




背景:写这篇文章的前提是,近两个月来,接连有几个应用报生产commit缓慢问题,他们都有一些共同点,就是数据库版本均为Oracle 19.5,运行在Linux x86平台,系统的负载均很低,log file sync平均等待时间很高,有的高达几秒,但log file parallel write平均等待时间不到1毫秒,而在lms、lgwr日志却能看到大量的log writ broadcast wait time超过500毫秒的警告信息。该问题是命中Oracle Bug。从官方截取下图,可以看到,这个问题在19.8版本之后已经解决了,19c的其它版本需要打上对应的Patch。本文重点不是探讨这个BUG。
言归正传,平时我们在分析生产或测试环境AWR性能报告时,经常会碰到log file sync这个等待事件。到底什么是log file sync?与commit有什么关系?对我们应用程序有啥影响?导致log file sync平均等待时间长的原因有哪些?怎样去优化这个等待事件?下面将逐一进行说明:
1、什么是log file sync?
当一个会话发起commit时,该会话所产生的所有事务日志,需要从内存中log buffer刷出到磁盘日志文件(redo log file),确保事务对数据库的更改被持久化。大家都清楚,关系型数据库都是日志先行,而且是顺序写入,只要日志落盘成功,那么即使此时实例挂掉,数据也不会丢失。
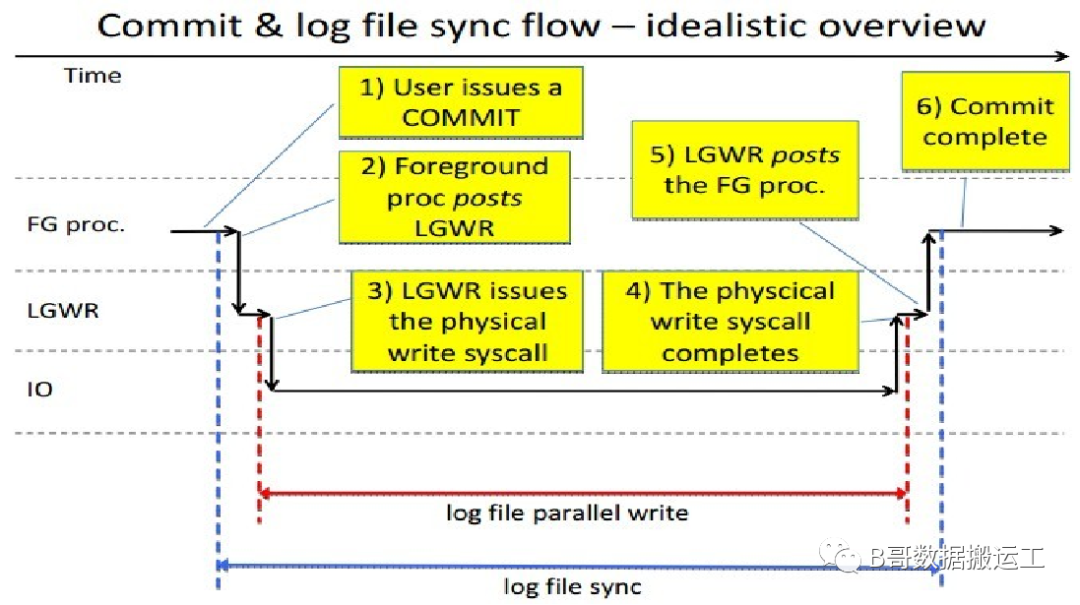
2、log file sync的生命周期
从下图可以看到,log file sync生命周期指的是用户发出commit,直至收到日志已落盘完成,一共经历这6个阶段。如果这个过程等待时间过长,则意味着应用commit响应缓慢。图中,若log file sync(蓝色实线)平均等待时间较长(比如超过15ms),而log file parallel write(红色实线)平均等待时间却小于10ms,则可以初步排除存储IO性能问题。
3、哪些因素导致log file sync高?以及有哪些排查手段?
1)日志文件所在存储设备IO性能较差
通过AWR性能报告分析,确认log file parallel write平均等待是否过高。按目前存储来说,小于10ms可认为是正常。
通过分析lgwr、lms后台进程的trace文件,写入超过500ms,均会记录到trace文件中。
2)出现IO争用
数据文件、日志文件、归档等文件存放在同一块磁盘,导致IO争用。
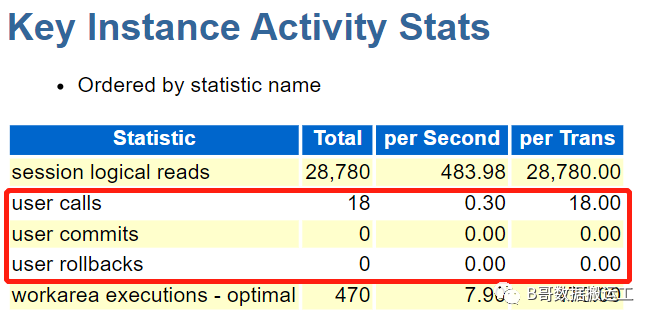
3)commit过于频繁
若user calls / (user commits + user rollbacks) 小于30,可以认为应用程序提交过于频繁。
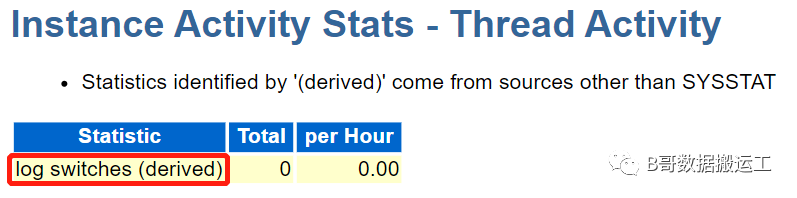
4)日志过多,日志切换过于频繁
检查awr报告中的log switches,每小时切换次数或是直接查看alert.log中日志切换的警告信息
检查日志文件大小
5)CPU出现瓶颈,lgwr,lms关键后台进程没有设置调度高优先级
通过检查数据库_high_priority_processes参数。
6)Oracle Bug
如背景所描述现象。
以下是主要优化参考点:
1)日志文件(redo log)单独存放在IO效率高的存储设备上
2)日志文件大小和组数按照基线规范(OLTP 1GB,OLAP 2GB,共8组,若应用日志量过大,导致日志切不过来,建议增加组数)
3)应用程序采用批量提交
4)打上补丁
