




| 问题:oracle的内存越大越好么? |
| oracle的内存管理机制,是非常复杂且有效的管理机制,可以保障如果非固态盘的的情况下,我们的读写效率也可以非常高效。那么oracle的内存分配是不是越大越好。当然不是绝对的。内存分配的过大,会有关于pagetable、页管理的困扰。而这个需要我们单独设置的。原则上,如果内存大于8G,我们都需要开启linux的大页内存管理。 |
| linux系统内存机制说明: |
| 系统进程是通过虚拟地址访问内存,但是CPU必须把它转换成物理内存地址才能真正访问内存。为了提高这个转换效率,CPU会缓存最近的“虚拟内存地址和物理内存地址”的映射关系,并保存在一个由CPU维护的映射表(page table)中。 page table(页表)是操作系统上的虚拟内存系统的数据结构模型,用于存储虚拟地址与物理地址的对应关系。当我们访问内存时,首先访问"page table",然后Linux再通过"page table"的mapping来访问真实物理内存(RAM或SWAP). 在32位系统下,一个进程访问1GB的内存,会产生1M的页表,如果是在64位系统,将会增大到2M。很容易推算,如果一个SGA设置为60G,有1500个ORACLE用户进程,64位LINUX的系统上,较大的页表占用内存为:60*2*1500/1024=175G 。 为了尽量提高内存的访问速度,需要在映射表中保存尽量多的映射关系。而在Redhat Linux中,内存都是以页(Page)的形式划分的,默认情况下每页是4K Bytes,这就意味着如果物理内存很大,比如64G ,则映射表的条目将会非常多,这将会影响CPU的检索效率(CPU需要转化虚拟地址为物理地址)。而且根据上面的推算,页表会占用比物理内存还多的内存大小。 因内存大小是固定的,为了减少映射表的条目,可采取的办法只有增加页的尺寸。这种增大的内存页尺寸在Linux 2.1中,称为Big page;在AS 3/4或后续版本中,称为Hugepage。如果系统有大量的物理内存(大于8G),则无论32位的操作系统还是64位的,都应该使用Hugepage。 |
| HugePage 查看和解释 |
| Linux中,可以通过如下命令来查看HugePage相关的值:$ cat /proc/meminfo | grep HugeHugePages_Total: 0 ----------Hugepage的页面数量HugePages_Free: 0 ----------剩余的页面数量HugePages_Rsvd: 0 ---------被分配预留但是还没有使用的page数目Hugepagesize: 2048 KB ---------每单位数量大小 通常情况下,Linux hugepage大小为2MB (不同的处理器架构,可能不一样)注意: 使用Hugepage内存是共享内存,它会一直pin在内存中,不会被交换出去,也就是说使用hugepage的内存不能被其他的进程使用,所以一定要合理设置这个值,避免造成浪费。对于只使用Oracle的服务器来说,把Hugepage_pool设置成稍大于SGA大小即可。PGA因不是共享内存,是使用不到Hugepage的。 HugePages_Free - HugePages_Rsvd部分的内存是浪费的,且不能被其他程序使用。在实际应用中,尽可能让HugePages_Free - HugePages_Rsvd=0 设置了多少的huge page,free内存就会被使用多少。比如:设置sysctl vm.nr_hugepages=1024之后, free命令可以看到free的内存会减少2048MB (1024*2M)。(这也和Hugepagesize的大小有关) |
| HugePage 的好处 |
HugePages是Linux内核的一个特性,使用hugepage可以用更大的内存页来取代传统的4K页面。 使用HugePage主要带来以下好处: 1. HugePages 会在系统启动时,直接分配并保留对应大小的内存区域。 2. HugePages 在开机之后,如果没有管理员的介入,是不会释放和改变的。 3. 没有swap。Notswappable: HugePages are not swappable. Therefore thereis no page-in/page-outmechanism overhead.HugePages are universally regarded aspinned. 4. 大大提高了CPU cache中存放的page table所覆盖的内存大小,从而提高了TLB命中率。进程的虚拟内存地址段先连接到page table然后再连接到物理内存。所以在访问内存时需要先访问page tables得到虚拟内存和物理内存的映射关系,然后再访问物理内存。CPU cache中有一部分TLB用来存放部分page table以提高这种转换的速度。因为page size变大了,所以同样大小的TLB,所覆盖的内存大小也变大了。提高了TLB命中率,也提高了地址转换的速度。 5. 减轻page table的负载。进行XXX系统性能测试时,如果没有使用HugePages,数据库服务器上的pagetable大小大约为5G(这应该也是导致性能测试时数据库服务器内存不足的主要原因): node74:/home/Oracle # cat /proc/meminfoMemTotal: 16323732 kBPageTables: 5442384kB配置了HugePages后,pagetable大小仅为124M(性能测试时内存使用率稳定在80%左右): node74:/home/oracle # cat /proc/meminfoMemTotal: 16323732 kBPageTables: 127384 kBEliminated page tablelookup overhead: 因为hugepage是不swappable的,所有就没有page table lookups。Faster overall memory performance: 由于虚拟内存需要两步操作才能实际对应到物理内存地址,因此更少的pages,减轻了page table访问热度,避免了page table热点瓶颈问题。 6. 提高内存的性能,降低CPU负载,原理同上 |
3 配置HugePages |
| 3.1 修改内核参数memlock |
| ulimit -l 查看当前memlock 的大小。这个值应该大于SGA的配置。 |
| vi /etc/security/limits.conf * soft memlock 12582912 * hard memlock 12582912修改内核参数memlock,单位是KB,如果内存是16G,memlock的大小要稍微小于物理内存。计划lock 12GB的内存大小。参数设置为大于SGA是没有坏处的。也可以改成unlimited,没有影响。我们有生产系统就是这么配置的。 |
| 修改之后,重新登录即可生效。ulimit -l 验证 |
| 3.2 禁用oracle数据库的amm |
| 如果使用11G及以后的版本,AMM已经默认开启,但是AMM与Hugepages是不兼容的,必须先disable AMM。禁用AMM的步骤如下: |
| amm配置:SQL> alter system set memory_max_target=12G scope=spfile;SQL> alter system set memory_target=12G scope=spfile; SQL> alter system set sga_target=0m scope=spfile; SQL> alter system set sga_max_size=0 scope=spfile; SQL> alter system set pga_aggregate_target=0 scope=spfile; |
AMM启动之后,系统共享段变为“虚拟”共享段。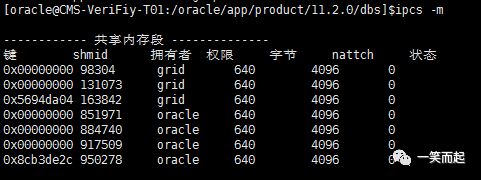 |
| asmm配置:SQL> alter system set memory_max_target=0 scope=spfile;SQL> alter system set memory_target=0 scope=spfile; SQL> alter system set pga_aggregate_target=3G scope=spfile; SQL> alter system set sga_target=8G scope=spfile; SQL> alter system set sga_max_size=8G scope=spfile;
|
vim /etc/sysctl.conf 修改kernel.shmall , 保证共享内存总页数满足我们的设计。实际上,这步也可以省略,我们是变大了页,所需要的页数更少。但是请了解这个参数的意义。 sysctl -p 修改后生效 |
| 3.3 计算hugepage大小 |
| 手工计算:nr_hugepages>=SGA_Target/Hugepagesize=30G*1024M/2M=15360取一个比15360稍大的值即可。 |
3.4 修改vm.nr_hugepages参数 |
| 以root用户登录两台数据库服务器,编辑/etc/sysctl.conf:node74:~ # vim /etc/sysctl.conf修改vm.nr_hugepages参数为上一步中计算出来的值:vm.nr_hugepages = 3200执行sysctl –p使配置生效:node74:~ # sysctl -p |
| 3.5 验证修改结果 |
| grep HugePages /proc/meminfo |
| 如何控制数据库SGA是否使用Hugepages? |
| 实际上oracle11.2.0.3 及以后的版本,是不需要关注这个配置的。 |
| 11.2.0.2之前的版本,DB的SGA只能选择全部使用hugepages或者完全不使用hugepages。 11.2.0.2 及以后的版本, oracle增加了一个新的参数“USE_LARGE_PAGES”来管理数据库如何使用 hugepages. 在11.2.0.3的时候,USE_LARGE_PAGES这个参数让Oracle的行为更加灵活。如果出现HugePage分配不足的情况,SGA是可以使用那些small pages的。这就保证了极端情况下数据库是可以正常运行的。 USE_LARGE_PAGES参数有三个值: "true" (default), "only", "false" and "auto"(since 11.2.0.3 patchset). a). 现在默认值是"true",如果系统设置Hugepages的话,SGA会优先使用hugepages,有多少用多少。11.2.0.2 如果没有足够的 hugepages, SGA是不会使用hugepages的. 这会导致ORA-4030错误,因为hugepages已经从物理内存分配,但是SGA没有使用它,却使用其他部分内存,导致内存资源不足。 但是在11.2.0.3版本这个使用策略被改变了,SGA可以一部分使用hugepages,剩余部分使用smallpages.这样,SGA会有限使用hugepages,在hugepages用完之后,再使用regular sized pages。 b). 如果设置为"false" , SGA就不会使用hugepages c). 如果设置为 "only" 如果hugepages大小不够的话,数据库实例是无法启动的 (防止内存溢出的情况发生). d). 11.2.0.3版本之后,可以设置为 "auto".这个选项会触发oradism进程重新配置linux内核,以增加hugepages的数量。 |
| SGA 设置多少值合理 |
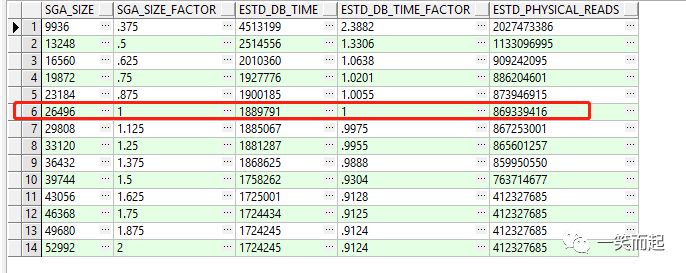
v$sga_target_advice:该视图可用于建议SGA大小设置是否合理。 SELECT a.sga_size,--sga期望大小 a.sga_size_factor,--期望sga大小与实际sga大小的百分比 a.estd_db_time,--sga设置为期望的大小后,其dbtime消耗期望的变化 a.estd_db_time_factor,--修改sga为期望大小后,dbtime消耗的变化与修改前的变化百分比 a.estd_physical_reads--修改前后物理读的差值 FROM v$sga_target_advice a; 其中: 1、SGA_SIZE_FACTOR为1代表的是当前实际sga大小 2、关注a.estd_physical_reads字段,假如前台数值差距不大,那么这个时候sga的效率是最高 |
|
| PGA 设置多少合理 |
| V$pga_Target_Advice |
|
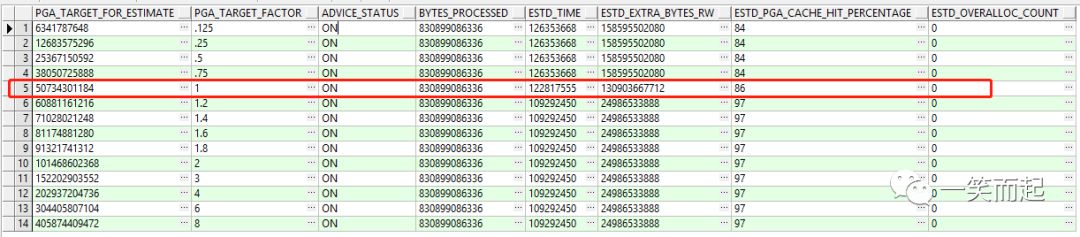
| V$pga_Target_Advice | |
| Column | Description |
| PGA_TARGET_FOR_ESTIMATE | 预测的PGA target的值,单位是byte |
| PGA_TARGET_FACTOR | 1表示当前的配置情况 |
| ADVICE_STATUS | 显示建议是否开启。取决于参数 STATISTICS_LEVEL |
| BYTES_PROCESSED | oracle advise 统计的PGA工作区处理的总字节数 (in bytes) |
| ESTD_TIME | 处理上述字节数的时间,单位(秒) |
| ESTD_EXTRA_BYTES_RW | 设置为对应的PGA大小后,估计要额外处理的读、写的数据量(单位byte)。这个数字是通过PGA工作区一次或多次运行的估计数量和大小得出的。 |
| ESTD_PGA_CACHE_HIT_PERCENTAGE | 缓存命中百分比统计的估计值。计算方式:BYTES_PROCESSED / (BYTES_PROCESSED + ESTD_EXTRA_BYTES_RW) |
| ESTD_OVERALLOC_COUNT | 非零值意味着用于评估的PGA目标值不足以运行工作区工作负荷。A nonzero value means that PGA_TARGET_FOR_ESTIMATE is not large enough to run the work area workload. |
