




分析统计信息
CBO优化器在判断采用何种执行方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有多少行、每行的长度等信息。这些统计信息起初在数据库中是没有的,需要做analyze后才收集的,很多的时侯过期的统计信息会令优化器做出一个错误的执行计划,因此统计信息的准确性对SQL执行性能至关重要。
概述
CBO优化器需要根据表/索引中的数据来选择查询数据的方式,由于表中的数据量很大,不可能每次执行查询时实时的统计表中的数据量以及数据分布,所以需要定期分析数据,把表和索引的数据分布情况保存到数据字典里,以便优化器使用,这就是统计信息。
统计信息保存在数据字典中,主要包括表,表分区,索引,索引分区,列,列的直方图。一般主要关注表和索引上的统计信息,重点关注数据量和数据块数。
表 4-1 统计信息对应的视图
| 对象描述 | 视图 | 关键列 |
|---|---|---|
| 表上的统计信息 | MY_TABLES | ● NUM_ROWS:表中的数据量。 ● BLOCKS:表占用的数据块。 ● LAST_ANALYZED:最近生成统计信息的时 间,如果为空,说明没有统计信息。 |
| 表分区上的统计信息 | MY_TAB_PARTIT IONS | ● NUM_ROWS:表中的数据量。 ● BLOCKS:表占用的数据块。 ● LAST_ANALYZED:最近生成统计信息的时间,如果为空,说明没有统计信息。 |
| 索引的统计信息 | MY_INDEXES | ● NUM_ROWS:索引中的数据量。 ● LEAF_BLOCKS:索引叶子节点块数。 ● DISTINCT_KEYS:该列有多少个不同的取 值。 ● LAST_ANALYZED:最近生成统计信息的时 间,如果为空,说明没有统计信息。 |
| 索引分区的统计信息 | MY_IND_PARTIT IONS | ● NUM_ROWS:索引中的数据量。 ● LEAF_BLOCKS:索引叶子节点块数。 ● DISTINCT_KEYS:该列有多少个不同的取 值。 ● LAST_ANALYZED:最近生成统计信息的时 间,如果为空,说明没有统计信息。 |
| 列的统计信息 | MY_TAB_COLU MNS | ● NUM_DISTICT:该列有多少个不同的取 值。 ● LOW_VALUE:最小值。 ● HIGH_VALUE:最大值。 ● LAST_ANALYZED:最近生成统计信息的时间,如果为空,说明没有统计信息。 |
| 列的直方图 | MY_HISTOGRA MS | ● ENDPOINT_NUMBER:统计划分后的列对 应的桶编号。 ● ENDPOINT_VALUE:小于对应列值的累积行数。 ● ENDPOINT_ACTUAL_VALUE:统计划分后的列值。 |
收集统计信息
● 用ANALYZE命令收集统计信息。
--收集表SECTIONS的统计信息。
ANALYZE TABLE SECTIONS COMPUTE STATISTICS;
● 利用GaussDB T内置的高级包来收集统计信息。
--收集表SECTIONS的统计信息。
CALL DBMS_STATS.GATHER_TABLE_STATS(
ownname=> 'sys',
tabname=>'sections',
estimate_percent=>100,
method_opt=>'for all columns'
)
其中各个参数的含义如下:
– ownname,待收集统计信息的用户名。
– tabname,待收集统计信息的表名。
– estimate_percent,采样率,范围为[0.000001,100]。如果为0的话将由系统自己选择采样方法,目前采样大小是128MB。
– block_sample,true块采样,false行采样,目前固定为块采样。
– method_opt,收集统计信息范围选项。支持FOR ALL COLUMNS收集所有列的统计信息,FOR ALL INDEXED COLUMNS只收集索引列的统计信息,默认是收集所有列的统计信息。
表的统计信息
通过ANALYZE语句收集表sections的统计信息,查询MY_TABLES视图,可以看出现表
sections的数据量是10000条,并且表上有一个索引。
ANALYZE TABLE sections COMPUTE STATISTICS;
Succeed.
SELECT TABLE_NAME, NUM_ROWS, COLUMN_COUNT, INDEX_COUNT, BLOCKS, LAST_ANALYZED FROM
MY_TABLES WHERE TABLE_NAME = 'SECTIONS';
TABLE_NAME NUM_ROWS COLUMN_COUNT INDEX_COUNT BLOCKS LAST_ANALYZED
---------------------------------------------------------------------------- ----------
SECTIONS 10000 2 1 38 2020-02-06 16:08:37.330650
1 rows fetched.
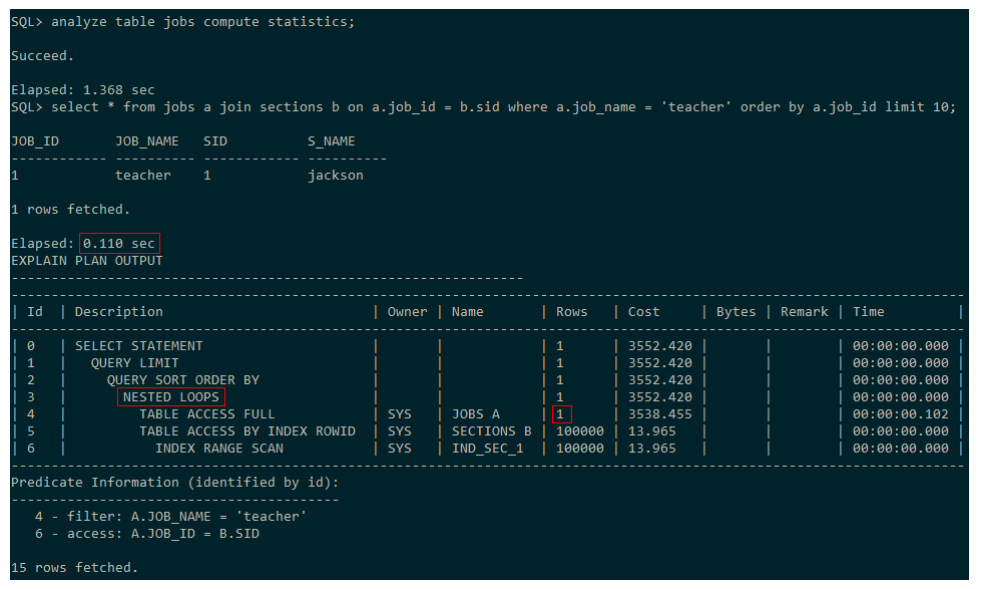
上面图中的NUM_ROWS显示的就是目标表的记录数,它是计算结果集card的基础,而card通常直接决定了CBO计算的成本代价。比如对于嵌套循环连接来说,驱动表的NUM_ROWS越大,则走嵌套循环的代价就越大。在没有索引的情况下,CBO可以利用表的统计信息来评估全表扫描的成本,以及表之间关联操作的顺序和成本。统计信息的准确性对SQL执行计划的选择十分重要。举例如下:

表JOBS中原本有1000000条数据,但在执行该条语句前999999条全部被删除了,但这里由于没有更新统计信息,所以还认为表JOBS中有100万数据,因此认为数据量较大,应采用哈希连接。
重新收集统计信息,再次执行该条SQL,发现走的NESTED LOOPS,因为表JOBS只有1
条数据,因此选它作为嵌套循环的驱动表,执行时间也快了5倍。
索引的统计信息
索引的统计信息包含索引的层级、叶子块的数量、该列有多少个不同的取值等维度信
息,可以通过查看视图MY_INDEXES来获取相关信息。
例如索引IND_JOB_1通过查看视图获取其统计信息:

可以看出该索引的层级是3,叶子块数是625,有40000个不同的取值,BLEVEL是CBO用于计算访问索引叶子块的成本,当层级越大,则从根节点到叶子节点所需要访问的数据块就越多,消耗的IO就越多,因此访问索引的代价就越大。而LEAF_BLOCKS存储的就是索引的叶子块的数量,主要用于计算对索引扫描的成本,当叶子块数量越多,则对索引做索引全扫描和索引范围扫描的代价就越大。
而DISTINCT_KEYS则主要反映索引的选择性,对于唯一索引来说,若索引列没有NULL值,则DISTINCT_KEYS的值就等于表的记录数。一般DISTINCT_KEYS的值与表中记录数的比,就可以判断索引的选择性,其比值越接近1,这个索引根据条件返回的数据就越少,走该索引的效率就越高。
列的统计信息
GaussDB T中列的统计信息用于描述表中列的各个维度的详细信息,主要包含列的distinct值的数量、最大值、最小值等信息。可以通过查询视图MY_TAB_COLUMNS来获取相关信息。
例如
SELECT COLUMN_NAME, NUM_DISTINCT, LOW_VALUE, HIGH_VALUE, NUM_NULLS FROM
MY_TAB_COLUMNS WHERE TABLE_NAME = 'JOBS';
COLUMN_NAME NUM_DISTINCT LOW_VALUE HIGH_VALUE NUM_NULLS
---------------------------------------------------------------- ----------
JOB_ID 40000 1 40000 0
JOB_NAME 4 doctor tester 0
2 rows fetched
上述查询字段中NUM_NULLS就是表示的就是目标列NULL值的数量,该值可以用来计算“IS NULL”和“IS NOT NULL”条件过滤结果集的card,NUM_DISTINCT表示的是目标列distinct值得数量,一般优化器用该值来评估目标列做等值查询的可选择率,公式如下
Selectivity = (1 / NUM_DISTINCT) * ((NUM_ROWS – NUM_NULLS) / NUM_ROWS)
此外,LOW_VALUE和HIGH_VALUE是目标列的最小值和最大值,CBO可用这两个值来计算目标列在范围查询时的可选择率。
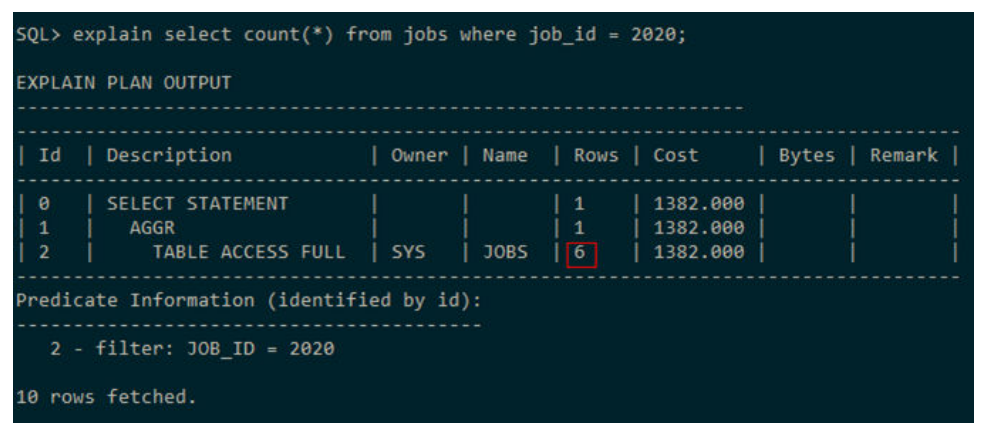
举例:现有表JOBS,通过查询可知该表有240000条数据。

现在执行如下SQL:
Select count(*) from jobs where job_id = 2020;
当没有直方图时,可以根据上面的公式来计算card:
Card = NUM_ROWS * selectivity
= NUM_ROWS * (1 / NUM_DISTINCT) * ((NUM_ROWS – NUM_NULLS) / NUM_ROWS)
= 240000 * (1 / 40000) * ((240000 - 0) / 240000)
= 6
这与目标SQL的实际执行计划中的ROWS值相符合:
直方图
数据库优化器会默认认为列的数据在最小值和最大值之间是均匀分布的,并根据这个原则来计算对应查询条件过滤后结果集的card,从而根据card来选择走什么样的执行计划。但实际列的数据大多是分布不均匀的,甚至是分布极度不均衡的,此时若还按照列均匀分布的原则去计算card就会存在误差,导致CBO选择不合理的执行计划,造成执行效率低下。举例如下:
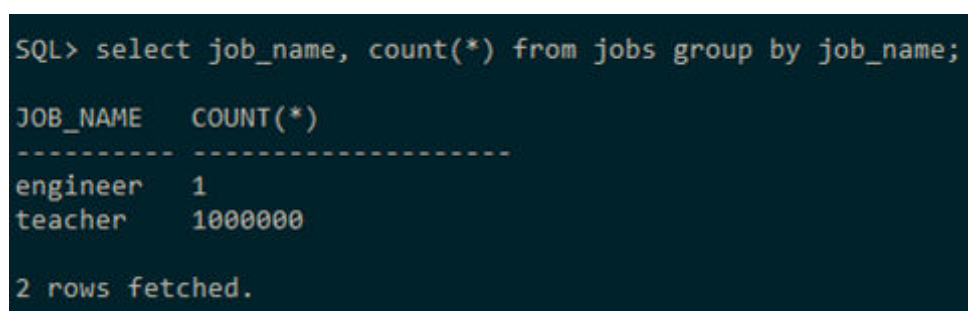
表jobs中有1000001条数据,其中1000000条数据的job_name的值都是‘teacher’,
只有一条记录的job_name是‘engineer’。同时有个表sections,有1000条数据,在
sid字段上有索引。
若没收集直方图信息,CBO认为jobs表条件过滤完有4245条数据,即使sections表在关
联列上有索引,但因jobs数据较多不适合走嵌套循环,因而走的HASH JOIN。
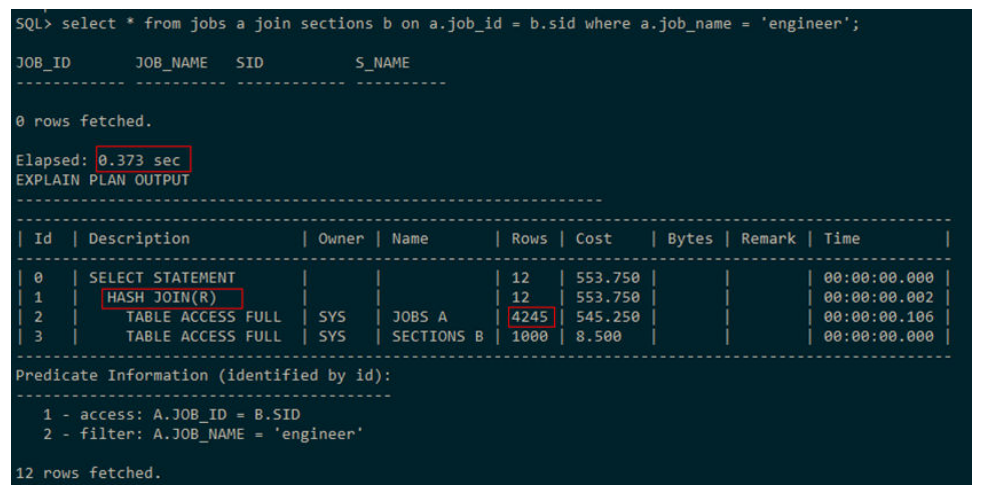
收集完统计信息后,CBO根据直方图可知,表jobs在条件过滤完后只有一条记录,适合做驱动表,且被驱动表在关联列上有索引,因此执行计划选择走NESTED LOOPS,执行时间也比之前快了3倍。
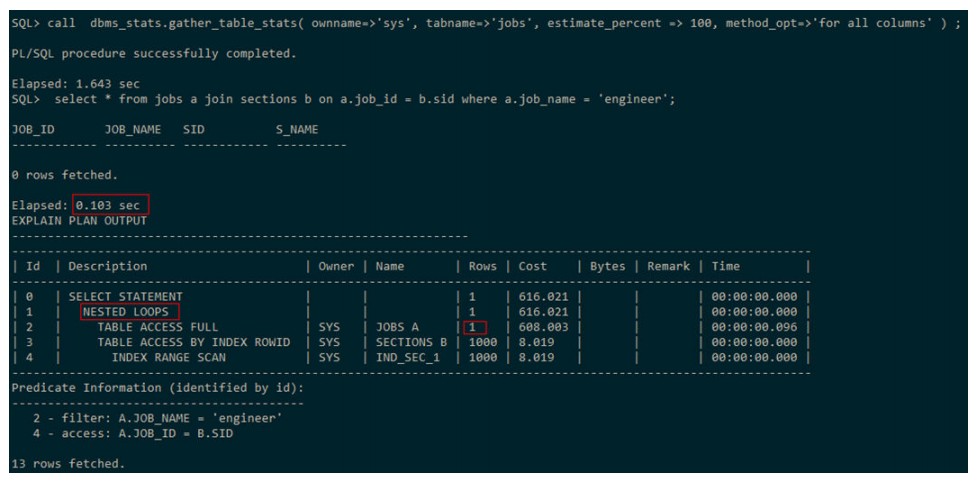
列的直方图信息可以通过查看视图MY_HISTOGRAMS获取:
SELECT COLUMN_NAME, ENDPOINT_NUMBER, ENDPOINT_VALUE, ENDPOINT_ACTUAL_VALUE FROM
MY_HISTOGRAMS WHERE TABLE_NAME = 'JOBS' AND COLUMN_NAME = 'JOB_NAME';
COLUMN_NAME ENDPOINT_NUMBER ENDPOINT_VALUE ENDPOINT_ACTUAL_VALUE
---------------------------------------------------------------- ----
JOB_NAME 1 1 engineer
JOB_NAME 2 1000001 teacher
2 rows fetched.
其中,列字段含义如下:
● ENDPOINT_NUMBER表示统计划分后的列对应的桶编号(从1开始),
● ENDPOINT_VALUE表示小于对应列值的累积行数,
● ENDPOINT_ACTUAL_VALUE表示统计划分后的列值。
可以看出,JOB_NAME列划分了两个桶,第一个桶的列值是engineer,第二个的列值是teacher。列值小于engineer的只有一条记录,而小于列值teacher的累计行数有1000001条。
