知识自动化领域是目前人工智能领域增长比较快的一个应用领域,以知识管理、知识图谱、知识推理为核心的知识自动化领域是以图数据库为核心进行基础分析与应用的技术领域。老白今天和大家探讨的运维知识自动化虽然也属于知识自动化这个大的领域,不过其技术实现方式和前者有所不同。
运维知识以前都是以文本的方式得以保存与积累,方案、预案、脚本等都是很好的运维知识保存与传承的方式。一个做运维服务的企业的最为核心的价值除了那些国宝级的专家高手之外,就是这些文档了。这些文档可能在公司的一个核心代码库中保存,不过在很多企业里,很多具有核心价值的文档甚至没有存放在企业的代码库中,而是在某些专家的电脑里,甚至只存在于这些专家的脑子里。
除了较难收集保存外,核心的运维知识还有一个不便于使用的就是难于查找与使用。如果我们要找一个小技巧用于生产,如果给我几百份总计上千页的文档,那么我很可能会放弃。于是乎,在业内有了百事不决问度娘的习惯。实际上度娘不一定靠谱,甚至有害。在这种情况下,知识图谱就能发挥比较好的作用了。对这些文本形式的知识,通过知识图谱建立模型,可以通过语义分析,将一篇文章分解为N多个知识点,再配合以全文检索引擎,就可以形成一个专业搜索工具。在我们拥有较为专业的字典库的情况下,专业搜索工具的搜索准确性还是可以保证的。在知识检索领域,最为著名的,也代表了当前最高水平的是Oracle公司的Metalink,现在已经改名叫MOS了。
不过仅仅能够搜索知识还是不够用的,实际上,从搜索到知识,到应用到我们的生产环境,还有很大的鸿沟。对高水平的技术人员来说,Mos是一个宝库,而对于一些小白来说,MOS上的文章和天书无异,从Mos找到有效的资料更为困难。事实上,只有具有一定水平的人员才能很好的利用这些知识去直接在日常工作中应用。
在2018年初的一次知识自动化工作研讨会上,老白有幸和来自北京大学、浙江大学、东南大学的这个领域的专家学者共聚一堂,探讨知识自动化应用的一些成功实践。特别是中科院自动化所的虎松林老师介绍的利用知识图谱解决舆情分析的问题,特别是他提到的通过他们的算法,让本来2000人的工作减少到1000人来完成的时候,特别强调,认为算法能够解决所有舆情管控自动化问题的想法是不现实的,他们的工作,已经算是国内最为领先的了。
老白在会上分享了智能标签在运维知识自动化工作中的应用的案例,虎老师也十分感兴趣,虽然说这个案例是与本次大会的其他分享最为格格不入的,其他的大多数论题都是以自动化手段,知识推理算法来解决实际问题的,而我这个分享的方法的核心还是专家知识梳理。在和虎老师的交流中,他十分肯定我们的做法,在很多领域,算法还无法发挥核心作用,能发挥多大多用就发挥多大作用。在短期内,算法无法解决知识点的自动生成问题,顶多能够实现的是诊断路径的自动或者半自动发现。那次研讨会后,坚定了老白对运维知识自动化系统建设的思路-继续以专家知识梳理与运维一线积累为核心,走知识工具化的道路,而放弃了一直想走的那条高大上的以知识推理与深度学习为核心的知识发现的道路。
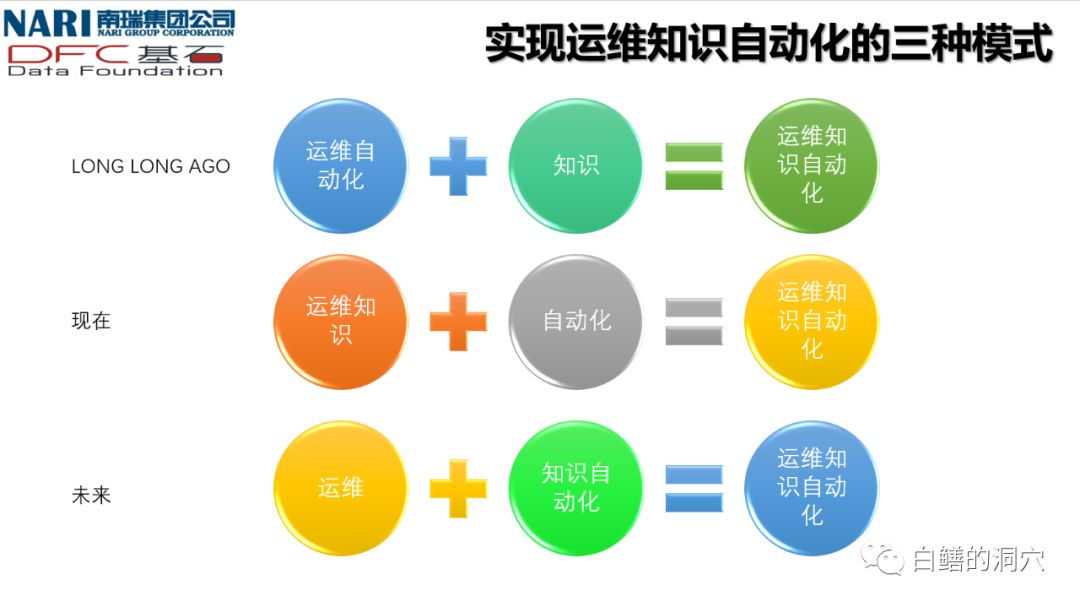
很早以前,老白在接触运维自动化的时候,运维自动化工具本身是不包含很深的运维知识的,而只是提供了一个工具给你,可以帮你采集指标,显示指标,你可以用它去设定基线与报警规则,当某个指标出现问题的时候进行报警,然后,由运维人员根据告警情况去做出判断与相关的处置。实际上,为了解决运维中的问题所建立的智能系统的基本想法是一直存在的。从二十年前兴起的基于网管思路的欲望自动化平台(比如OPENVIEW,BMC PORTAL等)。我们把运维知识自动化的实现模式分为三种。
第一种是从20多年前网管平台开始就贯彻的一种建设思路,首先建立一个运维自动化平台,然后向这个平台中灌输知识,加入各种监控指标,加入基线进行监控与预警,同时提供大量的工具,用于辅助运维工作。
经过十多年的发展,随着我们所运维的系统越来越复杂,这种模式的运维自动化系统对运维的支撑能力越来越不足。于是在近些年出现了大量的将运维知识进行自动化工作的尝试,情景式运维、众包式运维等创新层出不穷。
随着大数据与人工智能技术的发展,知识智能从以前的遥不可及的未来变得越来越清晰可见了。于是大家又开始了一种全新的尝试,首先建立一套知识自动化体系,然后将运维知识构建到知识自动化系统中去,从而让专家的运维知识能够变成一个自动化工具去协助我们工作。
在构建运维知识自动化体系的工作中,构建最为基础的平台是不难的,传统的运维自动化工具,开源的工具都可以作为构建的基础平台,最难的还是知识的积累,这种积累不是简单的对某个指标的分析,而是一整套的体系。对于一个运维知识自动化系统来说,建设过程中最难的部分是积累运维知识。对于一些十分复杂的系统,比如Oracle数据库,某个异常所需的诊断是十分复杂的。下面我们看一个例子:
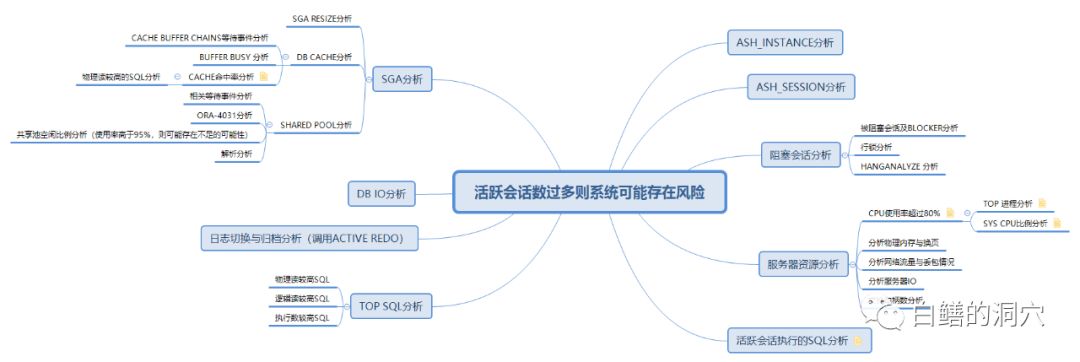
通过专家梳理知识点,梳理诊断路径的方法也是十分困难的,因为我们面临的运维环境十分复杂,仅仅依靠少量的几个专家完成复杂的运维经验梳理所需要的时间是十分长的。不过换一种思路去考虑这个问题。虽然一个运维知识有那么复杂的诊断路径,但是到了某个具体的用户的环境中,情况就简单多了,他们经常出现的问题往往是其中几条路径引起的,如果有几百上千个用户都在自己的环境中不断的积累运维经验,将这些经验汇总起来,再由一个团队对这些经验进行综合汇总,那么采用这种云共享的方式,我们就可以逐渐积累完善。从而形成下面的云协作生态,共同实现运维知识自动化的工作。
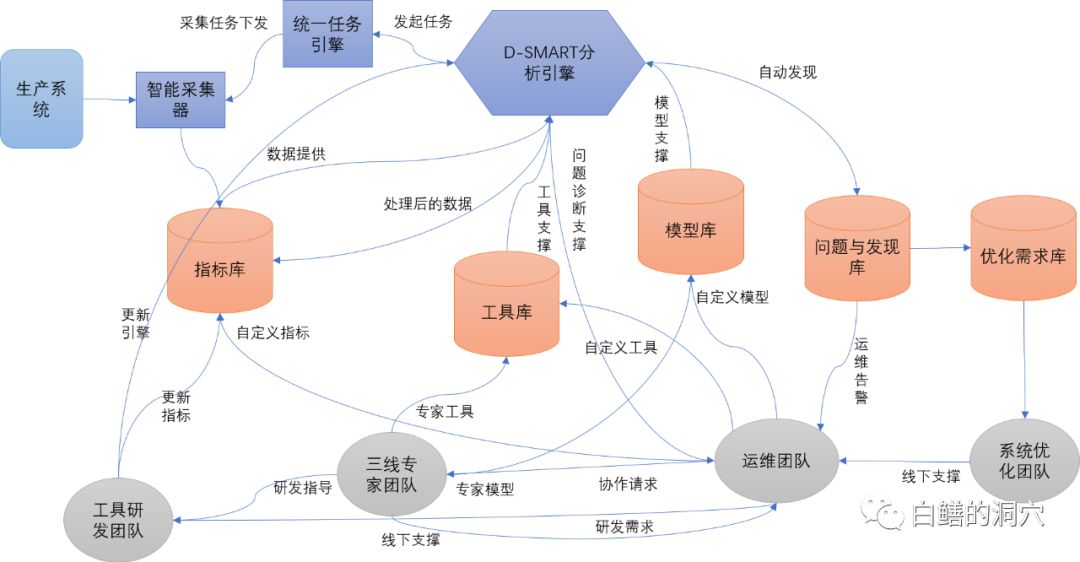
经过2018/2019年在国家电网、政府部门、医疗、金融等行业的综合实践,基于这种模式的运维知识自动化系统的构建工作已经走上了平稳发展的道路。支撑的数据库系统已经超过1000套,支持的数据库种类也从最初的Oracle数据库发展到Oracle、Mysql、PostgreSQL、达梦、Gaussdb、MongoDB等。甚至已经开始支持Weblogic、网络交换机、存储设备等非数据库的运维对象。
下一步,希望更多的朋友能够加入到这个工作中来,建立起真正的广泛参与,广泛共享的运维知识自动化体系。





