华为基于openGauss自研生态推出的金融级分布式,云原生数据库,产品具有企业级复杂事务混合负载能力,同时支持分布式事务强一致,同城跨AZ部署,数据0丢失......(潭主对于云原生的说法有异议)
近十年,华为在数据中心市场持续发力,成功转型,摇身一变成了IT和云计算的领导厂商,一时国内风光无限,要不是老美举国压制,这会儿更V5。
背靠大树好乘凉,GaussDB也借势走强,成了国产分布式数据库大厂。
不过,国内数据库产品发展时间尚短,产品缺乏用户积累,走向不清时有发生,摩擦成本较高。
之前接触时先是Gauss 100/200/300,再是Guass A/T ,很快又进化成了GaussDB系列,依然很花哨。
openGauss生态方面,中低端集中式采用了开源模式,自己留下了高端分布式的GaussDB(for openGauss)。
不知道华为内部是咋看Guass的,潭主感觉产品线过长,虽如专家所说要看应用场景,但结果是SQL、NoSQL、NewSQL等细分产品接踵而来。
一句话,“Guass for Any Database!”
存得下,算得快,算得准
在华为的山头,潭主当然要唱GaussDB的歌。
下图是GaussDB的分布式架构图。
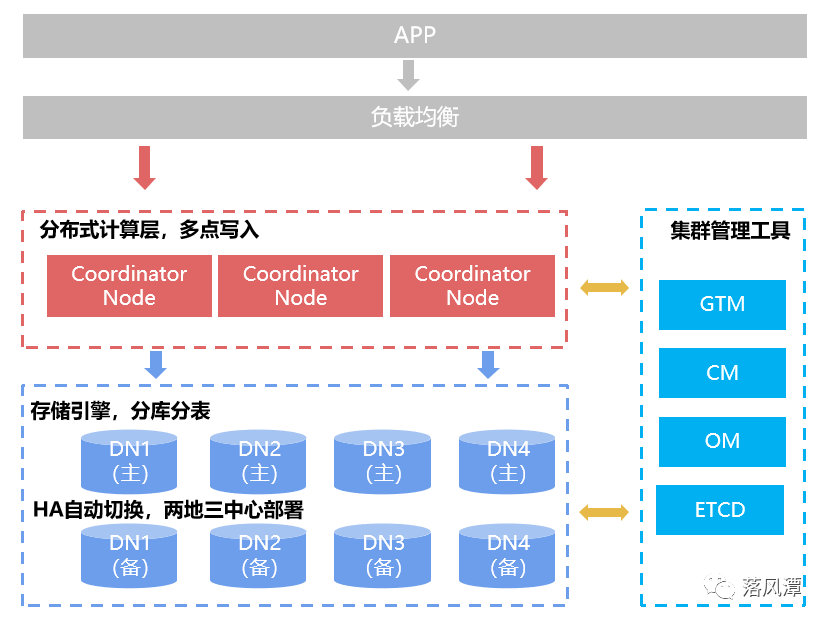
需要明确的是openGauss的集中式和分布式是不同的产品线。
CN(Coordinator Node):协调节点,无状态SQL引擎,通过负载均衡实现分布式接入,主流技术实现。
DN(Data Node):存储引擎,主要用于多副本数和Sharding。
GTM(Global Transaction Manager):通过CSN(Commit Sequence Number)保持分布式事务的全局一致性。
分布式让数据存得下,计算下推和DN间直接互访,避免CN瓶颈,让数据算得快,分布式事务一致性,让数据算得准。
旧时王谢堂前燕,飞入寻常百姓家
近期学GaussDB时,又重温了当年搞DB2 DPF时的情景。
DPF(Database Partitioning Feature)是DB2的一个分布式功能,当年能用得上的都是世家大族。
在IT硬件投入有限的情况下,集中式面临的问题就是容量和性能的悖论,最后就一个字,慢!
想当年主流的OLAP场景中,只有皇族大行才配得上高贵的Teradata,而DB2 DPF靠着IBM小型机倒也分了不少羹。
虽然DB2 DPF在十几年前就实现了分布式,但其架构“缺陷”也不少。
所有Node需要共享DB2的实例代码sqllib,IBM的解决方案是GPFS。 Node有角色区别,Catalog Node是瓶颈点。 Data Node虽然可以并行处理,但存在单点故障。
现在想来,当初的DPF经验对今天凿墙大有裨益。
后来看到GaussDB的SQL感觉很亲切,尤其是Distribute by Replication的功能在细节上很到位。
十年前,GreenPlum实现了分布式数据库的数据镜像,提升了系统高可用性,但当时国内用户对于PostgreSQL的接受度有限。
十年后,PG在国内的地位有所提升,尤其是华为建了openGauss生态后,更是让一众粉丝跟风,倒旗易帜。
虽然GaussDB的架构复杂了些,但也解决了DB2 DPF上存在的技术问题。
青出于蓝而胜于蓝。

工欲善其事,必先利其器
细品一下,OceanBase和GaussDB的区别还是挺大的。
这种差异来自于互联网和传统企业的产品设计思路,但都是参照之前的轮子造出了新马车。
IT新基建有一个大的逻辑,短期看增量,长期看存量。
增量建设大都是小打小闹,而存量迁移方显英雄本色。
工具不是万能的,但没工具是万万不能的。
Gauss能拿的出手的似乎只有UGO,一个评估Oracle对象语法兼容性的工具。
DRS(Data Replication Service):主要包括数据迁移、校验和回放功能模块,总体上属于说的比唱的好听,估计真用的时候,会发现有不少限制条件,可以表述为历史局限性。
DAS(Data Admin Service):图形管理工具,Gauss版的PL/SQL Developer,能顺道做点gs_dump和gs_restore,值得一提的是有个DBA用的AIOps模块。
友商的产品体系总是颇为相似,人无我有,人有我优,人优我强,最后人强我卷。
再补充一句,要想真的把产品优势发挥出来,最好还是配个原厂的云底座,别买得起马,配不起鞍。
逻辑集群就是伪租户
潭主对分布式数据库的“租户”有些执着。
“你们的GaussDB支持多租户吗?”
厂商张嘴就来:“支持!”
但仔细一问,压根不是那么回事。
GaussDB有个逻辑集群的概念,这也能叫租户?
逻辑集群只是基于Node Group机制来划分物理节点的一种集群模式,但限制过多,感觉中看不中用,估计实际业务场景中用户案例不多。
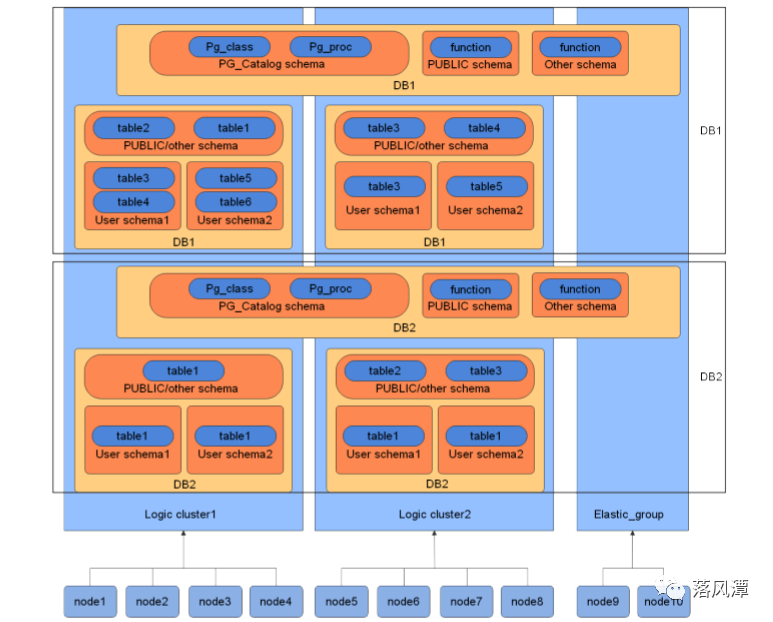
Node Group跟DB2 DPF的Partition Group差不多,在特定资源上运行不同的负载,让物理资源和业务逻辑形成对应关系。
这部分太细节,暂不展开,留些关键词做个备忘( gs_lcctl、gs_expend、gs_shrink、gs_cgroup),有机会实践了再分享。
OceanBase和GuassDB,一个互联网,一个企业级,二者不好直接比,只能从Solution层面看,请大家坐等潭主的凿墙连载。
行百里者半九十
回顾2014年至今,小型机从100多减少到40出头,看似进展还行,但其实都是小打小闹。
用凿墙思维重新审视,发现早期凿的都是土墙,现在轮到钢筋混凝土了。
行百里者半九十,反过来看,潭主要做的事其实才刚开始,到了深水区,每走一步都很艰难。
有趣的是潭主这边正筹划着凿墙事宜,陈坤和辛芷蕾那边就出场了,一个外企时代的商战故事,让潭主的记忆停留在了亮马河的红色宝马上。
人生只是过程,输赢并不重要。
圣诞将至,落风潭主祝读者朋友们圣诞快乐!
- END -
---感谢阅读。如果觉得写得还不错,就请点个赞或“在看”吧。
公众号所有文章仅代表个人观点,与供职单位无关。

