




导读:
作者:高鹏(网名八怪),《深入理解MySQL主从原理32讲》系列文的作者。

binlog文件作为一次写入,会在sync阶段消耗大量的IO,会导致全库hang主,状态大多为query end。
大事务会造成导致主从延迟。
大事务可能导致某些需要备份挂起,原因在于flush table with read lock,拿不到MDL GLOBAL 级别的锁,等待状态为 Waiting for global read lock。
大事务可能导致更大Innodb row锁加锁范围,导致row锁等待问题。
回滚困难。
基于如上一些不完全的列举,我们应该在线上尽可能的避免大事务。好了我们下面来进行问题讨论。
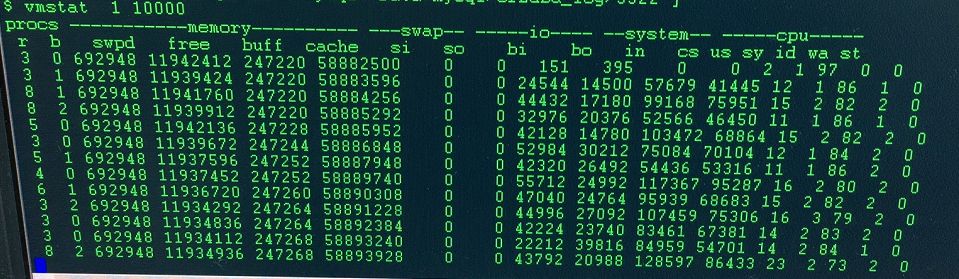
vmstat 截图
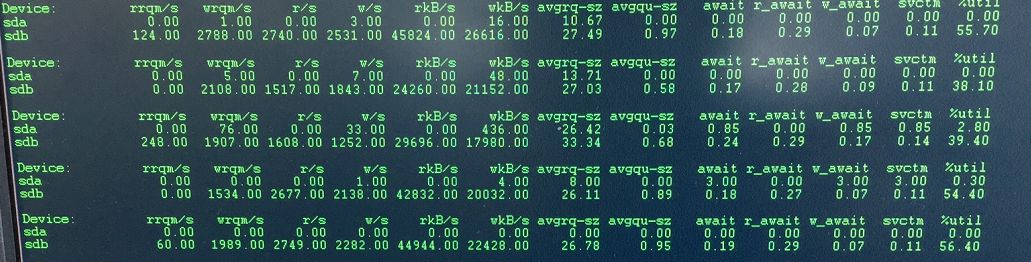
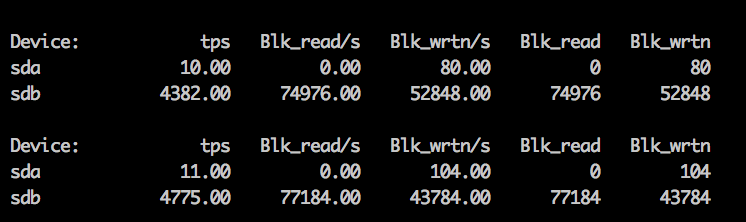
iostat 截图
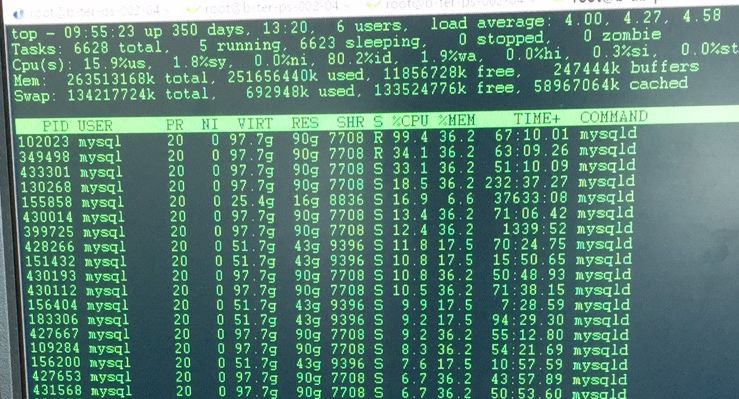
top -Hu截图


PrintNotStarted print_not_started(file);//建立一个结构体,目的是做not start 事务的打印
ut_list_map(trx_sys->mysql_trx_list, print_not_started); //这个地方打印出那些事务状态是no start的事务。mysql_trx_list是全事务。
const trx_t* trx;
TrxListIterator trx_iter; //这个迭代器是trx_sys->rw_trx_list 这个链表的迭代器
const trx_t* prev_trx = 0;
/* Control whether a block should be fetched from the buffer pool. */
bool load_block = true;
bool monitor = srv_print_innodb_lock_monitor && (srv_show_locks_held != 0);
while ((trx = trx_iter.current()) != 0) { //通过迭代器进行迭代 ,显然这里不会有只读事务的信息,全部是读写事务。
...
/* If we need to print the locked record contents then we
need to fetch the containing block from the buffer pool. */
if (monitor) {
/* Print the locks owned by the current transaction. */
TrxLockIterator& lock_iter = trx_iter.lock_iter();
if (!lock_trx_print_locks( //打印出锁的详细信息
file, trx, lock_iter, load_block))
5.7.26
实际上只有如下一句话:
return(trx_lock->n_rec_locks);
5.6.22
随后我翻了一下5.6.22的代码,发现完全不同如下:
for (lock = UT_LIST_GET_FIRST(trx_lock->trx_locks); //使用for循环每个获取的锁结构
lock != NULL;
lock = UT_LIST_GET_NEXT(trx_locks, lock)) {
if (lock_get_type_low(lock) == LOCK_REC) { //过滤为行锁
ulint n_bit;
ulint n_bits = lock_rec_get_n_bits(lock);
for (n_bit = 0; n_bit < n_bits; n_bit++) {//开始循环每一个锁结构的每一个bit位进行统计
if (lock_rec_get_nth_bit(lock, n_bit)) {
n_records++;
}
}
}
}
return(n_records);
MySQL 5.6版本
有大事务的存在,大概100G左右的数据加行锁了
使用了show engine innodb status
这样当在统计这个大事务行锁个数的时候,就会进行大量的循环操作。从现象上看就是线程消耗了大量的CPU资源,并且处于perf top的第一位。
From perf top, function locknumberofrowslocked may occupy more than 20% of CPU sometimes
也就是CPU消耗会高达20%。

END
识别下方二维码添加作者为好友


另外,叶老师在腾讯课堂的短课程《MySQL性能优化》已于昨晚开课,本课程讲解读几个MySQL性能优化的核心要素:合理利用索引,降低锁影响,提高事务并发度。
目前已有几个录播视频,并且可以回看5-15分钟不等。

下面是报名小程序码



