





文/杨楠
Hadoop分布式文件存储HDFS的设计目标是通过统一管理大量的服务器和磁盘,从而向应用程序提供超大的存储容量。为了实现这样的目标,HDFS将数据分片后存储在多个磁盘上进行并发的读写,同时通过冗余存储的方式提升了服务的可靠性。
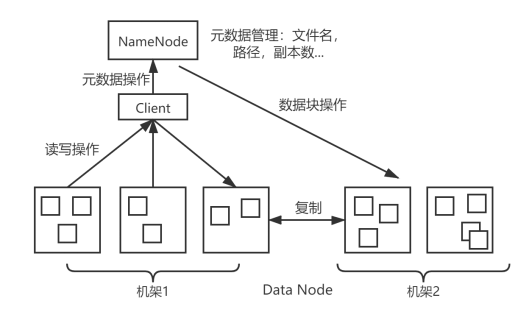
如图所示,HDFS包含两个关键组件:NameNode和DataNode。
NameNode负责维护系统的命名空间,即对集群的元数据信息进行管理,包括文件路径、数据块ID和存储位置等信息。
DataNode负责数据的处理,HDFS将文件分为不同的数据块,分散的存储到不同的节点上。在生产环境中,通常会部署很多的DataNode服务器组成超大容量的集群来提供服务。
对象存储拥有着和HDFS完全不同的架构,它将数据作为对象来管理,每个对象通常包括数据本身、可编辑的元数据和全局唯一标识符。如图所示,对象存储的架构主要分为三个部分:
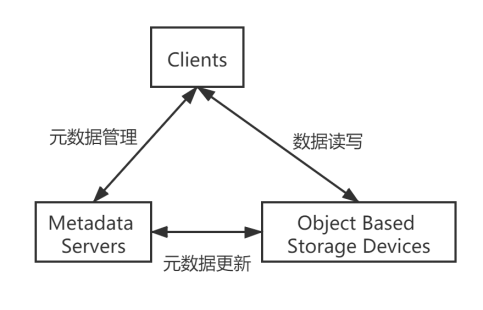
OSD对象存储设备(Object Based Storage Devices)
OSD是对象存储集群中最重要的组件,它负责以对象的形式存储来自客户端的数据,同时通过计算,使得集群中的数据分布更加合理。
MDS元数据服务器(Metadata Service)
除了用于管理集群中对象的元数据信息外,MDS还管理着限额配置,桶策略,访问控制权限等。
客户端(Clients)
提供对存储文件的访问。
HDFS将集群作为一个整体面向用户和应用程序访问,它支持我们像在普通文件系统上一样创建目录和存储文件。
HDFS一致性模型是one-copy-update-semantics,所有的客户端都会看到相同的文件内容,具体来说包括以下几个方面:
Create:一旦创建完成一个新文件后,集群中查询文件元数据和内容的操作能够立刻看到该文件和数据;
Update:一旦更新完成一个新文件后,集群中查询文件元数据和内容的操作能够立刻看到新的文件和数据;
Delete:一旦针对除了根目录外的某个路径删除后,它就会立即不可见和不可访问;
Delete then create:当删除一个文件,然后创建一个同名的新文件时,新文件必须立即可见,并且可以通过文件系统API访问其内容;
Rename:rename()完成之后,针对新路径的操作必须成功,针对旧路径的操作必须失败。
在对象存储中,不存在目录结构,所有的文件都存储在一个平面的地址空间中,这种简单的存储方式大大增强了它的伸缩性。我们可以使用三种基本操作对存储的资源进行管理:PUT和GET,DELETE。
PUT:将本地的文件存储到对象存储集群中,在创建对象时,存储库会返回对象的唯一标识符(通常是文件名);
GET:根据标识符来获取对象的内容,存储库会根据标识符进行检索并返回文件;
DELETE:存储库会根据标识符进行检索并删除文件。
由于只有这些简单的操作,对象存储服务具有如下的特点:
不提供文件锁的功能:如果同时(几乎)发起两个键相同的PUT请求,对象存储会按照请求到达的时间进行更新。
访问对象不需要经过主节点:由于对象标识符在集群中是唯一的,服务器通过一个哈希函数就可以确定对象的存储位置。
这两种特性可以有效地提升文件访问的IO性能。
对象存储的一致性模型是eventual consistency,这就意味着对于对象的创建、删除和更新需要一定的时间才能对所有的用户可见。
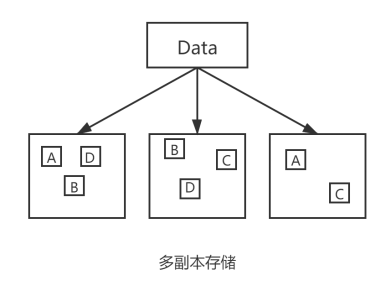
HDFS存储的核心原理是:对数据分片后进行冗余存储,这样的设计保障了数据的准确性,即使是集群中某块磁盘损坏也不会丢失数据。但是,对于一次写入需要多次读取的使用场景,这样的存储开销会很大,集群的容量很快就会成为瓶颈。
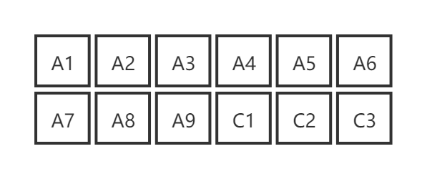
对象存储采用纠删码的方式来对数据进行存储,纠删码(Erasure Coding,EC)是一种编码容错技术,基本原理是将数据分割为n块,然后通过一定的计算得到m个冗余块,然后将这n+m块元素存储在不同的位置,达到高可用的目的。
对于这n+m块的元素,可以使用其中任意n块恢复出原有的数据,因此磁盘利用率为n/(n+m),相比HDFS的副本存储,具有冗余度低、磁盘利用率高的特点。
如图所示:假设n和m分别是(9,3),算法会将数据先分成九份,然后经过计算得到3个冗余块。在这12份数据中,任意9份都可以恢复出完整的数据,可以大大节约存储开销。
在HDFS中,原子性是文件系统非常重要的属性。包含原子性的操作如下:
创建文件:如果overwrite参数为false,则检查和创建必须是原子的;
删除文件;
重命名文件;
重命名目录;
使用mkdir()创建一个目录;
对于对象存储中某个对象,所有的操作都是原子操作。但是对于目录的操作是非原子的,这是因为对象存储中没有目录的概念(所看到的目录是模拟出来的),因此对一个目录的操作就是对该目录下所有的子目录和对象的多次操作。这种特性会导致一次失败的作业在集群中留下一个中间操作状态。
HDFS可以从两个方面来选择扩容方案:
1. 横向扩容:通过向集群中增加更多的节点,即增加更多的DataNode;
2. 纵向扩容:主要方法是通过挂载硬盘的方式扩展现有节点的磁盘容量。
HDFS中使用了Name Node管理集群的元数据,因此当集群的容量变得越来越大时,Name Node的负担也会越来越重。HDFS的扩容意味着需要相应的提升Name Node的配置,并且还要设计对应的高可用方案。
使用对象存储中隔离了计算和存储,我们可以在不影响集群计算能力的前提下独立的扩展存储容量。此外,对于对象存储来说,元数据不再存储在一台单独的机器上,而是通过一致性哈希算法分片存储到不同的节点上。当集群中的数据不断增长时,可以在集群中添加节点以有效的提升容量。
对象存储通过简化文件系统功能的方式,实现在低成本存储的同时能够保证扩展性和可靠性。因此,对象存储首先是一种有效的数据存档方案,可以用于将温冷数据从HDFS卸载到成本较低的存储设备上。其次,对象存储也能良好的胜任数据湖收集数据和创造业务价值的要求——以高度可扩展、安全且经济有效的方式来存储和保护数据。而面对这些要求,传统的HDFS的架构差异往往会导致在成本、灵活性上的问题。


顾问:许国平 李湘宜
罗学平 刘德清 张刚
总编:孙鹏晖
编辑:韩翠娟
美编:白羽
 长按二维码,关注我们吧!
长按二维码,关注我们吧!
-本文为“数风云”第34期文章;
-转载本公众号文章请联系我们;
-欢迎来稿:请按“题目-作者”格式命名发送到sunpenghui@abchina.com。
