




在分布式场景下,比如订单系统,订单的ID需要我们使用分布式ID生成策略。
常见的分布式ID生成方法包括:
(1)UUID,UUID是JDK自带的一种ID生成方式,它是一种不重复的随机ID生成方案,但是这种ID不是自增的。
(2)Redis方式,每次需要生成一个ID,就去Redis获取一下。
(3)Oracle数据库。Oracle中有一种与表无关的数据库对象,可以获取自增ID。
(4)SnowFlake算法。这是程序自己实现的一种ID生成算法,也是一种开源的方案。
SnowFlake算法来源于Twitter的开源代码,可以去这个地址下载
(https://github.com/twitter-archive/snowflake)。
下面,我们来看看SnowFlake算法原理。
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:

1位
,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
41位
,用来记录时间戳(毫秒)。
10位
,用来记录工作机器id。注意,这里有5位表示datecenterId,另外5位表示workerId。也就是可以区分不同的机器产生的ID都是不同的。datecenterId可以想象成一台机器上的若干数据库(订单要写入数据库)。
12位
,序列号,用来记录同毫秒内产生的不同id。
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以保证:所有生成的id按时间趋势递增、整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)。
使用案例
下面我们来看看怎么使用这个算法,这里我直接使用开源的算法实现类IdWorker。
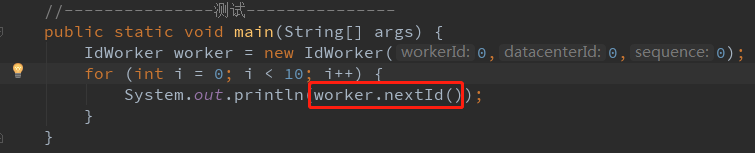
输出结果为:

这里设定的workerId=0,datacenterId=0,sequence=0。可以看出,可以参数自增的ID号。
有趣的源码
首先看一下构造函数,构造函数的目的在于初始化workerId,datacenterId,sequence等参数,并进行校验。
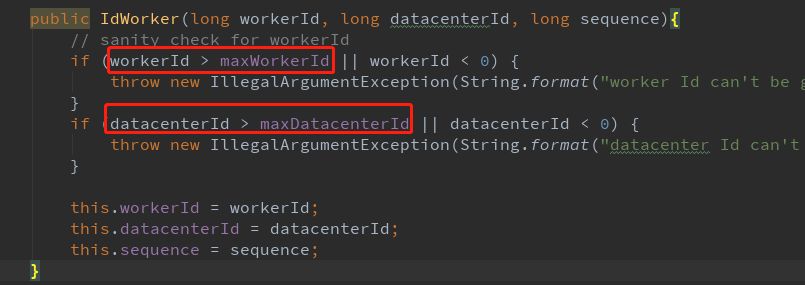
我们看到,上面代码里面有个判断workID是否大于maxWorkerID。

这里的maxWorkerID是通过位操作来计算5bit的workerID能表示的最大数 。计算如下:

在nextID方法中,有个sequence=(sequence+1)&sequence。
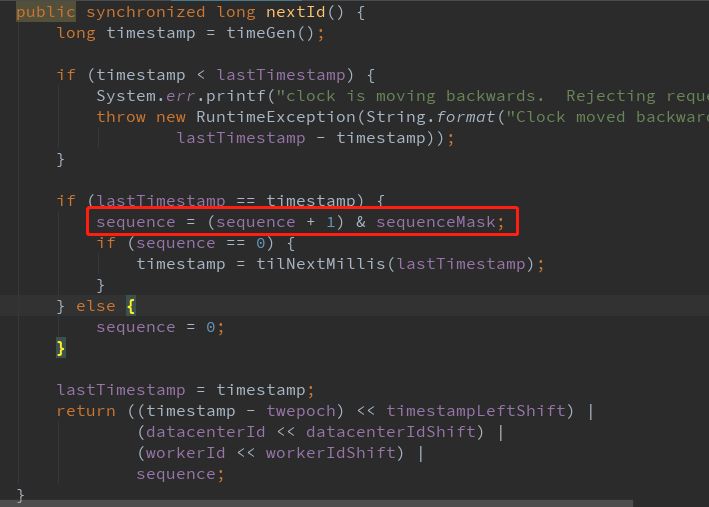
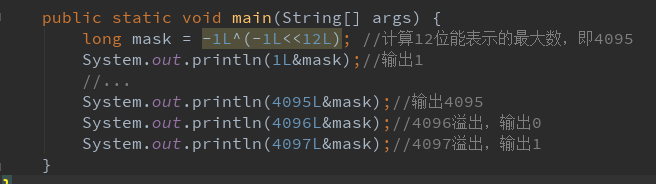
private long sequenceMask = -1L ^ (-1L << sequenceBits);
这里sequenceMask表示的是12bit表示的最大数,也就是4095.上面的代码目的是防止溢出。
我们可以演示一下:
此外,nextID方法中最后返回结果的时候,还是位运算,目的是将4个数据合成一个数据(即定义的数据结构)输出,可以自己动手试试看。

总结
总的来说,代码其实不复杂。但是代码里面蕴含了许多有趣的技巧,我们可以学习一下。在理解了这个算法之后,其实还有一些扩展的事情可以做:
1、根据自己业务修改每个位段存储的信息。算法是通用的,可以根据自己需求适当调整每段的大小以及存储的信息。
2、解密id,由于id的每段都保存了特定的信息,所以拿到一个id,应该可以尝试反推出原始的每个段的信息。反推出的信息可以帮助我们分析。比如作为订单,可以知道该订单的生成日期,负责处理的数据中心等等。
