




select
decode(sign(ksmchsiz - 80), -1, 0, trunc(1/log(ksmchsiz - 15, 2)) - 5)
bucket,
sum(ksmchsiz) free_space,
count(*) free_chunks,
trunc(avg(ksmchsiz)) average_size,
max(ksmchsiz) biggest
from
sys.x$ksmsp
where
inst_id = userenv('Instance') and
ksmchcls = 'free'
group by
decode(sign(ksmchsiz - 80), -1, 0, trunc(1/log(ksmchsiz - 15, 2)) - 5);
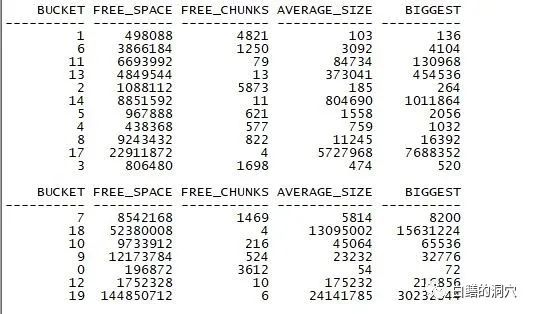
上面的数据里,共享池是十分正常的。
column indx heading "indx|indx num"
column kghlurcr heading "RECURRENT|CHUNKS"
column kghlutrn heading "TRANSIENT|CHUNKS"
column kghlufsh heading "FLUSHED|CHUNKS"
column kghluops heading "PINS AND|RELEASES"
column kghlunfu heading "ORA-4031|ERRORS"
column kghlunfs heading "LAST ERROR|SIZE"
select
indx,
kghlurcr,
kghlutrn,
kghlufsh,
kghluops,
kghlunfu,
kghlunfs
from
sys.x$kghlu
where
inst_id = userenv('Instance')
/
col "avg size" format a30 truncate;
col siz format 999999999999
SELECT KSMCHCLS CLASS, COUNT(KSMCHCLS) NUM, SUM(KSMCHSIZ) SIZ,
To_char( ((SUM(KSMCHSIZ)/COUNT(KSMCHCLS)/1024)),'999,999.00')||'k' "AVG SIZE"
FROM X$KSMSP GROUP BY KSMCHCLS;
虽然我们可以用很多脚本去分析与诊断共享池,不过很多对共享池的诊断脚本实际上都是需要遍历共享池内存才能获得结果的。我们看到的视图实际上不是真正的表,而是Oracle的内存的一个统计数据而已,很多统计是你访问这些视图时才去做的,因此这些操作都存在一定的风险。在一个已经病态的系统上,在业务比较高峰时候去做这些查询可能会导致系统HANG住。因此我们并不建议使用这些脚本常态化自动监控共享池,而是尽可能在有人值守的时候做这些操作。一旦出现了系统HANG死的情况,尽快杀掉执行这些操作的会话。
老白这些年也遇到过很多做运维自动化的人把这些脚本放在定时任务中,每隔几分钟就去做一次,这是十分有风险的操作,监控系统把数据库搞死也不是很难的事情。因此如果日常要对共享池进行监控的话,不能采用扫描共享池内存的方式,而是要从其他方面来进行迂回。从一些其他的风险比较小的现象侧面体现共享池的健康状态,这样才能避免运维自动化系统变成杀手系统。在大师问诊系统中,我们通过监控共享池相关的等待事件与系统METRIC是否异常来判断共享池是否存在隐患,而不是去扫描这些视图。
