




本文通过sklearn实现新型肺炎累计确诊病例的预测,主要算法包括线性回归,逻辑回国,多项式回归(二次曲线、三次曲线、四次曲线、五次曲线)等算法,具体到预测,主要包括算法的选择,很多时候算法的选择是通过数据的查全率查准率,训练集、测试集、检验集等上的准确率综合评估出来的,二是关于数据集的分拆,需要拆解为训练集、测试集分别进行验证。
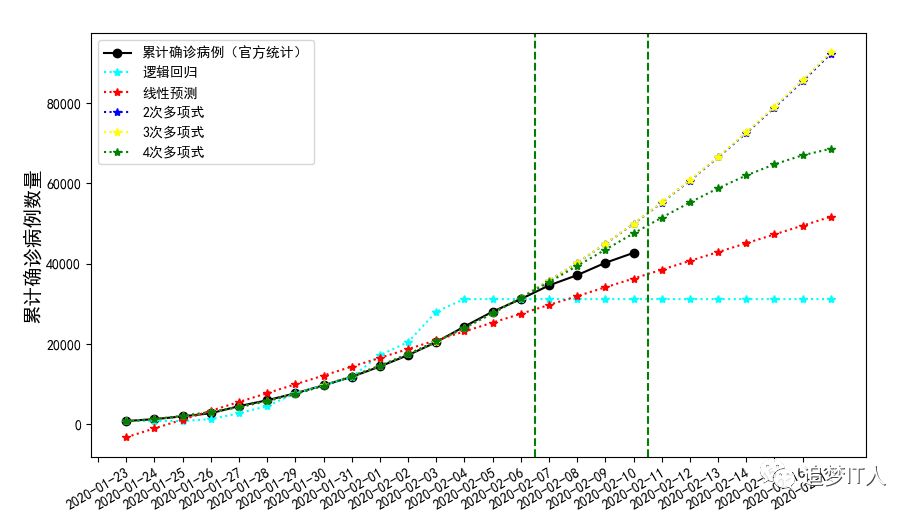
总的来说,训练集大概只有15条记录,训练集4条,还有预测的7条,从公开的图表来看,出现了2次波动,所以本模型效果一般。
如下:
import operator
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression,LogisticRegression
import matplotlib.pyplot as plt
def init_data():
# 原始数据
countrydatahistorys=[{'date': '2020-02-10', 'confirmedNum': 42708, 'suspectedNum': 21675, 'curesNum': 3998, 'deathsNum': 1017, 'suspectedIncr': 3536}, {'date': '2020-02-09', 'confirmedNum': 40224, 'suspectedNum': 23589, 'curesNum': 3283, 'deathsNum': 909, 'suspectedIncr': 4008}, {'date': '2020-02-08', 'confirmedNum': 37162, 'suspectedNum': 28942, 'curesNum': 2651, 'deathsNum': 812, 'suspectedIncr': 3916}, {'date': '2020-02-07', 'confirmedNum': 34594, 'suspectedNum': 27657, 'curesNum': 2052, 'deathsNum': 723, 'suspectedIncr': 4214}, {'date': '2020-02-06', 'confirmedNum': 31197, 'suspectedNum': 26359, 'curesNum': 1542, 'deathsNum': 637, 'suspectedIncr': 4833}, {'date': '2020-02-05', 'confirmedNum': 28060, 'suspectedNum': 24702, 'curesNum': 1153, 'deathsNum': 564, 'suspectedIncr': 5328}, {'date': '2020-02-04', 'confirmedNum': 24363, 'suspectedNum': 23260, 'curesNum': 892, 'deathsNum': 491, 'suspectedIncr': 3971}, {'date': '2020-02-03', 'confirmedNum': 20471, 'suspectedNum': 23214, 'curesNum': 630, 'deathsNum': 425, 'suspectedIncr': 5072}, {'date': '2020-02-02', 'confirmedNum': 17238, 'suspectedNum': 21558, 'curesNum': 475, 'deathsNum': 361, 'suspectedIncr': 5173}, {'date': '2020-02-01', 'confirmedNum': 14411, 'suspectedNum': 19544, 'curesNum': 328, 'deathsNum': 304, 'suspectedIncr': 4562}, {'date': '2020-01-31', 'confirmedNum': 11821, 'suspectedNum': 17988, 'curesNum': 243, 'deathsNum': 259, 'suspectedIncr': 5019}, {'date': '2020-01-30', 'confirmedNum': 9720, 'suspectedNum': 15238, 'curesNum': 171, 'deathsNum': 213, 'suspectedIncr': 4812}, {'date': '2020-01-29', 'confirmedNum': 7736, 'suspectedNum': 12167, 'curesNum': 124, 'deathsNum': 170, 'suspectedIncr': 4148}, {'date': '2020-01-28', 'confirmedNum': 5997, 'suspectedNum': 9239, 'curesNum': 103, 'deathsNum': 132, 'suspectedIncr': 3248}, {'date': '2020-01-27', 'confirmedNum': 4535, 'suspectedNum': 6973, 'curesNum': 51, 'deathsNum': 106, 'suspectedIncr': 2077}, {'date': '2020-01-26', 'confirmedNum': 2761, 'suspectedNum': 5794, 'curesNum': 49, 'deathsNum': 80, 'suspectedIncr': 3806}, {'date': '2020-01-25', 'confirmedNum': 1985, 'suspectedNum': 2684, 'curesNum': 38, 'deathsNum': 56, 'suspectedIncr': 1309}, {'date': '2020-01-24', 'confirmedNum': 1297, 'suspectedNum': 1965, 'curesNum': 38, 'deathsNum': 41, 'suspectedIncr': 1118}, {'date': '2020-01-23', 'confirmedNum': 830, 'suspectedNum': 1072, 'curesNum': 34, 'deathsNum': 25, 'suspectedIncr': 680}]
# 按照时间排序全国趋势数据
countrydatahistorys=sorted(countrydatahistorys, key=operator.itemgetter('date'))
# 结构化全国各省图表所需数据
xdata=list(range(len(countrydatahistorys)))
xlabel=list(row['date'] for row in countrydatahistorys)
# 追加预测未来一周的自变量X
xdata.extend(list(range(19, 26)))
from datetime import date, datetime, timedelta
start_date = date(2020, 2, 11)
xlabel.extend(list(str(start_date + timedelta(i)) for i in range(7)))
# 生成累计确诊数据,即y值
confirmedNum=list(row['confirmedNum'] for row in countrydatahistorys)
suspectedNum=list(row['suspectedNum'] for row in countrydatahistorys)
#进行数据格式转换,生成训练集、测试集和预测集
Xlabel=np.array(xlabel).reshape(-1, 1)
X=np.array(xdata).reshape(-1, 1)
y=np.array(confirmedNum).reshape(-1, 1)
X_train=X[:15]
X_test=X[15:19]
X_predict=X[19:]
y_train=y[:15]
y_test=y[15:19]
return X_train,X_test,y_train,y_test,X_predict,X,y,xlabel
X_train,X_test,y_train,y_test,X_predict,X,y,Xlabel=init_data()
lr=LinearRegression().fit(X_train,y_train)
coef=lr.coef_
intercept=lr.intercept_
score_train=lr.score(X_train,y_train)
score_test=lr.score(X_test,y_test)
y_predict=lr.predict(X_test)
#--------------------------------
lg=LogisticRegression(C=0.2)
lg.fit(X_train,y_train)
y_lg_predict=lg.predict(X)
print('y_lg_predict=',y_lg_predict)
#--------------------------------
poly1 =PolynomialFeatures(degree=1)
X_ploy =poly1.fit_transform(X_train)
l1=LinearRegression()
l1.fit(X_ploy,y_train)
#--------------------------------
poly2 =PolynomialFeatures(degree=2)
X_ploy =poly2.fit_transform(X_train)
l2=LinearRegression()
l2.fit(X_ploy,y_train)
#--------------------------------
poly3 =PolynomialFeatures(degree=3)
X_ploy =poly3.fit_transform(X_train)
l3=LinearRegression()
l3.fit(X_ploy,y_train)
#--------------------------------
poly4 =PolynomialFeatures(degree=4)
X_ploy =poly4.fit_transform(X_train)
l4=LinearRegression()
l4.fit(X_ploy,y_train)
#--------------------------------
poly5 =PolynomialFeatures(degree=5)
X_ploy =poly5.fit_transform(X_train)
l5=LinearRegression()
l5.fit(X_ploy,y_train)
#--------------------------------
poly6 =PolynomialFeatures(degree=6)
X_ploy =poly6.fit_transform(X_train)
l6=LinearRegression()
l6.fit(X_ploy,y_train)
fig=plt.figure(figsize=(10,5.5))
plt.rcParams['font.sans-serif']=['SimHei']
# 画出实际值,注意X和y不等,X训练集加测试集和实际y值相等
plt.plot(np.vstack((X_train,X_test)),y,color='black',marker='o',linestyle='-',label='累计确诊病例(官方统计)')
plt.plot(X,y_lg_predict,color='cyan',marker='*',linestyle=':',label='逻辑回归')
plt.plot(X,intercept+X*coef,color='red',marker='*',linestyle=':',label='线性预测')
plt.plot(X,l2.predict(poly2.fit_transform(X)),color='blue',marker='*',linestyle=':',label='2次多项式')
plt.plot(X,l3.predict(poly3.fit_transform(X)),color='yellow',marker='*',linestyle=':',label='3次多项式')
plt.plot(X,l4.predict(poly4.fit_transform(X)),color='green',marker='*',linestyle=':',label='4次多项式')
# 设置x轴标签及其字号
plt.xlabel('日期',fontsize=14)
# 设置y轴标签及其字号
plt.ylabel('累计确诊病例数量',fontsize=14)
# 设置X轴序列标签值
plt.xticks(X-1,Xlabel,rotation=30,fontsize=10)
# 添加训练集、测试集、预测集分割垂直直线
plt.axvline(x=14.5,linestyle='--',c="green")
plt.axvline(x=18.5,linestyle='--',c="green")
# 添加测试集的预测结果数据标签
# for x,y in zip(X_test.tolist(), y_predict.tolist()):
# plt.text(x[0],y[0],'{:5.0f}'.format(y[0]), fontsize=8)
# 显示图例
plt.legend()
plt.show()
长按二维码关注“追梦IT人”

QQ群号:763628645
QQ群二维码如下, 添加请注明:姓名+地区+职位,否则不予通过

订阅我的微信公众号“杨建荣的学习笔记”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

7
近期热文
你可能也会对以下话题感兴趣。点击链接就可以查看。
8
转载热文
你可能也会对以下话题感兴趣,文章来源于转载,点击链接就可以查看。
最后修改时间:2020-03-05 16:36:33
文章转载自杨建荣的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
