优化执行计划
执行计划的好坏取决于优化器所采用的数据访问方式和数据处理的方式决定,例如表
数据的访问方式和表间关联方式;
1. CBO
CBO优化SQL的手段, 首选是Hint方式, 无论数据怎么变化统计信息怎么变化, 加Hint的
方式得到的执行计划是最稳定的, 而且不会对其他SQL有任何影响。其次是DBMS_STATS高级包采用高采样率收集统计信息,提高统计信息正确率, 并期望CBO能借助正确的统计信息得到正确的执行计划,最后一种方式是使用DBMS_STATS高级包方式手工修改统计信息来生成期待的执行计划;
● 使用hint方式(参考RBO Hint使用方式)
CBO一旦使用hint就完全按照RBO来生成执行计划,因此可以在CBO生成初始执行计划的基础上,精准使用hint来调整执行计划。
● 调整统计信息采样率
如果使用指定采样率来收集统计信息,很可能统计信息与实际值相差较大,这种情况下可以使用统计信息收集高级包(DBMS_STATS),指定高采样率来收集统计信息,比如采样率从原来的10%提高到30%甚至更高;
CALL DBMS_STATS.GATHER_TABLE_STATS(
ownname=> 'sys',
tabname=>'sections',
estimate_percent=>100,
method_opt=>'for all columns'
)
● 手工设置统计信息
提高采样率能提高统计信息准确率,但是会消耗额外的系统资源(IO、CPU),在资源受限情况下,可以考虑手工设置准确统计信息,目前统计信息高级包提供手工修改字段,索引,表统计信息系统表数据;注意使用手工设置统计信息方式会锁定统计信息,这样一来无论后续数据怎样变化 ,统计信息都不会变更;
– DBMS_STATS.SET_TABLE_STATS(设置表统计信息)
--强制设置表统计信息。
DBMS_STATS.SET_TABLE_STATS (
ownname VARCHAR2,
tabname VARCHAR2,
partname VARCHAR2 DEFAULT NULL,
stattab VARCHAR2 DEFAULT NULL,
statid VARCHAR2 DEFAULT NULL,
numrows NUMBER DEFAULT NULL,
numblks NUMBER DEFAULT NULL,
avgrlen NUMBER DEFAULT NULL,
flgä NUMBER DEFAULT NULL,
statown VARCHAR2 DEFAULT NULL,
no_invalidate BOOLEAN DEFAULT NULL,
cachedblk NUMBER DEFAULT NULL,
cachehit NUMBER DEFUALT NULL,
force BOOLEAN DEFAULT FALSE
);
▪ numrows:行数。
▪ numblks: 块数。
▪ avgrlen:行平均长度。
– DBMS_STATS.SET_INDEX_STATS(设置索引统计信息)
--强制设置索引统计信息。
DBMS_STATS.SET_INDEX_STATS (
ownname VARCHAR2,
indname VARCHAR2,
partname VARCHAR2 DEFAULT NULL,
stattab VARCHAR2 DEFAULT NULL,
statid VARCHAR2 DEFAULT NULL,
numrows NUMBER DEFAULT NULL,
numlblks NUMBER DEFAULT NULL,
numdist NUMBER DEFAULT NULL,
avglblk NUMBER DEFAULT NULL,
avgdblk NUMBER DEFAULT NULL,
clstfct NUMBER DEFAULT NULL,
indlevel NUMBER DEFAULT NULL,
combndv2 NUMBER DEFAULT NULL,
combndv3 NUMBER DEFAULT NULL,
combndv4 NUMBER DEFAULT NULL,
flgä NUMBER DEFAULT NULL,
statown VARCHAR2 DEFAULT NULL,
no_invalidate BOOLEAN DEFAULT NULL,
guessq NUMBER DEFAULT NULL,
cachedblk NUMBER DEFAULT NULL,
cachehit NUMBER DEFUALT NULL,
force BOOLEAN DEFAULT FALSE
);
▪ ownname:用户名。
▪ indname: 索引名。
▪ partname: 分区名。
▪ numrows:行数量。
▪ numblks:块数量。
▪ numdist: 唯一值。
▪ avglblk:每个叶子块的平均key。
▪ avgdblk:每个数据块的平均key。
▪ clstfct:索引聚集因子。
▪ indlevel:索引高度。
▪ combndv2:组合索引2字段ndv 。
▪ combndv3:组合索引3字段ndv。
▪ combndv4:组合索引4字段ndv 。
– DBMS_STATS.SET_COLUMN_STATS(设置列统计信息)
--强制设置列统计信息。
DBMS_STATS.SET_COLUMN_STATS (
ownname VARCHAR2,
tabname VARCHAR2,
colname VARCHAR2,
partname VARCHAR2 DEFAULT NULL,
stattab VARCHAR2 DEFAULT NULL,
statid VARCHAR2 DEFAULT NULL,
distcnt NUMBER DEFAULT NULL,
density NUMBER DEFAULT NULL,
nullcnt NUMBER DEFAULT NULL,
srec STATREC DEFAULT NULL,
avgclen NUMBER DEFAULT NULL,
flgä NUMBER DEFAULT NULL,
statown VARCHAR2 DEFAULT NULL,
no_invalidate BOOLEAN DEFAULT NULL,
force BOOLEAN DEFAULT FALSE
);
▪ ownname:用户名。
▪ tabname: 表名。
▪ colname:列名。
▪ partname: 分区名(分区表)。
▪ distcnt:唯一值,必选参数。
▪ density:密度,必选参数。
▪ nullcnt:null值的数量,必选参数。
▪ srec:用户定义的直方图,预留参数。
▪ avgclen:列的平均长度,预留参数。
▪ force:是否强制设置统计信息,必选参数。
2. RBO
● 表扫描方式
GaussDB T支持的表扫描方式有:全表扫描、索引扫描,索引扫描又分为index range scan、index unique scan等。在某些场景下,优化器根据规则选择的索引不是很好,扫描性能不如全表扫描好,这个时候需要手动干预执行计划选择。举例如下:
select * from person where city = 'nanjing'
执行计划如下:
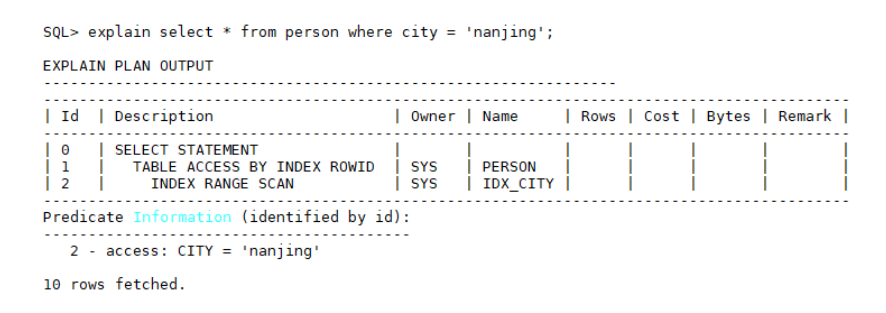
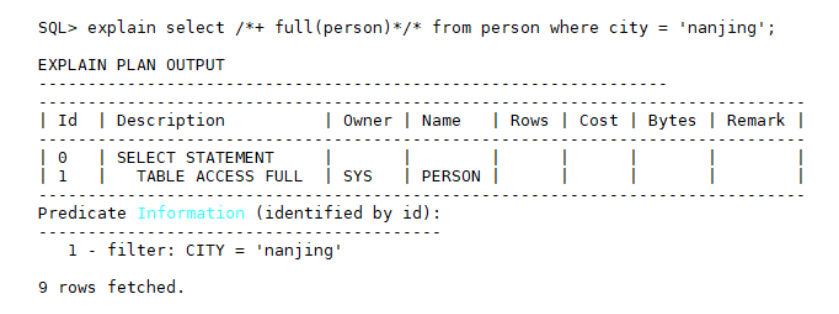
如果city字段重复值非常多的话,idx_city索引等同于失效,而且还多一次根据rowid从表中取数据的IO操作,性能较低,此时可以使用hint人为干预执行计划,让优化器选择全表扫描,语法格式和示例如下:
-- hint语法
/*+ full(person)*/
● 扫描索引选择
表中存在多个索引的场景,优化器会根据where条件选择扫描代价最小的索引,如果多个索引代价相同的话,优化器默认选择第一个创建的索引。某些场景下,优化器根据规则选择的索引并不是最优索引,需要手动指示优化器选择某个具体索引,举例如下:
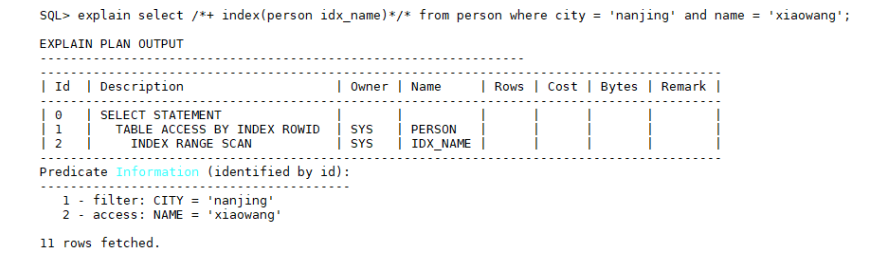
select * from person where city = 'nanjing' and name = 'xiaowang';
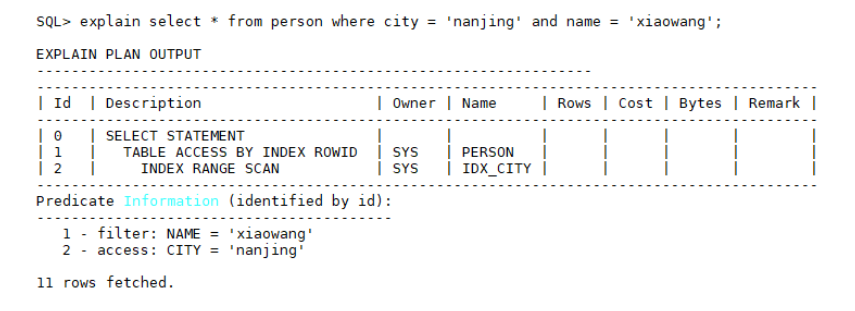
person表上有idx_city和idx_name两个索引,而优化器根据规则选择了idx_city索引,由于city字段重复度大大高于name字段,导致索引扫描效率较低,可以使用hint人为调整扫描索引,指示优化器选择idx_name索引扫描,语法格式和示例如下:
/*+ index(person idx_name)*/
或者调整SQL语句,在idx_city索引的首字段city上添加辅助信息(数值型字段+0,字符型||’’,此例:city||’’),把idx_city索引屏蔽掉:

● 多表关联驱动表选择
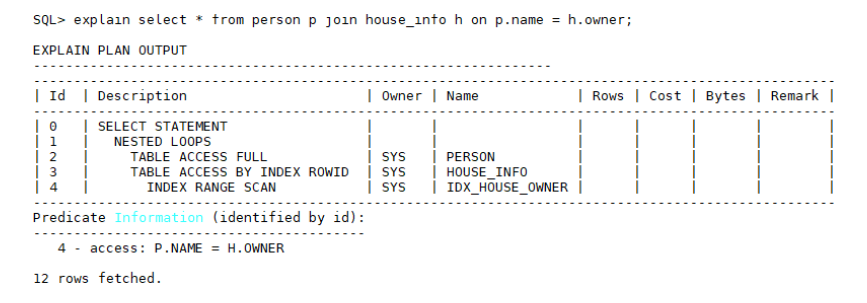
多表关联的查询语句中,如果驱动表(驱动表概念参见执行计划解读章节)选择不是最优的话,将会直接影响整个语句的执行性能。通常情况下,优化器会根据where条件选择索引扫描代价最小的表作为驱动表,如果SQL语句没有where条件,或者是根据where条件不能选择索引的话,默认选择第一张表作为驱动表,如果选择的驱动表是个大表的话,则需要手动调整驱动表,例如:select * from person p join house_info h on p.name = h.owner,执行计划如下:
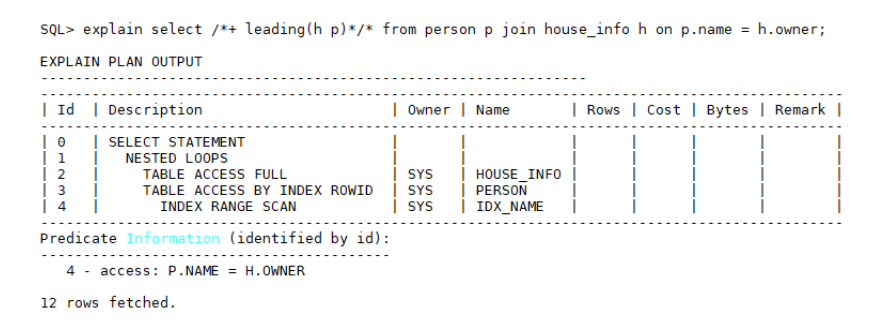
person是大表的情况下,全表扫描代价非常大,再与house_info表关联则性能很低,如果出现这种场景,需要手动选择house_info表作为驱动表,驱动person关联查询,语法:/+ leading(h p)/(表有别名时必须写别名,否则写实际表名),执行计划:
● 多表关联连接算法选择
GaussDB T当前支持的连接算法有:Nest Loop、Hash Join、Merge Join等,
– Nest Loop:主要用于右表能通过关联条件选择索引扫描的场景。
– Hash Join:主要用于右表不能通过关联条件选择索引,并且有等值关联条件的场景。
– Merge Join:主要用于右表不能通过关联条件选择索引,并且没有等值关联条件的场景。
某些场景下,优化器根据关联条件选择的索引字段重复度非常高,或者关联条件只匹配了索引的部分字段,如果此时驱动表与右表选择Nest Loop Join时,则计算代价非常大,极限情况下与笛卡尔积等价,遇到这种场景时,需要通过hint指示优化器选择Hash Join,例如:
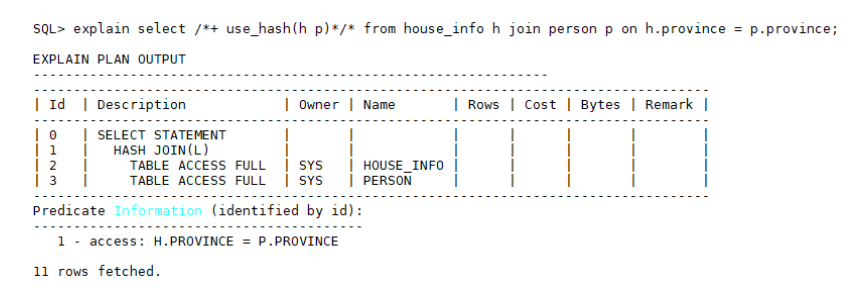
select * from house_info h join person p on h.province = p.province;
执行计划如下:
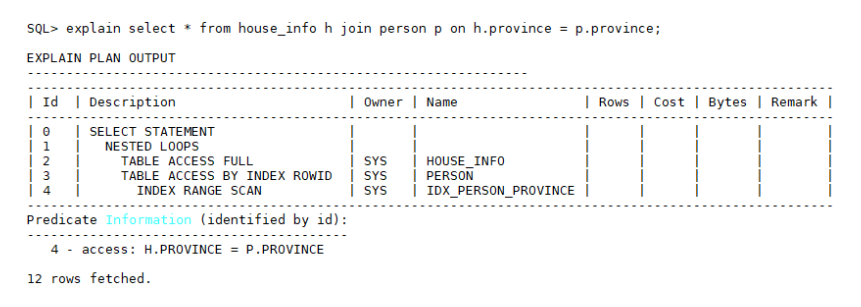
Nest Loop计算代价=house_info记录数 * person表province字段重复度,如果province字段重复度越大,则NL计算代价越大,极限情况下,NL计算代价等价于house_info记录数 * person记录数。手动指示优化器选择Hash Join的语法:
/*+ use_hash(h p)*/
执行计划如下:
● HASH MATERIALIZE执行计划优化
出现在表达式中的子查询,如果存在与外表等值关联的条件,并且子查询只需要聚集函数值的场景时,优化器会根据外表关联的条件选择索引,如果能选择到索引并且索引满足既定规则时,子查询不做此优化,继续放在KERNEL FILTER计划中执行,,反之会选择HASH MATERIALIZE执行计划。例如:
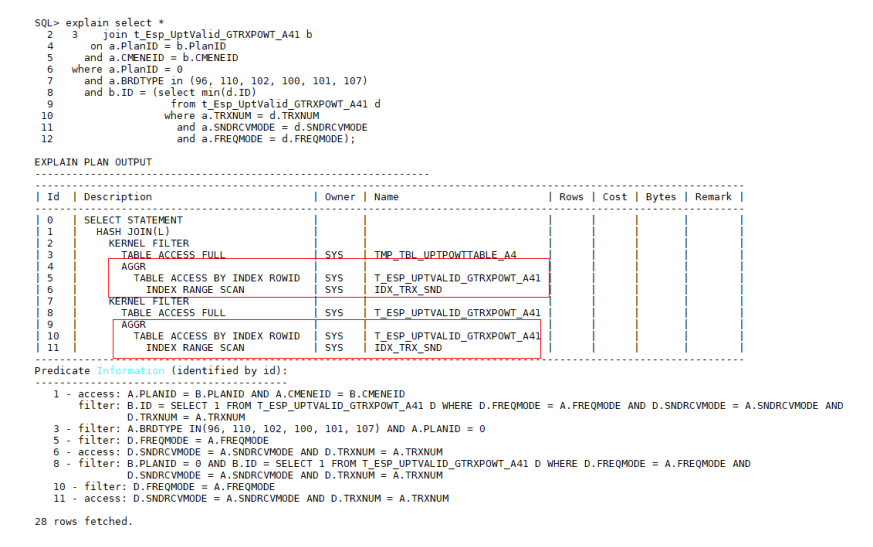
如果索引IDX_TRX_SND对应字段(TRXNUM,SNDRCVMODE)重复度非常高的话,则这不是最优的执行计划,需要手动修改SQL语句,尽量让执行计划不要选择该索引。屏蔽一个索引有两种方法:
– 使用Hint,语法如下,此方法只适用于RBO场景。
/*+ no_index( d idx_TRX_SND) *//*+ no_index( d idx_TRX_SND) *//*+ no_index( d idx_TRX_SND) */
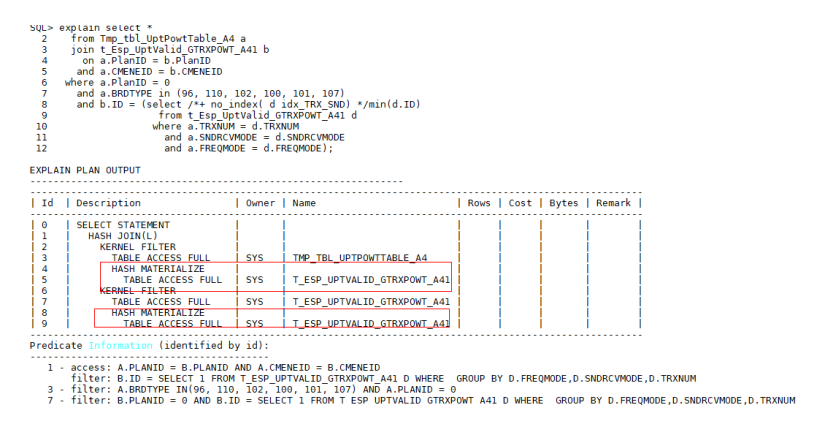
– 索引首字段添加辅助信息(数值类型+0,字符类型||’’),对于此例
a.TRXNUM = d.TRXNUM+0即可,该方法通用。
修改后的SQL语句执行计划如下:
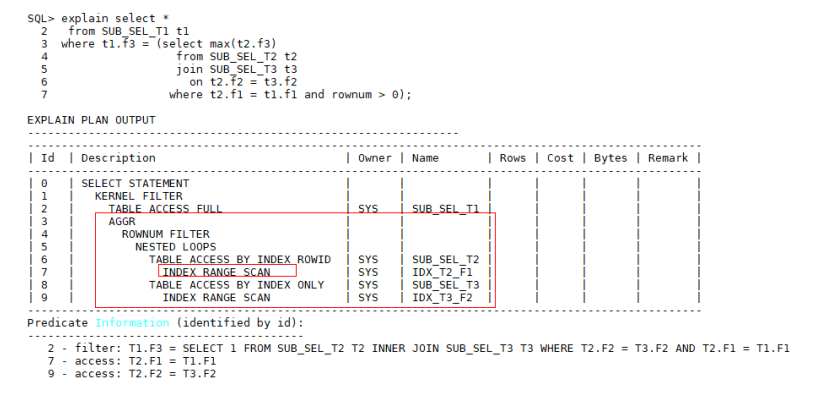
对于某些场景,例如CBO统计信息不准确导致应该走索引扫描,而实际选择了HASH MATERIALIZE,或者子查询中有多表关联,满足规则选择了HASH MATERIALIZE后,经分析子查询中表数据过大,不适合此执行计划,需要手动干预,指示优化器不要选择HASH MATERIALIZE优化,继续使用原始子查询执行计划,我们可以调整SQL语句,在子查询where条件中添加rownum >0(添加该条件不会影响查询结果集),这是GaussDB T调优手段之一。例如:
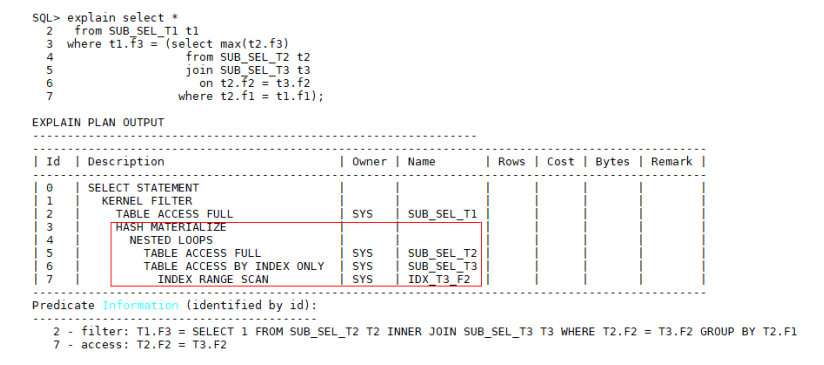
驱动表T2如果能通过外表关联条件t2.f1 = t1.f1走索引,T3表通过关联条件
t2.f2 = t3.f2 走索引,并且两个表索引的重复度很好的话,T2、T3走Nest Loop性能要高于HASH MATERIALIZE性能,此时按照上述方法添加rownum > 0,修改后SQL语句执行计划如下: