




1、Htpp协议的工作原理。
当在浏览器输入一个WWW地址,这个是一个URL,也叫统一资源定位符。浏览器会把这个URL域名发送给DNS,DNS会解析得到IP地址。
Http协议基于TCP协议,首先会建立连接,也就是TCP连接的三次握手。目前大部分使用的Htpp协议为1.1版本,默认开启了TCP底层的keep-alive检测机制,这样建立TCP连接就可以多次复用。
2、Http协议帧结构如何?
Http协议报文大概分为三部分。分别为请求行、请求首部,正文实体。
请求首部往往保存了一些重要的字段,这些字段都是key-value类型的。比如Accept-Charset,表示客户端可以接受的字符集。还有比如Content-Type用于保存正文的格式,比如Json格式或其他格式。还有Cache-control用于控制缓存(缓存的目的是为了每次访问同一个页面,不用每次下载静态资源,从而降低服务器压力,也提高用户体验。),当客户端发送的请求中包含max-age,当该值比缓存的时间大,则更新缓存。否则不更新本地缓存,也就不要向服务器请求下载资源了。
第三部分正文,这个没什么好说的,是html或json对象,按照正常的处理即可。
3、Http协议的几种操作方式?
4、Http的版本1.1和2.0有哪些优化?
在Http1.1版本,应用层以纯文本形式进行通信,每次都需要携带完整的http头,这样在实时性和并发性上有问题。
Http2.0对Http头进行了压缩,将每次需要携带的大量key-value在两端建立索引表,相同的头只发送索引即可。Http2.0还将传输信息切割为更小的流和帧,分为head帧和Data帧,并对这些二进制进行编码优化(你可以想象Protobuf序列化可以压缩空间)。这里的Data流可以将请求分到不同的流中,就处理了Http1.1中串行的问题。比如下面这个例子:
在Http1.1中,如果请求几个资源,可能需要服务器进行一一响应。而在Http2.0中,多个资源的请求可以同时发送给服务端,服务端可以不按顺序进行一对一对应。
那么什么是队首阻塞呢,又如何解决呢。
4、Http协议如何解决队首阻塞的?
在Http1.0协议里面,所有http1.0的请求放到客户端队列,当前一个请求收到响应了才会发送下一个请求,这时候队首的阻塞发生在客户端。
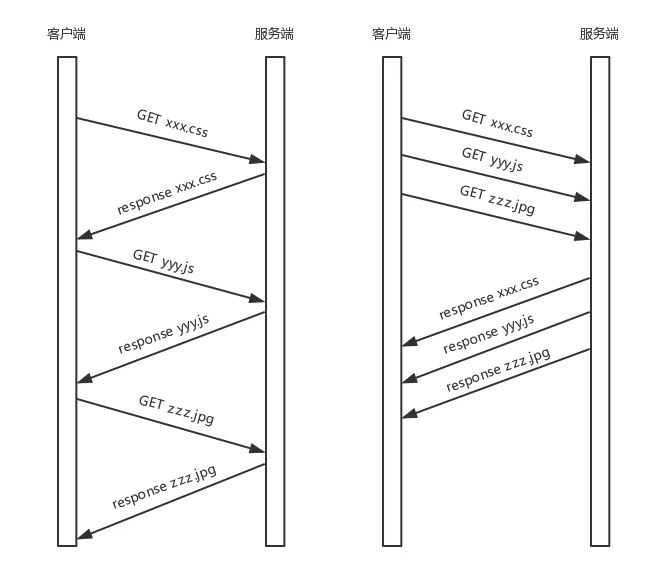
而在Http1.1协议里面规定,服务器端的响应的发送需要根据请求被接收的顺序排队,也就是先接受的请求需要最先发送响应。假如分别请求三个资源,如下面的xxx.css文件,yyy.js文件和zzz.jpg文件,假如xxx.css文件,Http按顺序发送了这三个请求,假如第一个xxx.css文件的响应在服务器端处理的较长,这时候会影响后续可能已经处理好的响应正常发送,这就造成了“队首阻塞”在服务器端。
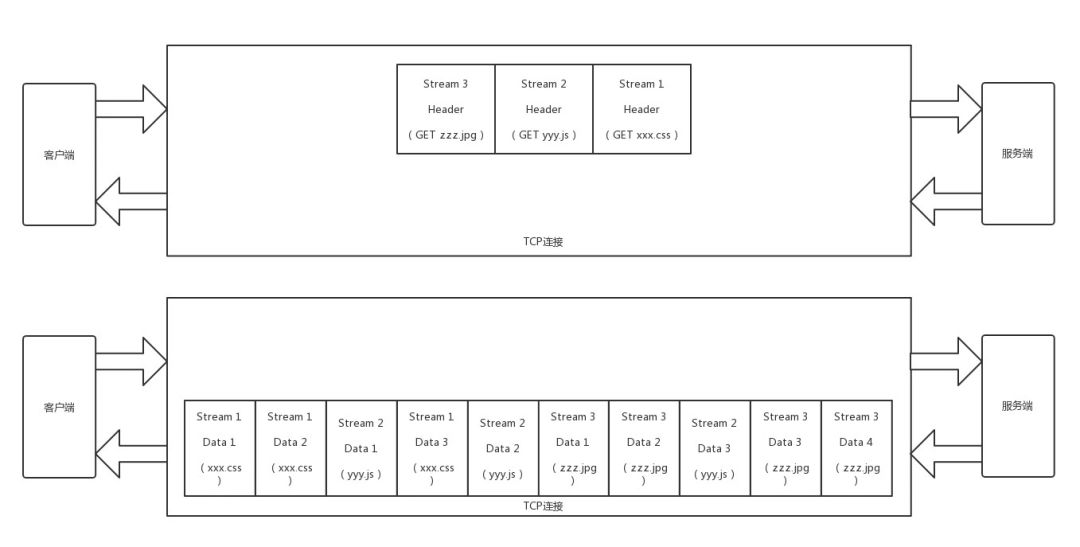
在Http2.0中,无论在服务器端还是客户端都不需要排队,在同一个tcp连接上有多个stream,各个stream发送请求和响应互相独立,互相不阻塞。只要tcp在空闲的时候就发送已经生成的request或response,两端都不用等,就解决了http协议层的“队首”阻塞问题。而且http2.0可以拆分更细的stream流,如上图所示。
当然了,底层TCP要是丢包,接收的数据还是无法提供给应用层,那么就是TCP层面的问题了。由此,google提出了一种新的,基于UDP的“QUIC协议”。
5、为什么出现QUIC协议?
Http2.0虽然增加了并发性,但是TCP底层还是严格按照顺序处理接收的包。当其中一个数据包遇到问题,后续的包都无法提供给应用层处理。于是,目前google提出了一种基于UDP实现的自定义的协议,叫QUIC。后续有空将介绍一下QUIC协议。
