




“


实现了Redis的主从复制,在一定程度上保证了数据的可用性,但是如果主从复制中的master 节点挂掉,Redis将不再对外提供读写操作。假设当主从复制中的master节点挂掉后,如果能够从它的slave节点中重新选举一个节点作为master节点,那么系统就可以恢复了,因此就有了Redis的哨兵(sentinel)模式。

目录
1. 哨兵模式的主要原理
2. 主观下线与客观下线
3. 哨兵模式注意事项
4. 运行哨兵实例docker-compose.yml
1
哨兵模式主要原理
官方文档:https://redis.io/topics/sentinel
1. 监控:能持续监控Redis的主从实例是否正常工作;
2. 通知:当被监控的Redis实例出问题时,能通过API通知系统管理员或其他程序;
3. 自动故障恢复:如果主实例无法正常工作,Sentinel将启动故障恢复机制把一个从实例提升为主实例,其他的从实例将会被重新配置到新的主实例,且应用程序会得到一个更换新地址的通知。
4. 配置提供:因为sentinel保存着Redis主从的信息,所以Redis可以从sentinel那获得所有的配置信息。
简而言之,Redis 2.8 之后提供了一个哨兵的机制用于监控主从复制,一个主从复制中可以有多个哨兵,当一定数量的哨兵监控到master下线后,哨兵们会重新投票选举slave节点作为master节点,恢复系统的读写操作,后续如果 老的 master节点恢复工作,则作为slave节点提供服务。其中一个哨兵也是一个Redis实例。
2
主观下线与客观下线
1. 主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
2. 客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。
简而言之,单个哨兵先主观判断master是否下线,然后多个哨兵商量之后出现客观下线。
反映到程序运行过程如下:
redis-sentinel-2 | 1:X 05 Feb 2020 04:55:35.594 * +sentinel sentinel a7c0f682c34f0dd338540fe394ad0548acbf78fd 172.19.0.6 26379 @ mymaster 172.19.0.3 6380redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.705 * +sentinel sentinel d76407d7012eacc5e5b8bbb9bf0e87954057707a 172.19.0.7 26379 @ mymaster 172.19.0.2 6379redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.704 * +sentinel sentinel d76407d7012eacc5e5b8bbb9bf0e87954057707a 172.19.0.7 26379 @ mymaster 172.19.0.2 6379redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.709 # +new-epoch 1redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.709 # +config-update-from sentinel d76407d7012eacc5e5b8bbb9bf0e87954057707a 172.19.0.7 26379 @ mymaster 172.19.0.2 6379redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.709 # +switch-master mymaster 172.19.0.2 6379 172.19.0.3 6380redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.710 * +slave slave 172.19.0.4:6381 172.19.0.4 6381 @ mymaster 172.19.0.3 6380redis-sentinel-3 | 1:X 05 Feb 2020 04:55:35.710 * +slave slave 172.19.0.2:6379 172.19.0.2 6379 @ mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.708 # +new-epoch 1redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.708 # +config-update-from sentinel d76407d7012eacc5e5b8bbb9bf0e87954057707a 172.19.0.7 26379 @ mymaster 172.19.0.2 6379redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.708 # +switch-master mymaster 172.19.0.2 6379 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.708 * +slave slave 172.19.0.4:6381 172.19.0.4 6381 @ mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:55:35.708 * +slave slave 172.19.0.2:6379 172.19.0.2 6379 @ mymaster 172.19.0.3 6380redis-sentinel-2 | 1:X 05 Feb 2020 04:56:04.712 # +sdown sentinel 55b3e9ab3d7135b608a64da0e2dcc29b4ce72518 172.19.0.5 0 @ mymaster 172.19.0.3 6380redis-sentinel-2 | 1:X 05 Feb 2020 04:56:04.712 # +sdown sentinel 40c09e7c2c35c48331f9770d06f8b4e9f5a5e560 172.19.0.6 0 @ mymaster 172.19.0.3 6380redis-sentinel-2 | 1:X 05 Feb 2020 04:56:23.731 # +sdown master mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.625 # +sdown master mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.684 # +odown master mymaster 172.19.0.3 6380 #quorum 2/2redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.684 # +new-epoch 2redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.684 # +try-failover master mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.686 # +vote-for-leader 7dffb89a8bf7fb3d52c2a2eaf2216ebab1d369f4 2redis-sentinel-2 | 1:X 05 Feb 2020 04:56:33.689 # +new-epoch 2redis-sentinel-3 | 1:X 05 Feb 2020 04:56:33.689 # +new-epoch 2redis-sentinel-3 | 1:X 05 Feb 2020 04:56:33.690 # +vote-for-leader 7dffb89a8bf7fb3d52c2a2eaf2216ebab1d369f4 2redis-sentinel-2 | 1:X 05 Feb 2020 04:56:33.691 # +vote-for-leader 7dffb89a8bf7fb3d52c2a2eaf2216ebab1d369f4 2redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.691 # a7c0f682c34f0dd338540fe394ad0548acbf78fd voted for 7dffb89a8bf7fb3d52c2a2eaf2216ebab1d369f4 2redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.691 # d76407d7012eacc5e5b8bbb9bf0e87954057707a voted for 7dffb89a8bf7fb3d52c2a2eaf2216ebab1d369f4 2redis-sentinel-3 | 1:X 05 Feb 2020 04:56:33.708 # +sdown master mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.739 # +elected-leader master mymaster 172.19.0.3 6380redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.739 # +failover-state-select-slave master mymaster 172.19.0.3 6380redis-sentinel-3 | 1:X 05 Feb 2020 04:56:33.767 # +odown master mymaster 172.19.0.3 6380 #quorum 3/2redis-sentinel-3 | 1:X 05 Feb 2020 04:56:33.767 # Next failover delay: I will not start a failover before Wed Feb 5 05:02:34 2020redis-sentinel-1 | 1:X 05 Feb 2020 04:56:33.791 # +selected-slave slave 172.19.0.4:6381 172.19.0.4 6381 @ mymaster 172.19.0.3 6380redis-sentinel-1 |先出现 +sdown 再出现odown ,然后再 投票产生新的 master
3
哨兵模式注意事项
1)只有Sentinel 集群中大多数服务器认定master主观下线时master才会被认定为客观下线,才可以进行故障迁移,也就是说,即使不管我们在sentinel monitor中设置的数是多少,就算是满足了该值,只要达不到大多数,就不会发生故障迁移。2)官方建议sentinel至少部署三台,且分布在不同机器。这里主要考虑到sentinel的可用性,假如我们只部署了两台sentinel,且quorum设置为1,也可以实现自动故障迁移,但假如其中一台sentinel挂了,就永远不会触发自动故障迁移,因为永远达不到大多数sentinel认定master主观下线了。3)sentinel monitor配置中的master IP尽量不要写127.0.0.1或localhost,因为客户端,如jedis获取master是根据这个获取的,若这样配置,jedis获取的ip则是127.0.0.1,这样就可能导致程序连接不上master4)当sentinel 启动后会自动的修改sentinel.conf文件,如已发现的master的slave信息,和集群中其它sentinel 的信息等,这样即使重启sentinel也能保持原来的状态。注意,当集群服务器调整时,如更换sentinel的机器,或者新配置一个sentinel,请不要直接复制原来运行过得sentinel配置文件,因为其里面自动生成了以上说的那些信息,我们应该复制一个新的配置文件或者把自动生成的信息给删掉。5)当发生故障迁移的时候,master的变更记录与slave更换master的修改会自动同步到redis的配置文件,这样即使重启redis也能保持变更后的状态。
4
运行哨兵实例
1.docker-compose.yml
version: '3.6'services:master:image: rediscontainer_name: redis-masterrestart: alwayscommand: redis-server --port 6379 --requirepass pass123 --masterauth pass123 --appendonly yesports:- 6379:6379volumes:- ./data/master:/dataslave1:image: rediscontainer_name: redis-slave-1restart: alwayscommand: redis-server --slaveof master 6379 --port 6380 --requirepass pass123 --masterauth pass123 --appendonly yesports:- 6380:6380volumes:- ./data/slave1:/datadepends_on:- masterslave2:image: rediscontainer_name: redis-slave-2restart: alwayscommand: redis-server --slaveof master 6379 --port 6381 --requirepass pass123 --masterauth pass123 --appendonly yesports:- 6381:6381volumes:- ./data/slave2:/datadepends_on:- slave1- mastersentinel1:image: rediscontainer_name: redis-sentinel-1command: redis-sentinel /usr/local/etc/redis/sentinel.confrestart: alwaysports:- 26379:26379volumes:- ./sentinel1.conf:/usr/local/etc/redis/sentinel.confdepends_on:- slave2sentinel2:image: rediscontainer_name: redis-sentinel-2command: redis-sentinel /usr/local/etc/redis/sentinel.confrestart: alwaysports:- 26380:26379volumes:- ./sentinel2.conf:/usr/local/etc/redis/sentinel.confdepends_on:- slave2sentinel3:image: rediscontainer_name: redis-sentinel-3command: redis-sentinel /usr/local/etc/redis/sentinel.confrestart: alwaysports:- 26381:26379volumes:- ./sentinel3.conf:/usr/local/etc/redis/sentinel.confdepends_on:- slave2
2.哨兵配置文件,需要 3个
port 26379#Sentinel服务运行时使用的临时文件夹dir /tmp# 自定义集群名,其中 192.168.229.129 6379 为 redis-master 的 ip,6379 为 redis-master 的端口,2 为最小投票数(因为有 3 台 Sentinel 所以可以设置成 2)# 因为是单机部署,主节点的hostname 为redis-mastersentinel monitor mymaster redis-master 6379 2#指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。单位是毫秒,默认为30秒sentinel down-after-milliseconds mymaster 30000#指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因#为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。sentinel parallel-syncs mymaster 1# 登录master密码sentinel auth-pass mymaster test@dbuser2018#置集群从判断节点挂掉,到执行failover操作(即重新选举master节点)的时间sentinel failover-timeout mymaster 180000# 避免脚本重置,默认值yes# 默认情况下,SENTINEL SET将无法在运行时更改notification-script和client-reconfig-script。# 这避免了一个简单的安全问题,客户端可以将脚本设置为任何内容并触发故障转移以便执行程序。sentinel deny-scripts-reconfig yes#当sentinel触发时,切换主从状态时,需要执行的脚本。当主down的时候可以通知当事人,#sentinel notification-script master1/data/scripts/send_mail.sh
复制同样的3 份即可。
cp sentinel.conf sentinel1.confcp sentinel.conf sentinel2.confcp sentinel.conf sentinel3.conf
运行结果:
首先看下我的目录结构:
[root@master redis-sentinel]# lsdata docker-compose.yml sentinel1.conf sentinel2.conf sentinel3.conf sentinel.conf[root@master redis-sentinel]#
将最初的master 停掉:
[root@master redis-sentinel]# docker stop redis-masterredis-master
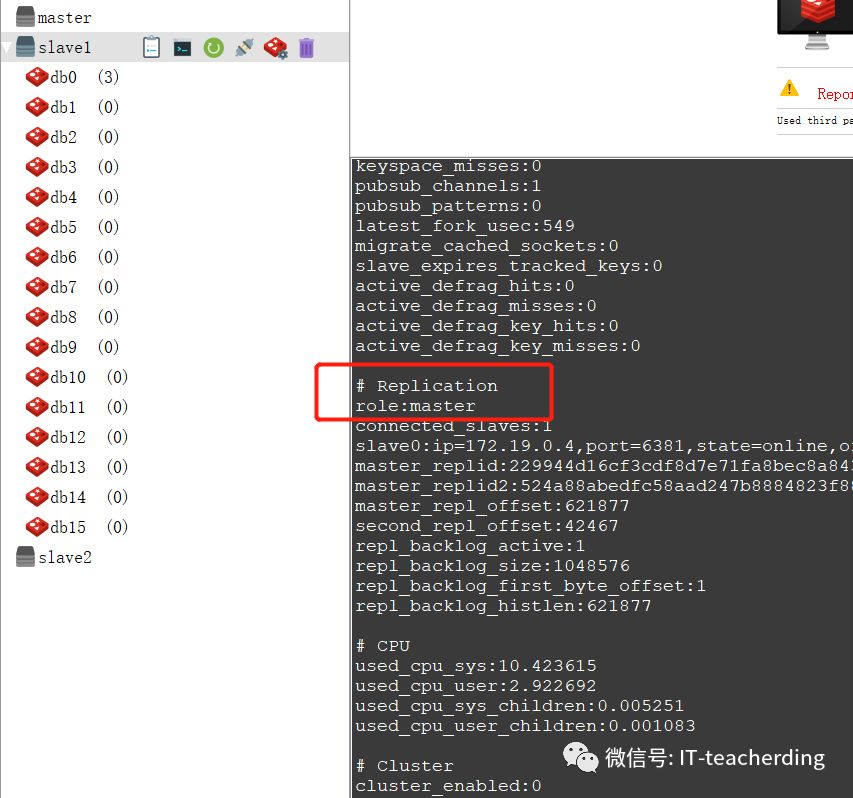
哨兵们会选举出新的,设立slave1 变成了master,使用info 命令查看。
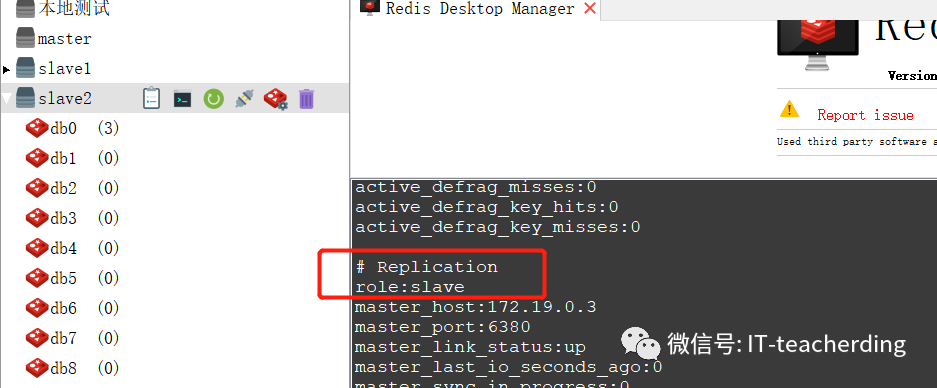
slave2 仍然是 slave
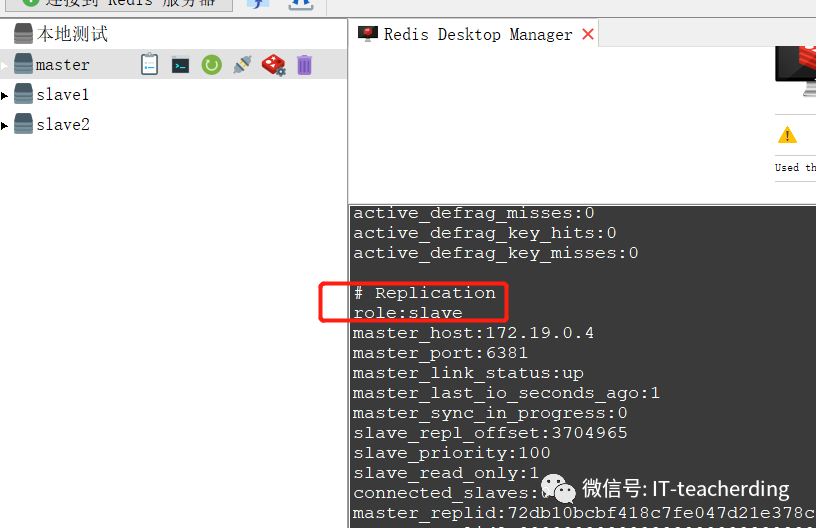
而当原先master恢复工作之后,就会变成slave。
END



关注二维码
获取更多精彩内容

