






1. Full GC次数过多
多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程。
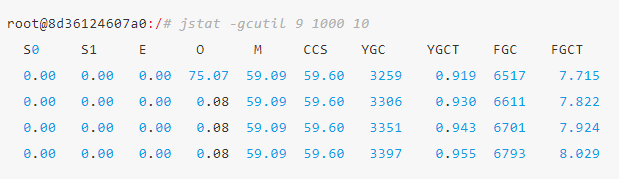
通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。
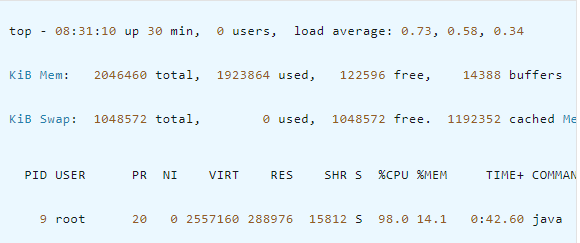
9的Java程序此时CPU占用量达到了98.8%,查看该进程的各个线程运行情况:
top -Hp 9

10的线程为什么耗费CPU最高。
root@a39de7e7934b:/# printf "%x\n" 10a
0xa,通过jstack命令我们可以看到如下信息:
"main" #1 prio=5 os_prio=0 tid=0x00007f8718009800 nid=0xb runnable [0x00007f871fe41000]
java.lang.Thread.State: RUNNABLE
at com.aibaobei.chapter2.eg2.UserDemo.main(UserDemo.java:9)
"VM Thread" os_prio=0 tid=0x00007f871806e000 nid=0xa runnable
nid=0xa,这里nid的意思就是操作系统线程id的意思。而VM Thread指的就是垃圾回收的线程。
System.gc()调用。
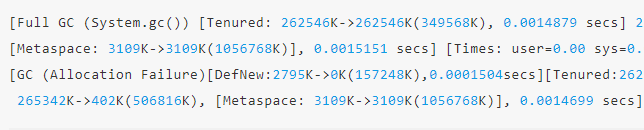
System.gc()的显示调用导致的,而第二次GC则是JVM主动发起的。总结来说,对于Full GC次数过多,主要有以下两种原因:
代码中一次获取了大量的对象,导致内存溢出,此时可以通过eclipse的mat工具查看内存中有哪些对象比较多;
内存占用不高,但是Full GC次数还是比较多,此时可能是显示的 System.gc()调用导致GC次数过多,这可以通过添加 -XX:+DisableExplicitGC来禁用JVM对显示GC的响应。
2. CPU过高
top命令查看当前CPU消耗过高的进程是哪个,从而得到进程id;然后通过
top-Hp来查看该进程中有哪些线程CPU过高,一般超过80%就是比较高的,这样我们就能得到CPU消耗比较高的线程id。
线程id的十六进制表示在
jstack日志中查看当前线程具体的堆栈信息。
jstack得到的线程信息会是类似于VM Thread之类的线程,而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。
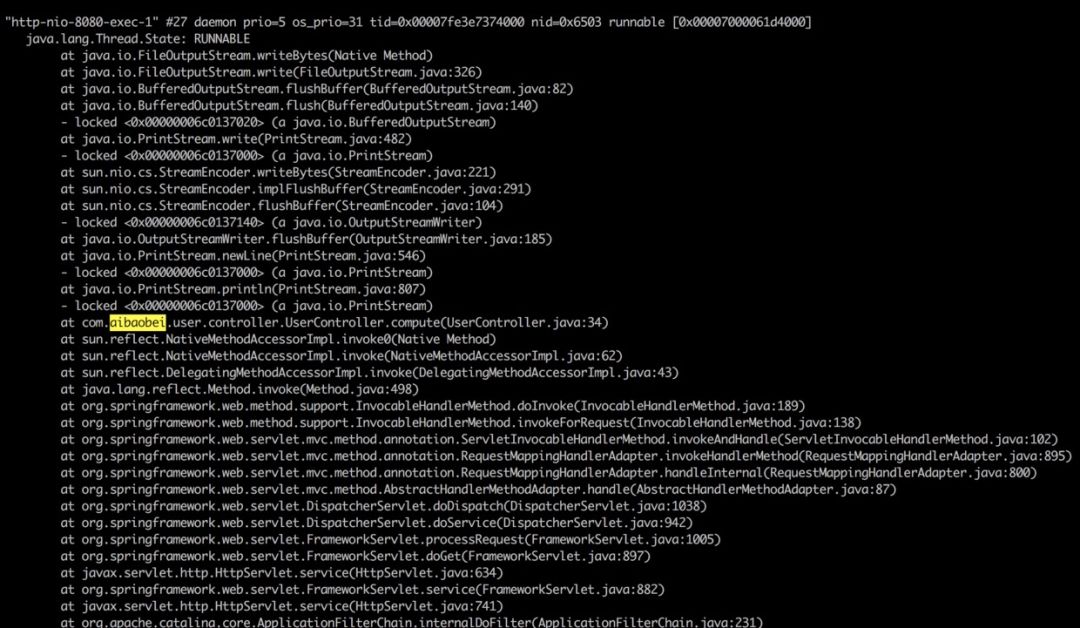
3. 不定期出现的接口耗时现象

4. 某个线程进入WAITING状态
TIMED_WAITING状态,而我们这里出问题的线程所处的状态与其是一模一样的,这就非常容易混淆我们的判断。
通过grep在jstack日志中找出所有的处于 TIMED_WAITING状态的线程,将其导出到某个文件中,如a1.log
等待一段时间之后,比如10s,再次对jstack日志进行grep,将其导出到另一个文件,如a2.log
重复步骤2,待导出3~4个文件之后,我们对导出的文件进行对比,找出其中在这几个文件中一直都存在的用户线程,这个线程基本上就可以确认是包含了处于等待状态有问题的线程。
经过排查得到这些线程之后,我们可以继续对其堆栈信息进行排查,如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
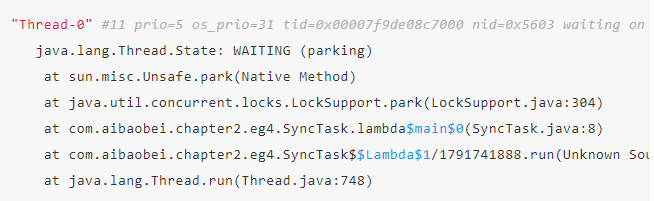
Thread-0,以及我们可以辨别的自定义线程名,这些都是我们需要排查的对象。
Thread-0就是我们要找的线程,通过查看其堆栈信息,我们就可以得到具体是在哪个位置导致其处于等待状态了。
5. 死锁
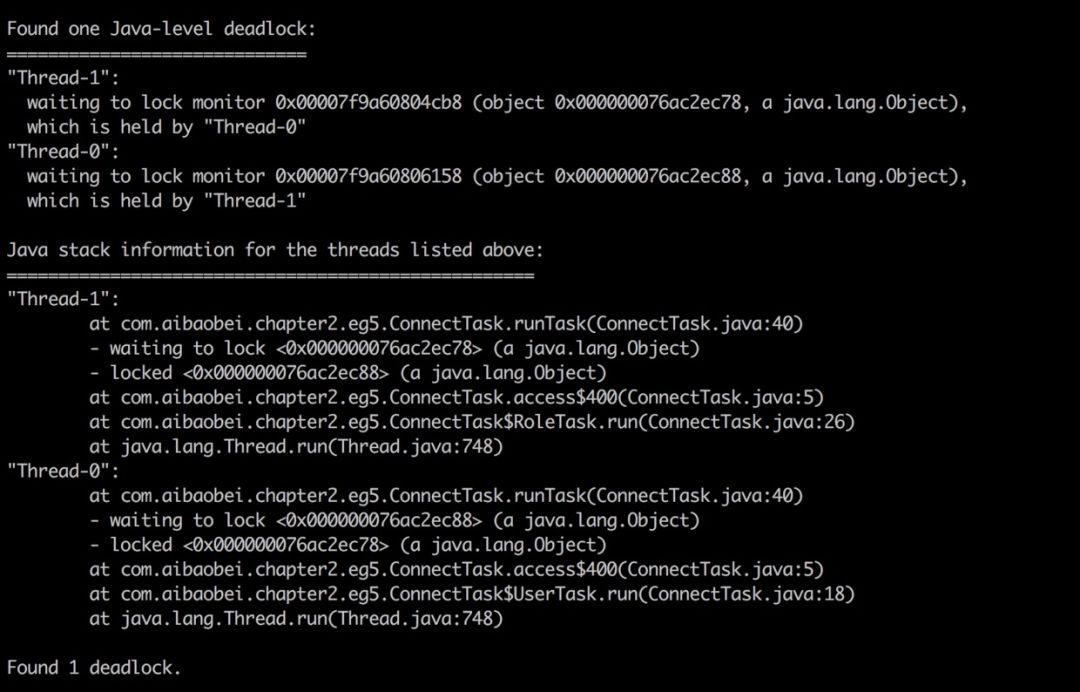
jstack可以帮助我们检查死锁,并且在日志中打印具体的死锁线程信息。
jstack日志示例:

来源: https://my.oschina.net/zhangxufeng/blog/3017521 觉得本文有用,请转发、点赞或点击“在看” 聚焦技术与人文,分享干货,共同成长 更多内容请关注“数据与人”

