




下班刚到家,用户在微信群里反馈监控文件上传异常,缺失了文件,火急开电脑连上服务器去查看,寻思着上午刚安排人巡检完,怎么下班就出问题了。
连上服务器之后
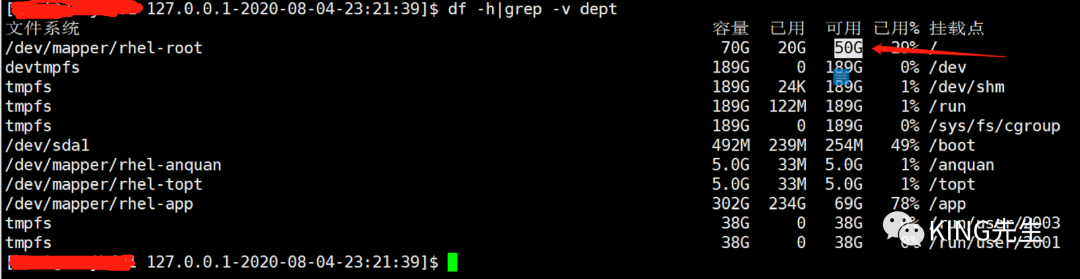
df -h 查看发现root根目录分区空间使用率已经100%;
立刻停止了应用程序;
进入tmp里面删除了一些没用的临时文件;
再次df -h 查看,目录使用已经变成了98%,虽然较高,但是服务器可以正常运行,监控文件可以正常生成了;
将缺失的监控文件补上,最紧急的问题已经搞定,接下来是查到核心的问题根源,彻底解决问题;
统计下根目录下大小上G的文件目录
su - root
cd / du -sh * |grep G 发现/var 目录占了50G空间,与平时相比相当异常; 进一步进入分析 cd /var du -sh * |grep G 发现50G空间全部为/var/crash目录占用 在一步进去 发现3月25号与8月4号目录各占了20G与29G空间,到此为止算是找到了空间爆满的初步原因。 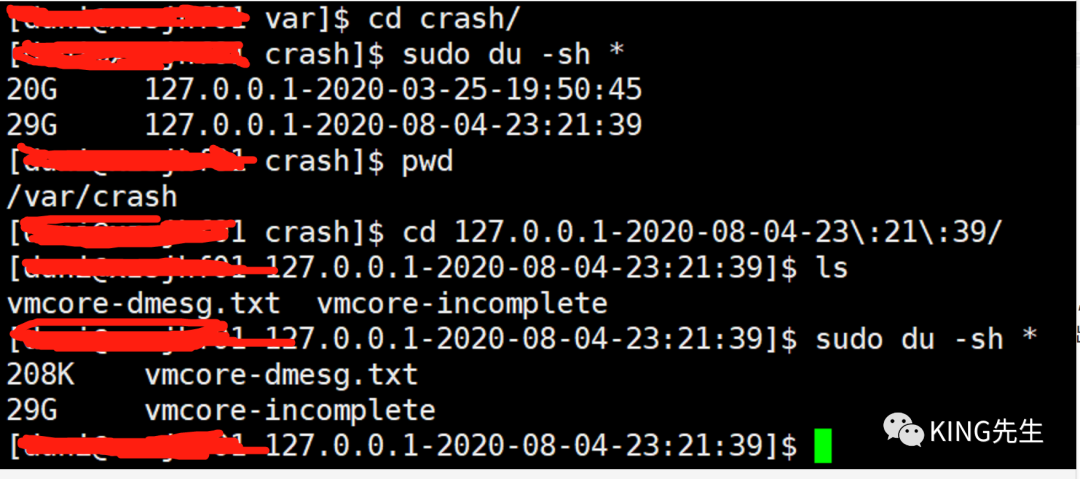
虽然知道了空间是哪里满了,但是还是不知道原因,进一步查看vmcore-dmesg.txt文件
tail -100f vmcore-dmesg.txt
发现日志如下:
kernel panic - not syncing: machine check from unknown source
网上搜了下,这种情况一般是操作系统硬件或者软件故障导致操作系统崩溃的日志记录,crash目录里面的大文件也是服务器崩溃的时候产生的主要是提供给系统管理员分析系统崩溃原因用的。本人也不是系统维护人员,对于操作系统也是半桶水,于是让用户协调主机人员做了进一步分析,最后反馈是内存硬件故障,导致操作系统崩溃自动重启。
经过协商,决定先删除/var/crash目录下两个大的日志文件,再协调时间关机更换服务器内存。
总结:人工巡检已经不能满足业务需求,必须实现自动化巡检与监控,问题提前发现处理,从而避免成为救火队长。
文章转载自KING先生,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
