




一. 简介:
1. 什么是ShardingSphere
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
2. ShardingSphere的定位
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
二. 分库分表:
1. 为什么么要进行分库分表?
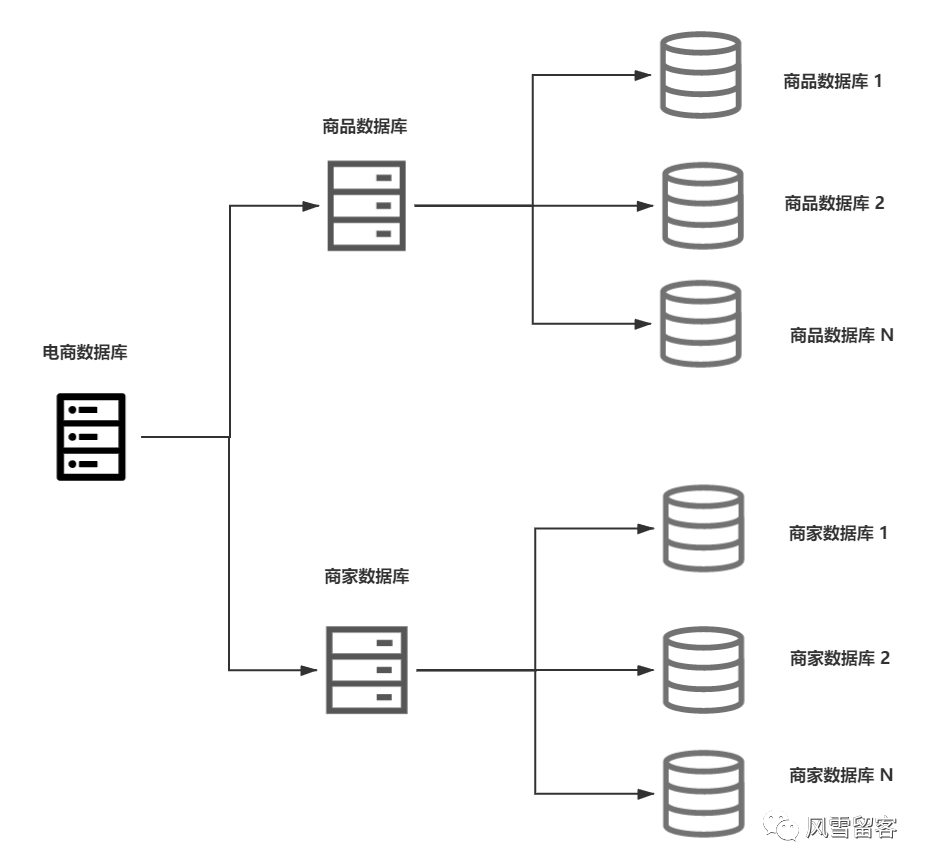
我们都知道,数据库的数据量是不可控的,就好比大型的电商项目,随着时间的发展,
数据量会越来越多,一旦达到某个量,我们再去对数据库进行操作的时候,就会遇到性能瓶颈的问题,解决方案之一,便是对数据库进行分库分表操作.如下图:
2. 分库分表的方式:
⑴. 垂直拆分
垂直拆分又可分为:
①.垂直分库:
把单一业务按照业务进行划分,专库专表,分别把不同的数据库存放到不同的服务器,减轻服务器的压力,如图: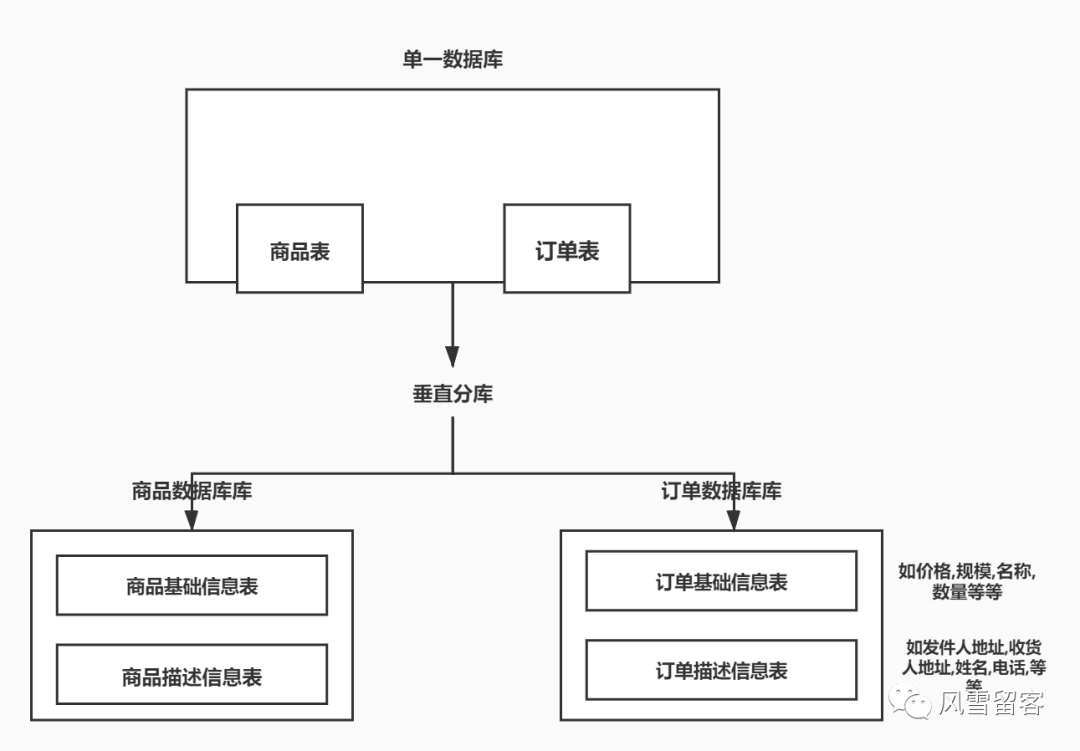
②. 垂直分表:
就是把其中一部分信息放入一张表,把另一部分信息放入一张表,就好比商品,我们把商品的基础信息放入一张表,把商品的描述信息放入一张表.如下图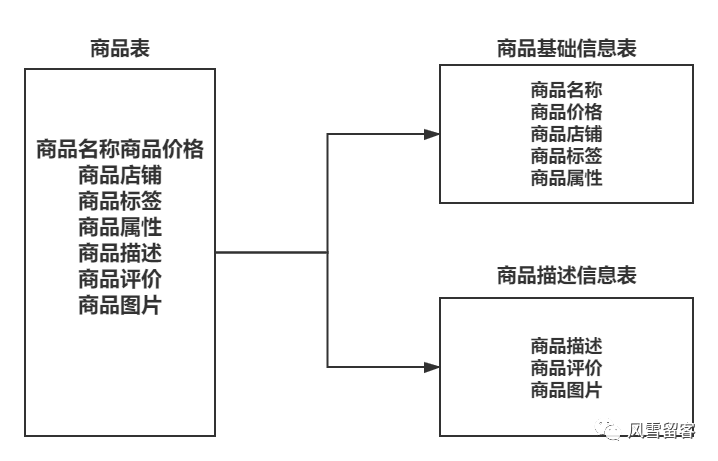
好处:
就好比我们在京东上搜索手机,映入眼帘的都是商品的基本信息,只有当我们点进去的时候,才会显示商品的描述信息,不用查该商品的全部信息,节约资源.如下图: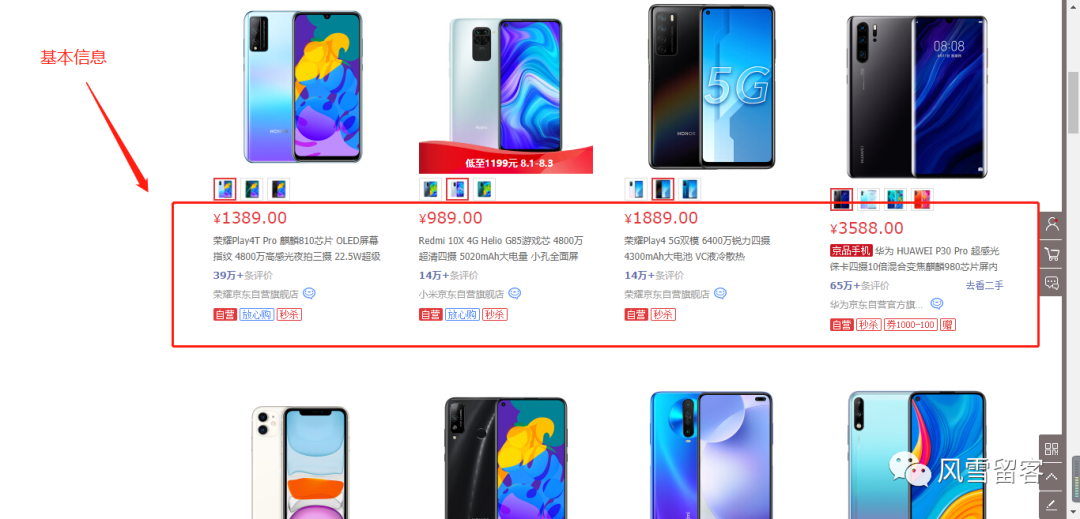
⑵. 水平拆分
水平拆分也可分为:
①.水平分库:
水平分库就是把单个数据库,变成多个数据库,做水平分库的前提是,两个数据库中的表结构需要一致,我们在插入数据的时候,根据一定的规则,判断数据是存入A数据库还是B数据库.可减少我们之前单个数据库性能瓶颈的问题.如下图: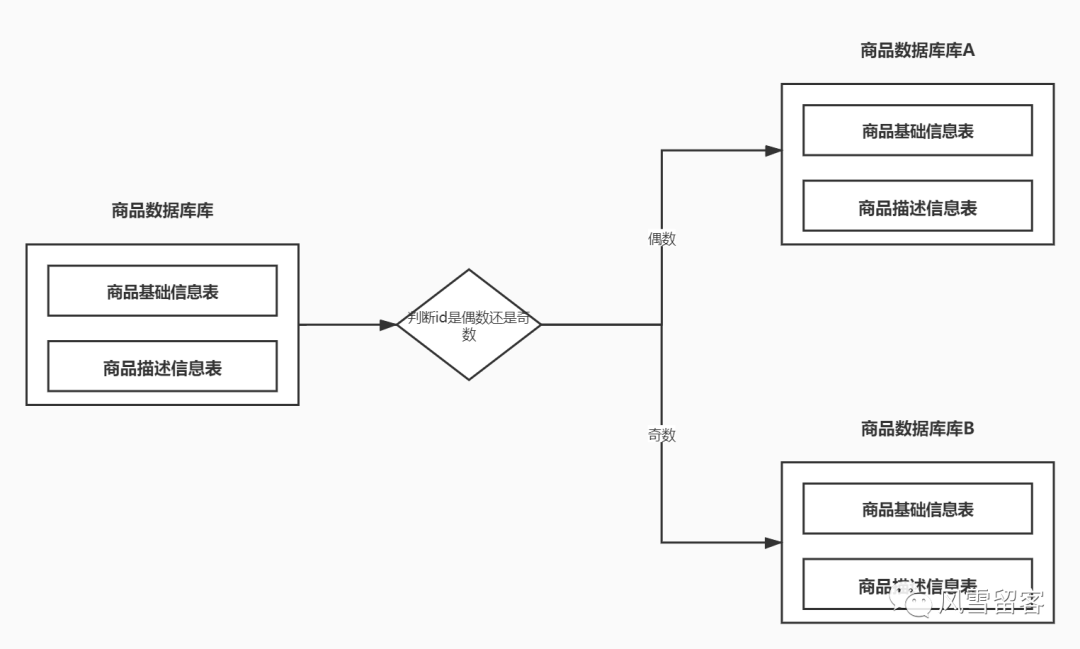
②. 水平分表:
水平分表就是在刚才分库的基础上,再将单个表复制成多个表,表结构不变,通过相应的规则将数据存入不同的表中,将表数据进行分担,减轻数据库的压力.如下图: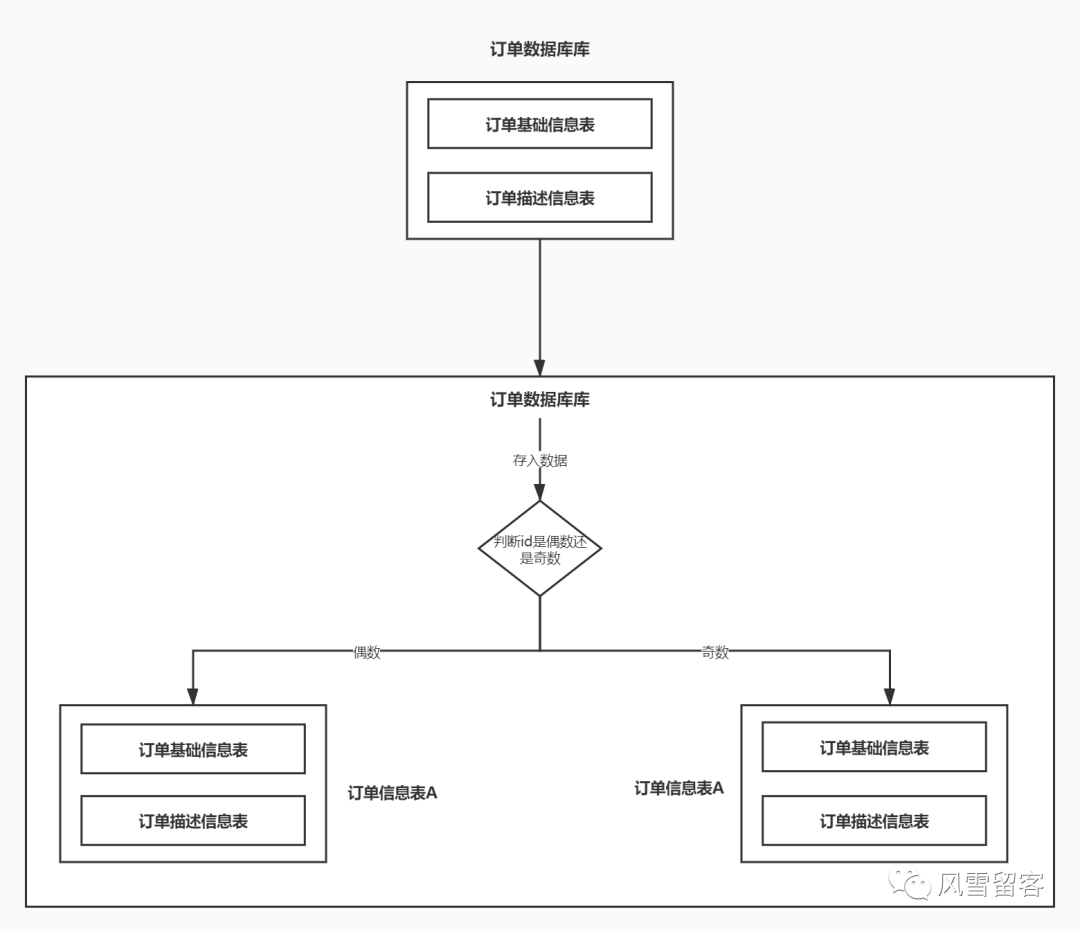
3. 分库分表的应用和问题:
⑴.应用
在数据库设计时候考虑垂直分库和垂直分表
随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
⑵. 分库分表问题
存在跨节点Join的问题。
存在跨节点合并排序、分页的问题。
存在多数据源管理的问题。
三. Sharding JDBC:
1. 介绍:
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布,如下: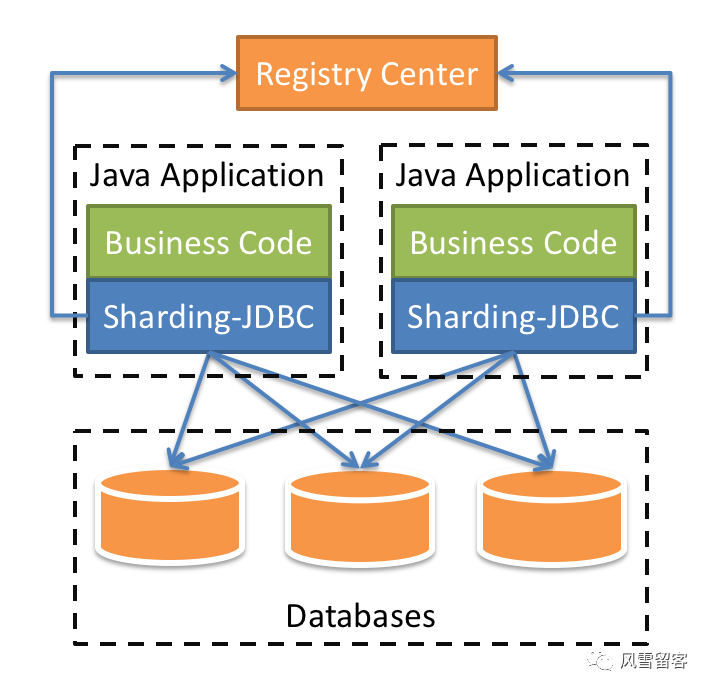
2. 使用Sharding-JDBC实现水平分表:
⑴. 搭建环境(SpringBoot + MyBatisPlus + Sharding-JDBC + Druid连接池):
创建一个名为sharding-sphere-demo的工程.
⑵. 引入依赖:
pom文件代码:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.1.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.fast</groupId><artifactId>sharding-sphere-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>sharding-sphere-demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.20</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.0.5</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
⑶. 水平分表:
创建数据库course_db
在数据库创建两张表 course_1 和 course_2
约定规则:如果添加课程id是偶数把数据添加course_1,如果奇数添加到course_2
建表语句:
CREATE TABLE course_1(cid BIGINT(20) PRIMARY KEY,cname VARCHAR(50) NOT NULL,user_id BIGINT(20) NOT NULL,cstatus VARCHAR(10) NOT NULL)CREATE TABLE course_2(cid BIGINT(20) PRIMARY KEY,cname VARCHAR(50) NOT NULL,user_id BIGINT(20) NOT NULL,cstatus VARCHAR(10) NOT NULL)
⑷. 新建Course实体类:
@Data@Accessors(chain = true) //链式写法 .set .setpublic class Course {@TableIdprivate Long cid;private String cname;private Long userId;private String cstatus;}
⑸. 创建CourseMapper:
@Repositorypublic interface CourseMapper extends BaseMapper<Course> {}
⑹. 修改启动类:
@SpringBootApplication@MapperScan("com.fast.shardingspheredemo.mapper")public class ShardingSphereDemoApplication {public static void main(String[] args) {SpringApplication.run(ShardingSphereDemoApplication.class, args);}}
3. 配置Sharding-JDBC分片策略:
参考官方中文文档:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/#数据源名称,多数据源以逗号分隔spring.shardingsphere.datasource.names=ds0#数据库连接池类名称spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.ds0.username=root#数据库密码spring.shardingsphere.datasource.ds0.password=123456##由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,指定course表分布情况,配置表在哪个数据库里面,表名称都是什么# tables.course course表规则, 通过官方文档我们也能看出tables.<logic-table-name> 我们的数据库表都为course_1 和 course_2 ,都是以course开头,因此,填写时需要注意#ds0.course_$->{1..2} 该值代表为: ds0数据库.course_表名 $->{1..2}规则 我们的表现在只有1,2spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds0.course_$->{1..2}# 指定course表里面主键 cid#tables.course course 表示表的规则,可以理解为以什么开头spring.shardingsphere.sharding.tables.course.key-generator.column=cid#生成策略 SNOWFLAKE 基于雪花算法,随机生成唯一的数字spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE# 指定分片策略 以cid主键分片spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid#约定 cid值偶数添加到course_1表,如果cid是奇数添加到 course_2表#因为我们的表名称为1和2 cid % 2 这样取余会出现问题,因此我们取余之后加一, 比如我们 id为2 取余为0 ,加一为1,存放到1表,如果不为偶数,就在表2添加数据,当然,如果你把表明改为0和1,可不做加一运行算spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}# 打开sql输出日志spring.shardingsphere.props.sql.show=true
4. 插入数据测试:
@RunWith(SpringRunner.class)@SpringBootTestpublic class ShardingSphereDemoApplicationTests {@Autowiredprivate CourseMapper courseMapper;@Testpublic void addCourse() {Course course = new Course();course.setCname("java从入门到摔门").setUserId(1L).setCstatus("normal");courseMapper.insert(course);}}
5. 出现的问题
启动发现,报错了.
Description:The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and overriding is disabled.Action:Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
通过提示我们可以看出,dataSource这个bean无法注册,因为在DruidDataSourceAutoConfigure已经定义这个bean,并且禁止重写,其实也就是我们一个实体类无法关联两张表,
其实已经提示我们该如何解决了,
在配置中增加以下配置:
spring.main.allow-bean-definition-overriding=true
6. 重新测试:
执行成功.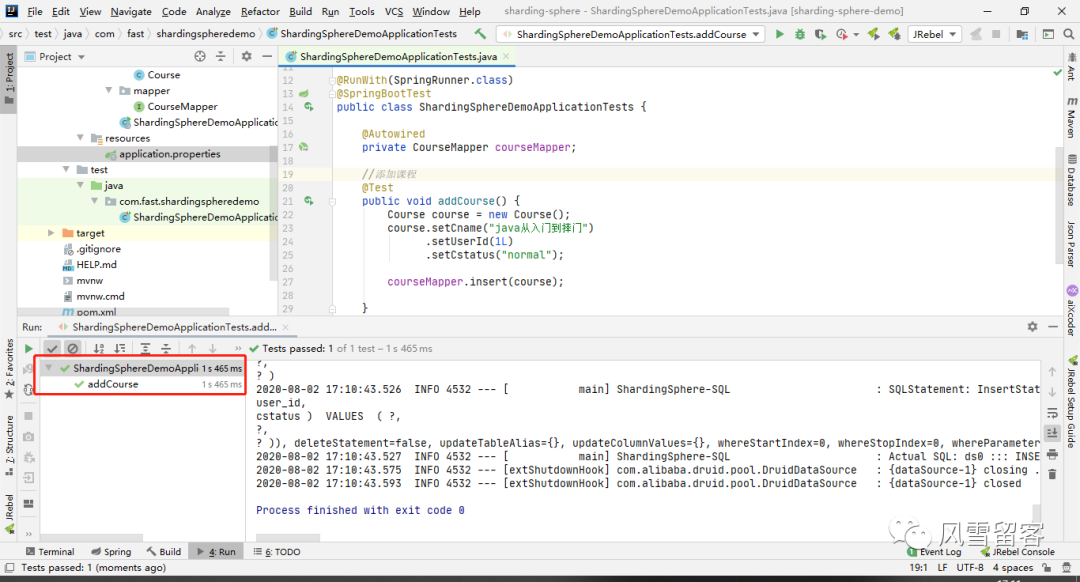
我们在设置中打开了日志输出,我们查看日志里面的这样一句话:
Actual SQL: ds0 ::: INSERT INTO course_2 (cname, user_id, cstatus, cid) VALUES (?, ?, ?, ?) ::: [java从入门到摔门, 1, normal, 496730765988462593]解析:ds0 数据源名称496730765988462593 id为奇数INSERT INTO course_2 在我们定义的规则中,id为奇数,往表2插入数据
查看表: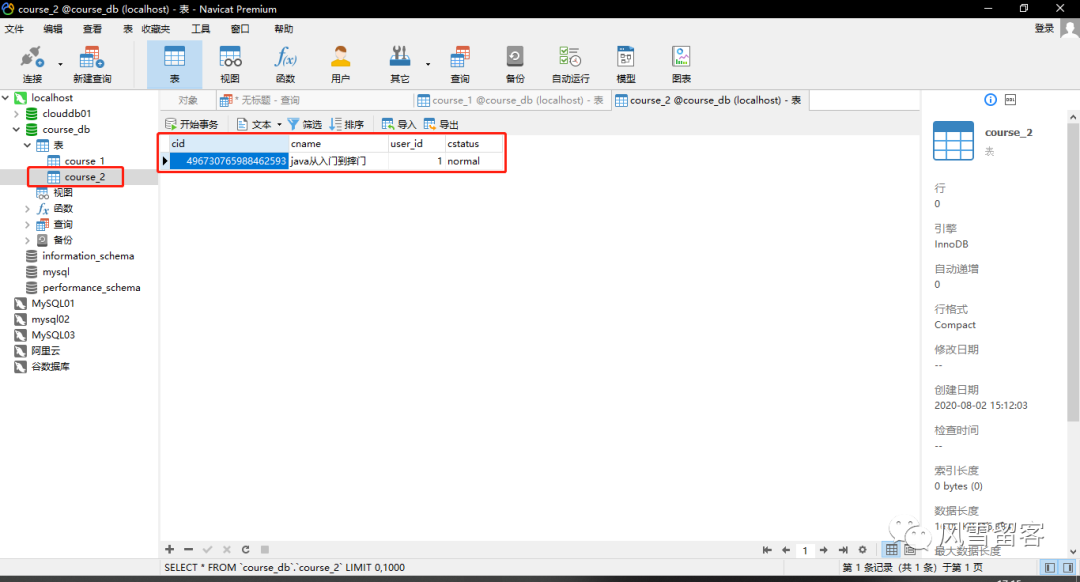
现在让我们通过循环插入数据:
@Testpublic void addCourse() {Course course = new Course();course.setCname("java从入门到摔门").setUserId(1L).setCstatus("normal");for (int i = 0; i < 10; i++) {courseMapper.insert(course);}}
查看表数据: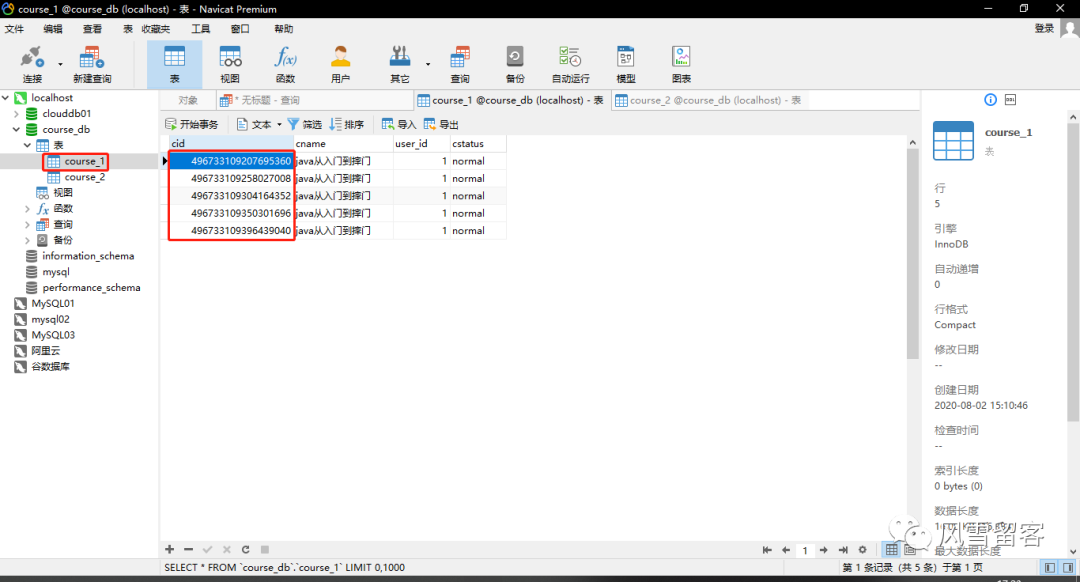
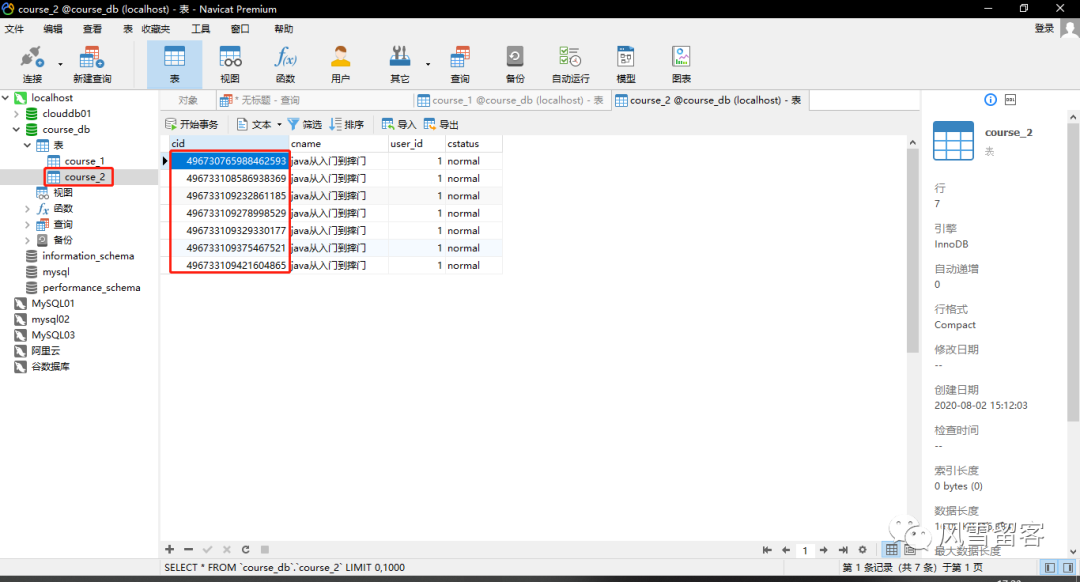
不难发现,表1全部都属偶数,表2全部都是奇数.
7. 查询测试:
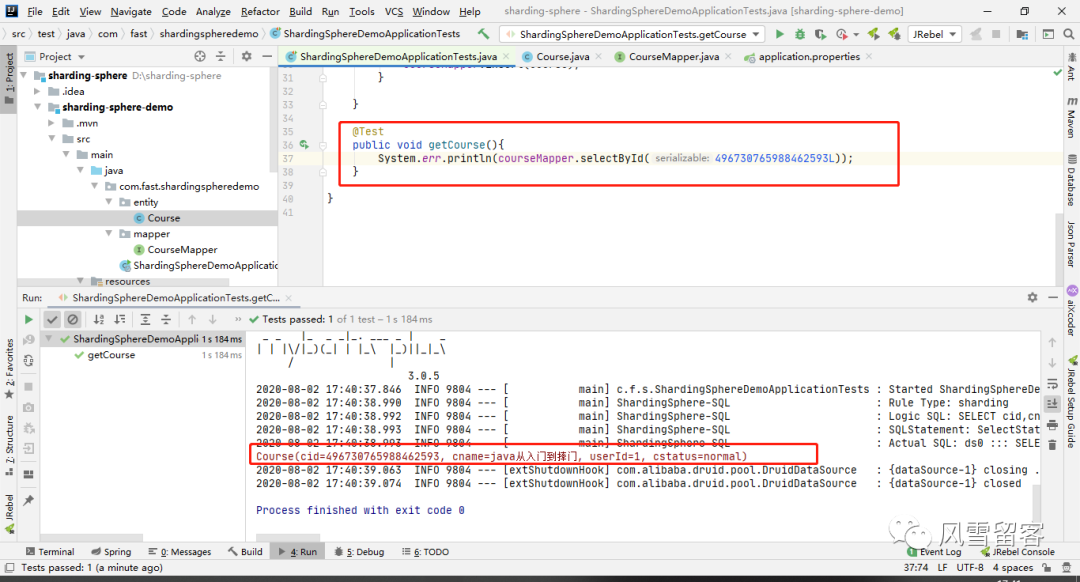
四. 使用Sharding-JDBC实现水平分库:
首先我们将数据库做水平分库处理,根据用户id不同,存入到不同的数据库,水平分表还是按照以前的规则来做.如图:
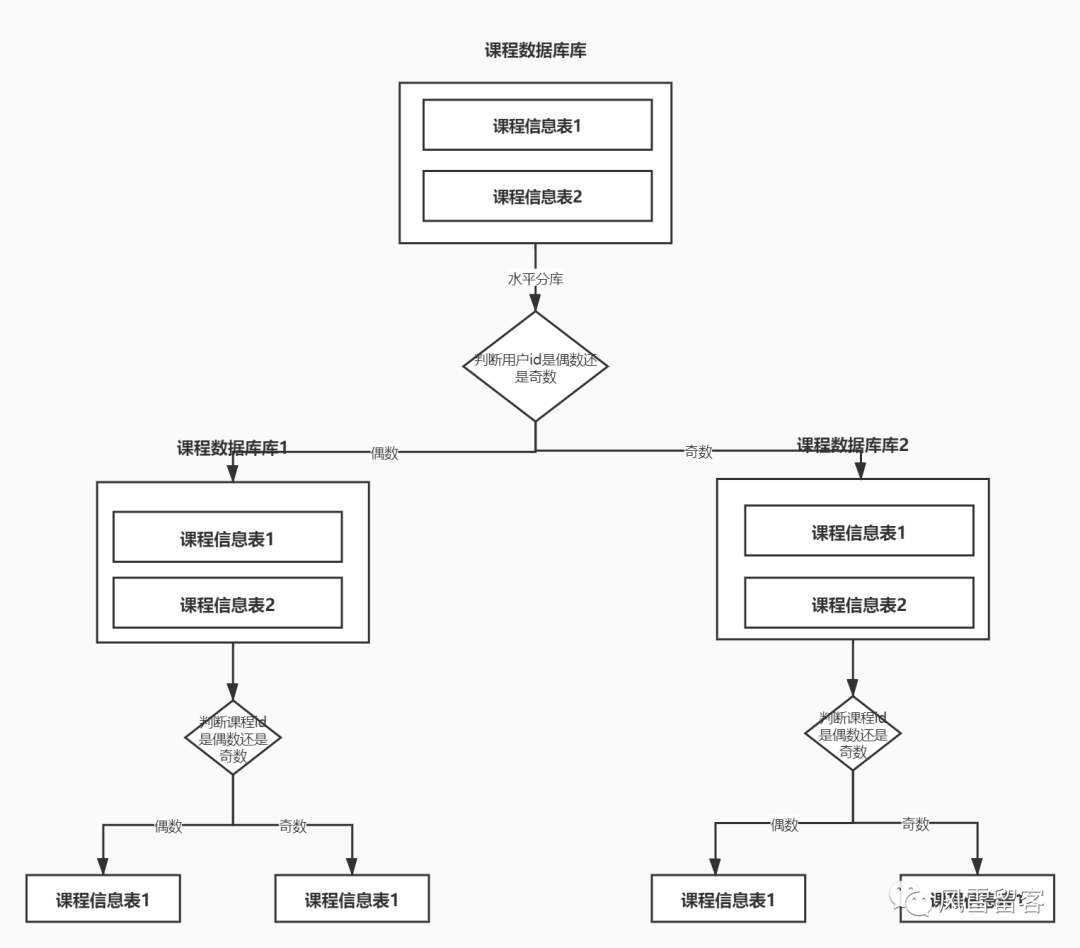
1. 创建数据库和表:
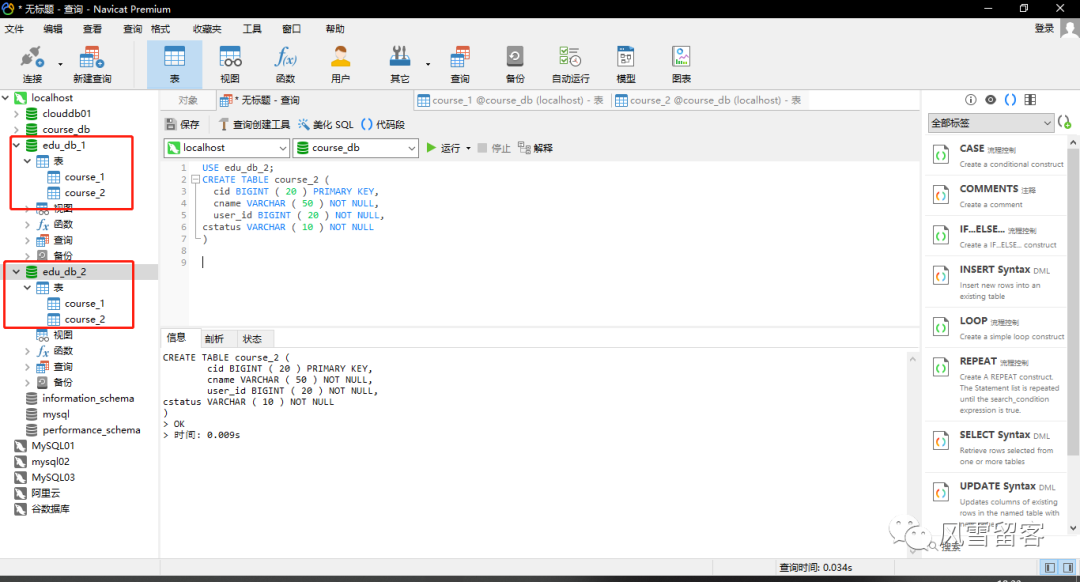
2. 在配置文件配置数据库分片规则:
#数据源名称,多数据源以逗号分隔spring.shardingsphere.datasource.names=ds0,ds1#数据库连接池类名称spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.ds0.username=root#数据库密码spring.shardingsphere.datasource.ds0.password=123456#数据库连接池类名称spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.ds1.username=root#数据库密码spring.shardingsphere.datasource.ds1.password=123456##由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,指定course表分布情况,配置表在哪个数据库里面,表名称都是什么# tables.course course表规则, 通过官方文档我们也能看出tables.<logic-table-name> 我们的数据库表都为course_1 和 course_2 ,都是以course开头,因此,填写时需要注意#我们现在有两个数据库,ds0和ds1, 表有course_1,course_2 因此,需要这样配置 ds$->{1..2} 指定ds开头的数据库,{1..2}有2和2, course_$->{1..2},表有course_开头的表,$->{1..2}有1和2spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds$->{0..1}.course_$->{1..2}# 指定course表里面主键 cid#tables.course course 表示表的规则,可以理解为以什么开头spring.shardingsphere.sharding.tables.course.key-generator.column=cid#生成策略 SNOWFLAKE 基于雪花算法,随机生成唯一的数字spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE# 指定分片策略 以cid主键分片spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid#约定 cid值偶数添加到course_1表,如果cid是奇数添加到 course_2表#因为我们的表名称为1和2 cid % 2 这样取余会出现问题,因此我们取余之后加一, 比如我们 id为2 取余为0 ,加一为1,存放到1表,如果不为偶数,就在表2添加数据,当然,如果你把表明改为0和1,可不做加一运行算spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}# 打开sql输出日志spring.shardingsphere.props.sql.show=true# 指定数据库分片策略 约定user_id是偶数添加 ds0,是奇数添加ds1#sharding.default default默认的,数据库中所有表都按照这个来做,在此我们现在不使用这种方法,#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}#sharding.course 我们只针对course表中user_id的做数据库分片spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=user_idspring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}spring.main.allow-bean-definition-overriding=true
3. 编写代码测试:
@Testpublic void addCourse() {Course course = new Course();course.setCname("java从入门到摔门").setUserId(1L).setCstatus("normal");courseMapper.insert(course);}
4. 查看控制台日志:
ShardingSphere-SQL : Actual SQL: ds1 ::: INSERT INTO course_1 (cid, cname, user_id, cstatus) VALUES (?, ?, ?, ?) ::: [1289886051566223362, java从入门到摔门, 1, normal]
我们根据代码可知,UserId为1,是奇数,应该在ds1数据库中,cid为偶数,则在ds数据库中的course_1里面.
5. 查看表:
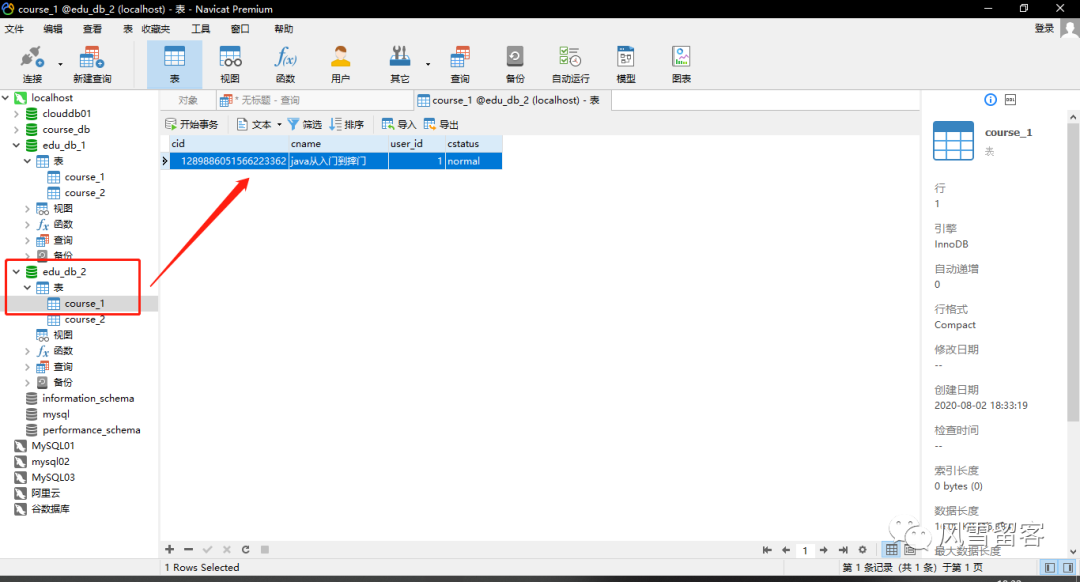
成功.
测试UserId偶数情况下的结果:
ShardingSphere-SQL : Actual SQL: ds0 ::: INSERT INTO course_2 (cid, cname, user_id, cstatus) VALUES (?, ?, ?, ?) ::: [1289887198192525313, java从入门到摔门, 2, normal]
查看表:
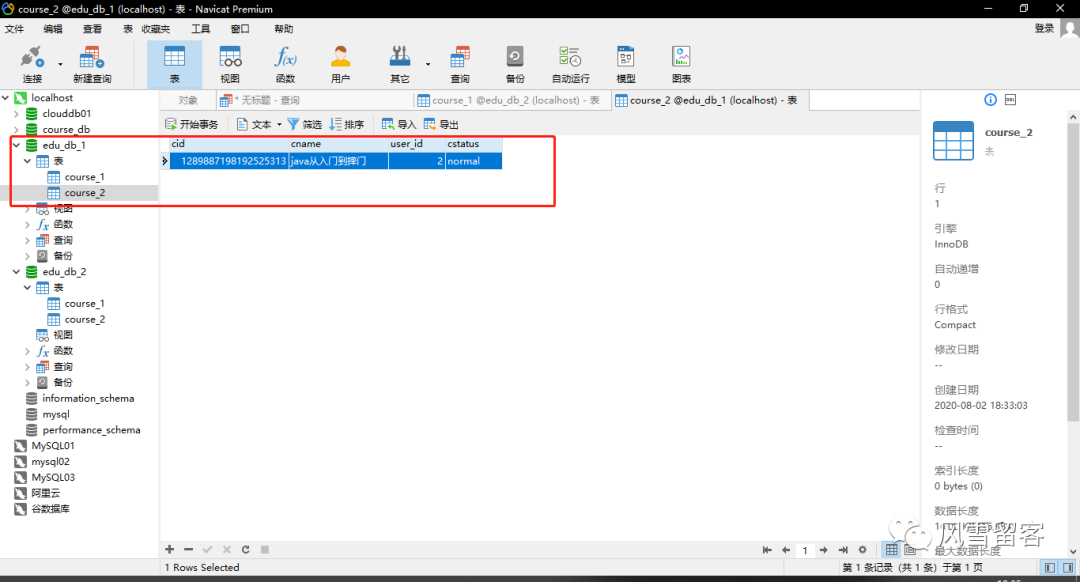
6. 测试查询:
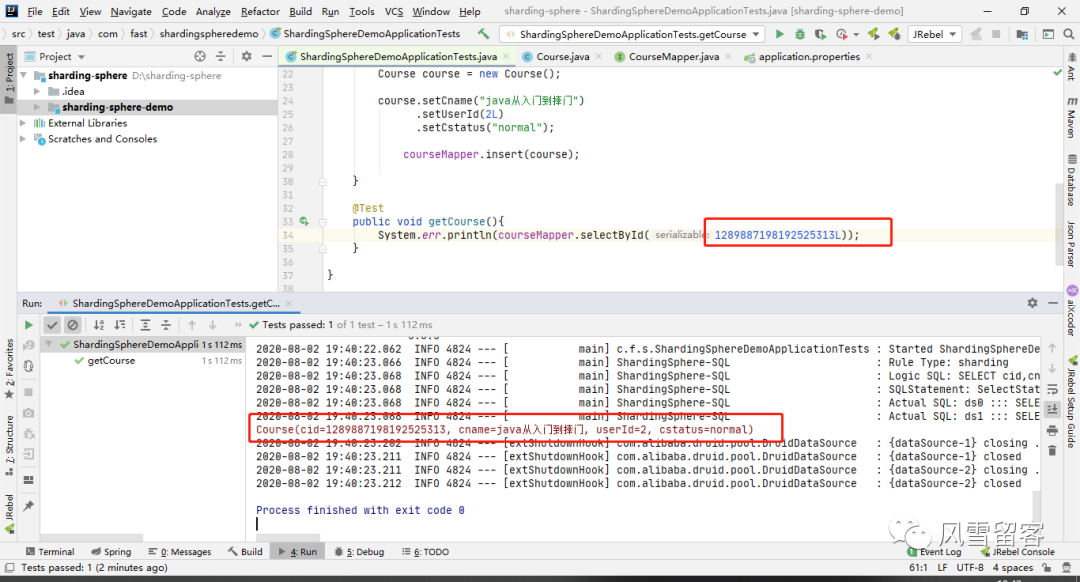
7. 拓展:
但是,我们通过日志发现一个问题:
ShardingSphere-SQL: Actual SQL: ds0 ::: SELECT cid,cname,user_id,cstatus FROM course_2 WHERE cid=? ::: [1289887198192525313]ShardingSphere-SQL: Actual SQL: ds1 ::: SELECT cid,cname,user_id,cstatus FROM course_2 WHERE cid=? ::: [1289887198192525313]Course(cid=1289887198192525313, cname=java从入门到摔门, userId=2, cstatus=normal)
该代码在ds0,ds1 中,分别查询了一次,这是为什么?先不着急,我们通过下面的代码做一个比较.
@Testpublic void getCourse(){//System.err.println(courseMapper.selectById(1289887198192525313L));QueryWrapper<Course> wrapper =new QueryWrapper<Course>();wrapper.eq("user_id",1L);wrapper.eq("cid",1289886051566223362L);Course course = courseMapper.selectOne(wrapper);System.err.println(course);}
查看日志:
ShardingSphere-SQL: Actual SQL: ds1 ::: SELECT cid,cname,user_id,cstatus FROM course_1WHERE user_id = ? AND cid = ? ::: [1, 1289886051566223362]Course(cid=1289886051566223362, cname=java从入门到摔门, userId=1, cstatus=normal)
通过对比我们不难发现,第二次只在一个数据库进行了查询,原因为我们刚开始查询的时候,并没有指定user_id的值,Sharding-jdbc无法确定在哪个数据库进行查询,只好分别查询一次.
看到这里,可能有小伙伴会问,你将数据库分片规则改为以cid取余的结果进行分片不就好了嘛,其实可以改,代码如下:
spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=cidspring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=ds$->{cid % 2}
这样的话,其实是有一个问题的,假如cid的值为偶数,那么就会把数据存入ds0数据库中,并且,将数据放在course_2中,但是,ds0中的course_2表根据规则,只有在cid为奇数的时候才会存放数据,但是cid为奇数,就会存入到ds1数据库中.course_2将永远不可能存入数据,那么表的分片规则就永远不会生效,这样也就没了意义.
五. 使用Sharding-JDBC实现垂直分库:
通过垂直分库的示意图我们可以了解到,垂直分库就是将之前的单一数据库根据功能拆分成多个数据库,做到专库专用.
1. 创建user库表:
USE user_db;CREATE TABLE t_user (user_id BIGINT ( 20 ) PRIMARY KEY,user_name VARCHAR ( 100 ) NOT NULL,ustatus VARCHAR ( 50 ) NOT NULL)
2. 创建User 实体类:
@Data@Accessors(chain = true) //链式写法 .set .set@TableName(value="t_user") //指定表名,不然我们实体类叫User,表叫t_user,会导致找不到表.public class User {@TableIdprivate Long userId;private String userName;private String ustatus;}
3. 创建UserMapper:
@Repositorypublic interface UserMapper extends BaseMapper<User> {}
4. 配置垂直切分策略:
#配置太长,以下只是更改或者添加的内容:#数据源名称,多数据源以逗号分隔spring.shardingsphere.datasource.names=ds0,ds1,ds2#数据库连接池类名称spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.ds2.username=root#数据库密码spring.shardingsphere.datasource.ds2.password=123456#ds$->{2} 指定数据库, .t_user 指定表spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds$->{2}.t_user# 指定主键spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id#生成策略 SNOWFLAKE 基于雪花算法,随机生成唯一的数字spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE# 指定分片策略 以user_id主键分片spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id#现在我们只有一个库,就直接写t_user表即可,不用写规则spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
5. 测试:
@Testpublic void addUser() {User user = new User();user.setUserName("zhangsna").setUstatus("normal");userMapper.insert(user);}
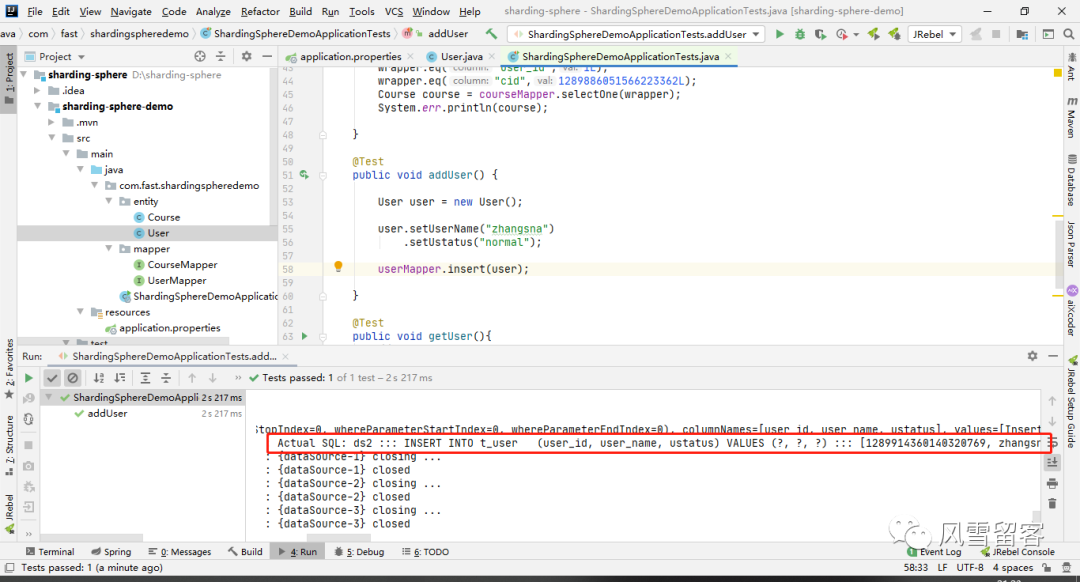
6. 查看日志:
ShardingSphere-SQL : Actual SQL: ds2 ::: INSERT INTO t_user (user_id, user_name, ustatus) VALUES (?, ?, ?) ::: [1289914360140320769, zhangsna, normal]
能根据我们配置的规则,找对对应的库和表,成功~
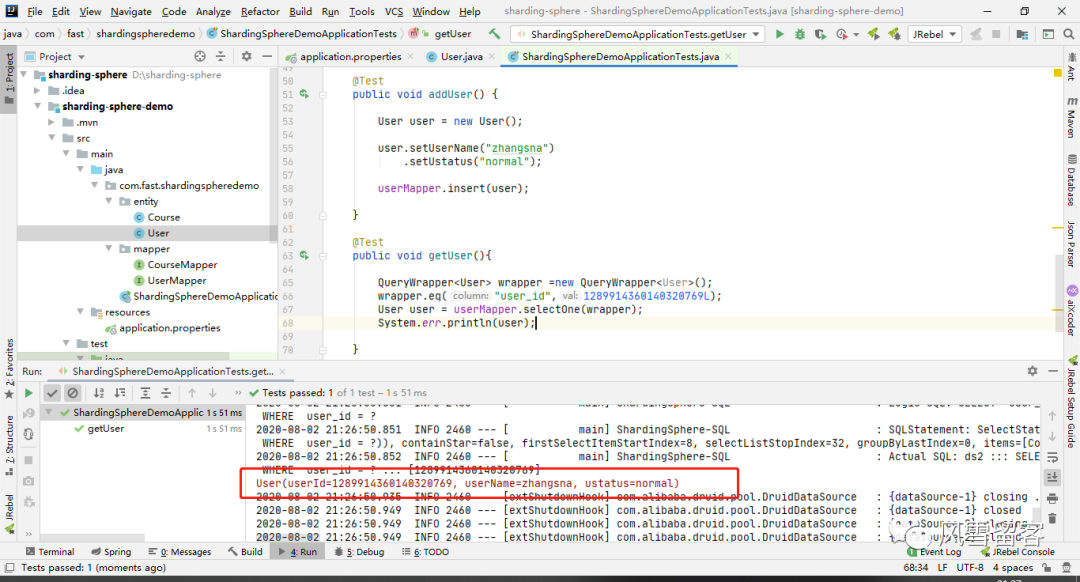
7. 测试查询:
ShardingSphere-SQL : Actual SQL: ds2 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1289914360140320769]User(userId=1289914360140320769, userName=zhangsna, ustatus=normal)
六. Sharding-JDBC 操作 公共表
1、公共表
存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
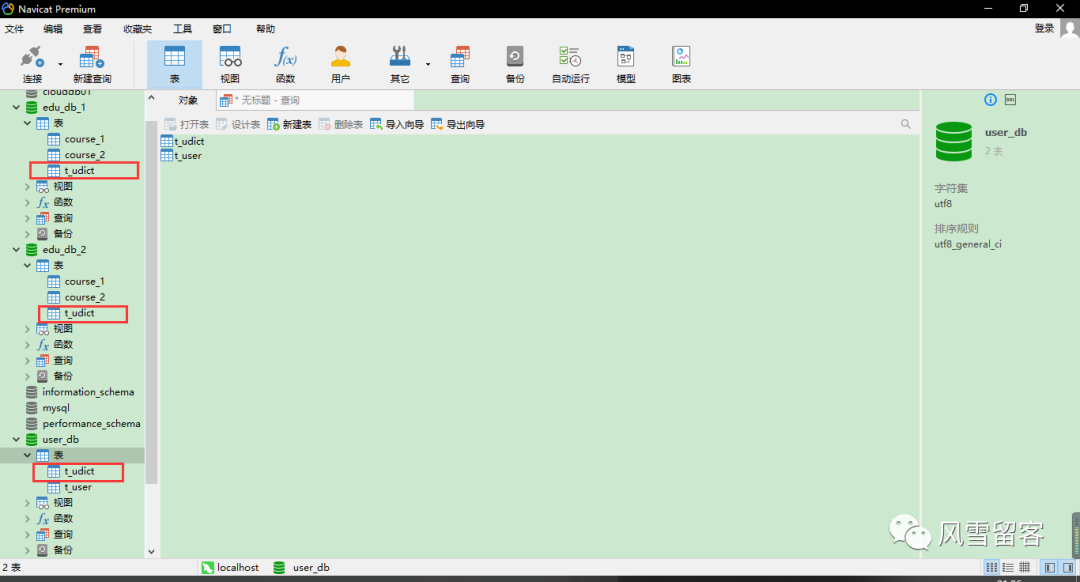
在每个数据库中创建出相同结构公共表
2、在多个数据库都创建相同结构公共表
CREATE TABLE t_udict (dictid BIGINT ( 20 ) PRIMARY KEY,ustatus VARCHAR ( 100 ) NOT NULL,uvalue VARCHAR ( 50 ) NOT NULL)
3、在项目配置文件application.properties进行公共表配置 # 配置公共表
#指定公共表spring.shardingsphere.sharding.broadcast-tables=t_udict#配置公共表id的生成策略.spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictidspring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
4. 编写实体类:
@Data@Accessors(chain = true) //链式写法 .set .set@TableName(value="t_udict") //指定表名public class Udict {private Long dictid;private String ustatus;private String uvalue;}
5. 测试:
@Testpublic void addUdict() {Udict udict = new Udict();udict.setUstatus("normal").setUvalue("已启用");udictMapper.insert(udict);}
6. 查看日志:
ShardingSphere-SQL: Actual SQL: ds0 ::: INSERT INTO t_udict (ustatus, uvalue, dictid) VALUES (?, ?, ?) ::: [normal, 已启用, 497174072799526913]ShardingSphere-SQL: Actual SQL: ds1 ::: INSERT INTO t_udict (ustatus, uvalue, dictid) VALUES (?, ?, ?) ::: [normal, 已启用, 497174072799526913]ShardingSphere-SQL : Actual SQL: ds2 ::: INSERT INTO t_udict (ustatus, uvalue, dictid) VALUES (?, ?, ?) ::: [normal, 已启用, 497174072799526913]
我们可以看到,执行插入的时候,向所有数据库中的公共表进行了插入操作;
查看: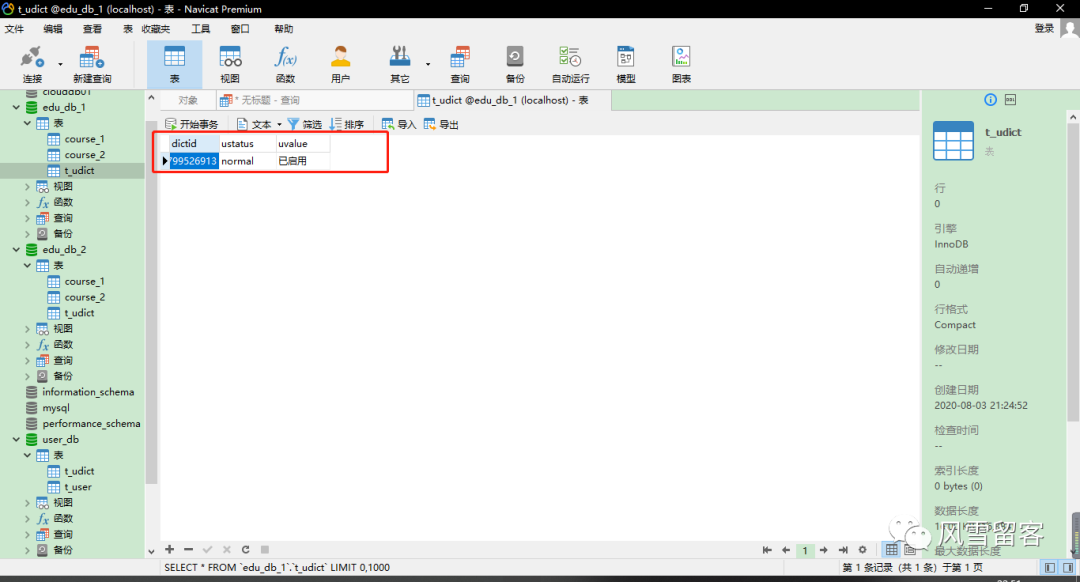
7. 测试删除:
@Testpublic void deleteUdict(){QueryWrapper<Udict> wrapper =new QueryWrapper<Udict>();wrapper.eq("dictid",497174072799526913L);udictMapper.delete(wrapper);}
8. 查看日志:
ShardingSphere-SQL: Actual SQL: ds0 ::: DELETE FROM t_udictWHERE dictid = ? ::: [497174072799526913]ShardingSphere-SQL: Actual SQL: ds1 ::: DELETE FROM t_udictWHERE dictid = ? ::: [497174072799526913]ShardingSphere-SQL: Actual SQL: ds2 ::: DELETE FROM t_udictWHERE dictid = ? ::: [497174072799526913]
9. 查看表:
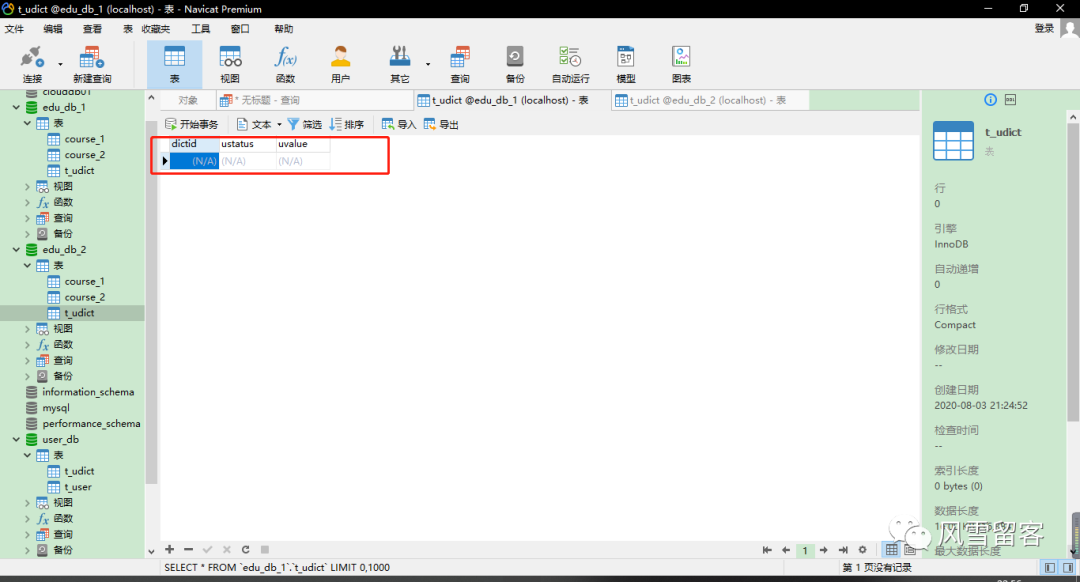
七. 使用Sharding-JDBC操作读写分离:
1. 准备工作:
我们需要两个MySQL服务器,并且配置成主从,具体的操作步骤,可以查看我另一个博文
//MySQL集群之 主从复制 主主复制 一主多从 多主一丛 实现方式https://blog.csdn.net/fengxueliuke/article/details/107538181
2. 原理:
Sharding-JDBC通过sql语句语义分析,实现读写分离过程,不会做数据同步,如下图:
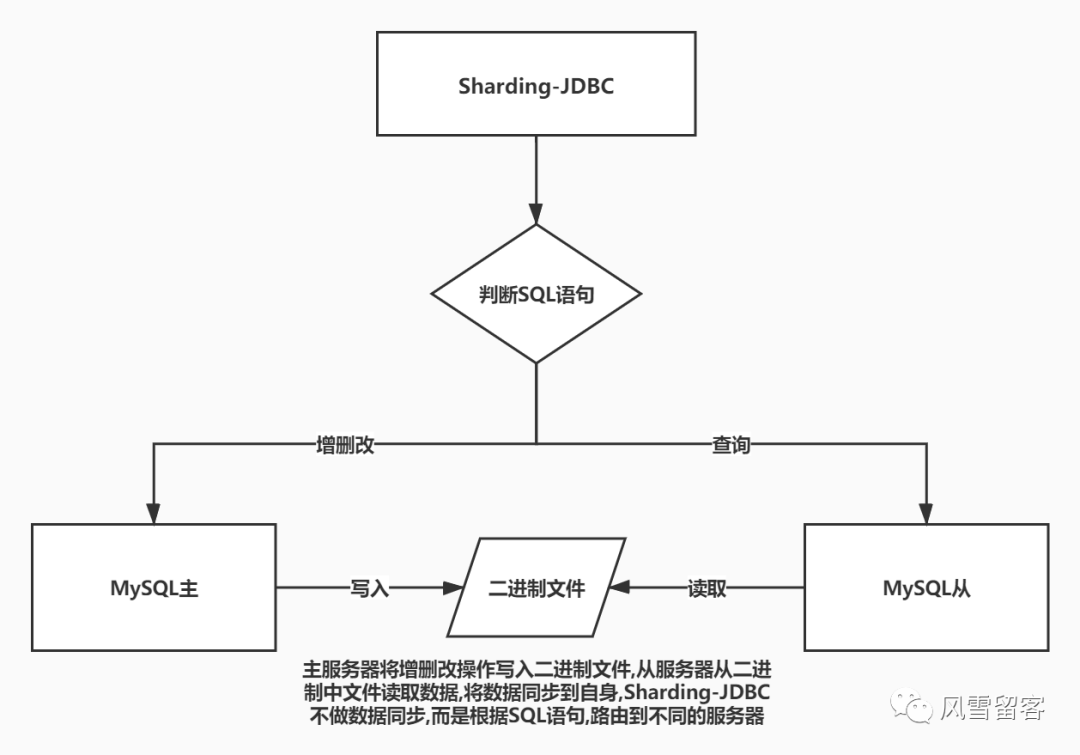
3. 修改配置文件,配置读写分离策略:
#数据源名称,多数据源以逗号分隔spring.shardingsphere.datasource.names=m0,s0,s1#数据库连接池类名称spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.m0.url=jdbc:mysql://192.168.31.100:3306/user_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.m0.username=root#数据库密码spring.shardingsphere.datasource.m0.password=@Abcd1234#数据库连接池类名称spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.31.101:3306/user_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.s0.username=root#数据库密码spring.shardingsphere.datasource.s0.password=@Abcd1234#数据库连接池类名称spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.s1.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.s1.url=jdbc:mysql://192.168.31.101:3306/user_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.s1.username=root#数据库密码spring.shardingsphere.datasource.s1.password=@Abcd1234# 主库从库逻辑数据源定义 我们主和从都是操作user_db数据库,因此我们将user_db取名为ds0为#主库数据源名称spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0#从库数据源名称spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0,s1#配置从库选择策略,提供轮询与随机,这里选择用轮询spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin#配置id的生成策略.spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_idspring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE#是否开启SQL显示spring.shardingsphere.props.sql.show=truespring.main.allow-bean-definition-overriding=true
4. 测试插入数据:
@Testpublic void addUser() {User user = new User();user.setUserName("Java从入门到秃头").setUstatus("normal");userMapper.insert(user);}
5. 查看日志:
ShardingSphere-SQL : Actual SQL: m0 ::: INSERT INTO t_user (user_id, user_name, ustatus) VALUES (?, ?, ?) ::: [1290993295410315265, Java从入门到秃头, normal]
我们通过日志可以看到,插入时在主服务器进行的,也就是m0.
6. 测试查询:
@Testpublic void getUser(){for (int i = 0; i < 10; i++) {QueryWrapper<User> wrapper =new QueryWrapper<User>();wrapper.eq("user_id",1290993295410315265L);userMapper.selectOne(wrapper);}}
7. 查看日志:
ShardingSphere-SQL: Actual SQL: s0 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s1 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s0 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s1 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s0 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s1 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s0 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s1 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s0 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]ShardingSphere-SQL: Actual SQL: s1 ::: SELECT user_id,user_name,ustatus FROM t_user WHERE user_id = ? ::: [1290993295410315265]
我们可以很明显的看到,从从服务器查询的时候,实现了负载均衡的算法.
八. 数据脱敏:
1. 介绍:
数据脱敏模块属于ShardingSphere分布式治理这一核心功能下的子功能模块。它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。在用户查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。Apache ShardingSphere分布式数据库中间件自动化&透明化了数据脱敏过程,让用户无需关注数据脱敏的实现细节,像使用普通数据那样使用脱敏数据。此外,无论是已在线业务进行脱敏改造,还是新上线业务使用脱敏功能,ShardingSphere都可以提供一套相对完善的解决方案。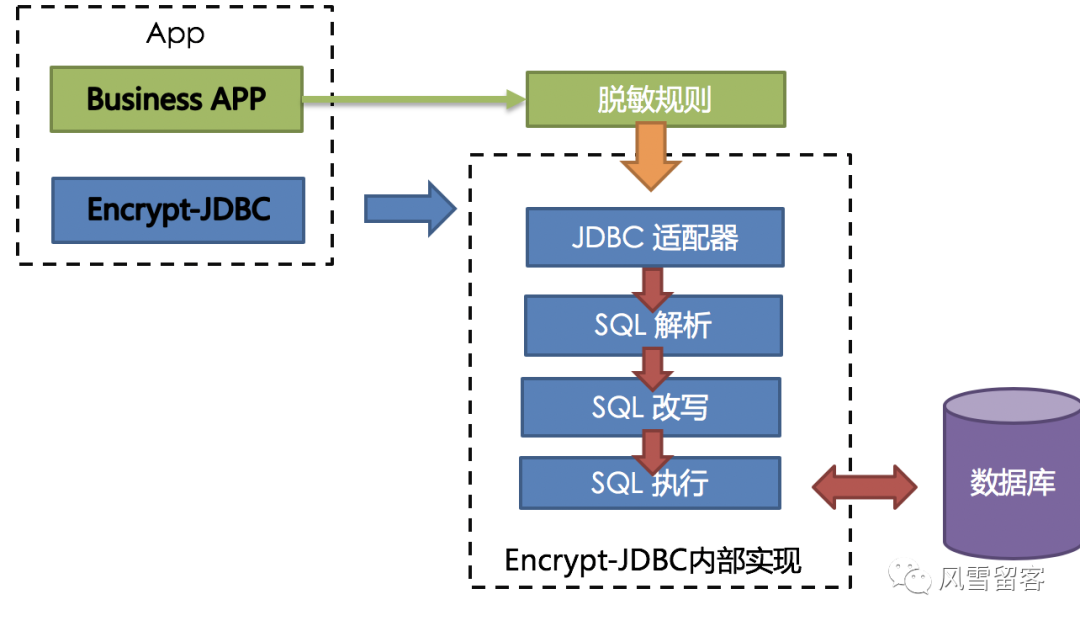
2. 配置:
#数据源名称,多数据源以逗号分隔spring.shardingsphere.datasource.names=ds0#数据库连接池类名称spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource#数据库驱动类名spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver#数据库url连接spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8#数据库用户名spring.shardingsphere.datasource.ds0.username=root#数据库密码spring.shardingsphere.datasource.ds0.password=123456spring.shardingsphere.encrypt.encryptors.encryptor_aes.type=aesspring.shardingsphere.encrypt.encryptors.encryptor_aes.props.aes.key.value=123456abcd#指定需要加密的列spring.shardingsphere.encrypt.encryptors.encryptor_aes.qualifiedColumns=t_user.password,t_user.name,t_user.idNumber,t_user.phonespring.shardingsphere.props.sql.show=truespring.shardingsphere.props.query.with.cipher.column=truespring.main.allow-bean-definition-overriding=true
3. 创建实体类:
@Data@Accessors(chain = true) //链式写法 .set .set@TableName(value="t_user") //指定表名public class User {@TableIdprivate Long userId;private String name;private String idNumber;private String password;private String phone;}
4. 插入测试:
@Testpublic void addUser() {User user = new User();user.setPassword("123456").setName("张三").setIdNumber("111111111111111111").setPhone("123456789");userMapper.insert(user);}
5. 查看表:

我们可以看到,明文数据被转成了密文进行存储.
6. 测试查询:
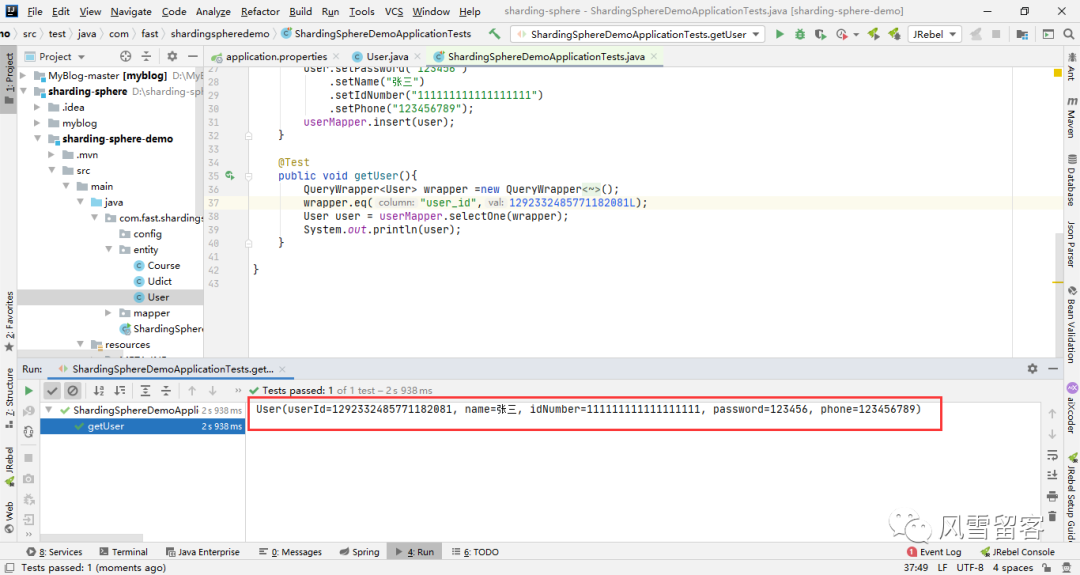
查询的时候,密文数据被转换成了明文数据.
其实还能将明文和密文一起存储,但是我无论如何设置,都只能保存密文,在此,如何有哪位小伙伴实现了这种方式,欢迎私信探讨,一起学习~~
