




《Kafka权威指南》整理。
这本书很细致,将生产者和消费者的连接代码和详细的配置都列出来了,是一本入门的介绍书籍;后面几章节对于Kafka的内部原理也介绍了,又像是一本高级教程和运维手册。但是读完总是感觉有点散乱的感觉,知识点很多但感觉自己抓不住重点。可能是认识的还不够。
Kafka如何进行复制
Kafka如何处理生产和消费请求
Kafka如何存储
1、Kafka的集群成员
Kafka使用zk维护集成成员的信息。每个broker有一个唯一的标识符。broker启动的时候,它通过创建临时节点把自己的ID注册到zk(一个路径,/brokers/ids,zk的机制路径唯一)。broker停机、网络分区或者长时间垃圾回收STW时,broker会从zk上断开连接,创建的临时节点自动摘除(临时节点的生命周期与会话绑定啊),Kafka集群会监听到这个事件。
关闭broker时,zk的临时节点也会消失,但是这个ID可能还会存在其他的数据结构中(主题的副本列表),如果这个时候用相同的ID启动全新的broker后,它会加入集群接手原来broker的分区和主题。
控制器
Kafka集群众多的broker,有一个broker担任控制器的角色,负责主分区的选举。
如何成为控制器?
集群第一个启动的broker通过在zk里创建一个临时节点/controller成为控制器(路径唯一,其他的创建不了了,就知道已经存在控制器了)。每个新选出来的控制器通过zk获得全新的、数值更大的controller epoch(zk 的周期),其他broker在知道当前controller epoch后,如果收到旧的epoch信息会忽略。
总结:Kafka使用zk的临时节点来选举控制器,并在节点加入集群或退出集群时通知控制器。控制器在节点加入或离开集群时进行主分区选举。控制器使用epoch来避免脑裂。
2、复制机制
复制功能是Kafka架构的核心。Kafka是一个分布式、可分区的、可复制的提交日志服务。复制机制保障Kafka在节点失效时的可用性和持久性。
副本(Replica)
Kafka使用主题来组织数据,主题分为多个分区,分区有多个副本,副本保存在不同broker上。副本分为两种:首领副本和跟随者副本。通常我称呼它们为主分区和副本分区。
主分区处理所有生产者和消费者的请求(类比:zk的主节点,es的主分片)。副本分区不处理客户端的请求,它们从主分区复制消息,保持与主分区一致状态(热备)。
同步副本
如果副本分区在10s内没有请求消息或者没有请求最新数据,那它就与主分区不同步,这种主分区失效时不能晋升。持续请求并得到最新消息的副本称为同步副本。
副本分区的正常不活跃时间或称为不同步副本之前的时间通过replica.lag.time.max.ms配置,就是上面说的10s。
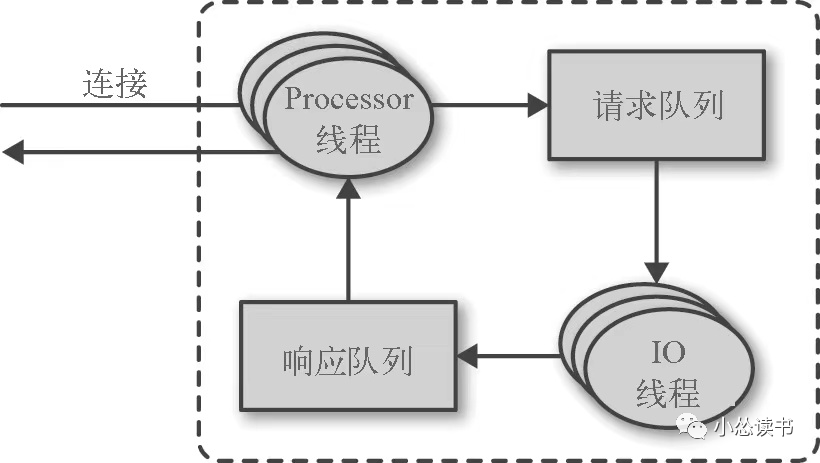
3、请求处理
broker会在它所监听的每一个端口上运行一个Acceptor线程,这个线程创建一个连接,并把它交给Processor线程(网络线程)处理,Processor从客户端获取请求消息放到请求队列,从响应队列中获取消息返回。
生产请求:生产者发送的请求,包含客户端要写入broker的消息。
获取请求:消费者、副本分区需要从broker读取消息时发送的请求。
这些请求都必须发送到主分区处理,如果broker收到的是针对特定分区的请求,这个特定分区的Leader在另一个broker,则报错(非分区首领错误)。Kafka客户端要自己负责把生产请求和获取请求发送到正确的broker上。
这怎么知道如何发送?
客户端发送一种元数据请求,请求包含客户端感兴趣的主题列表。服务端响应信息指明这些主题包含的分区、分区的副本以及首领副本是哪个。元数据请求可以发送任意broker(都存了这些信息),客户端就需要时不时的刷新这部分数据,比如在新broker加入、副本移动等这些变化要感知到。
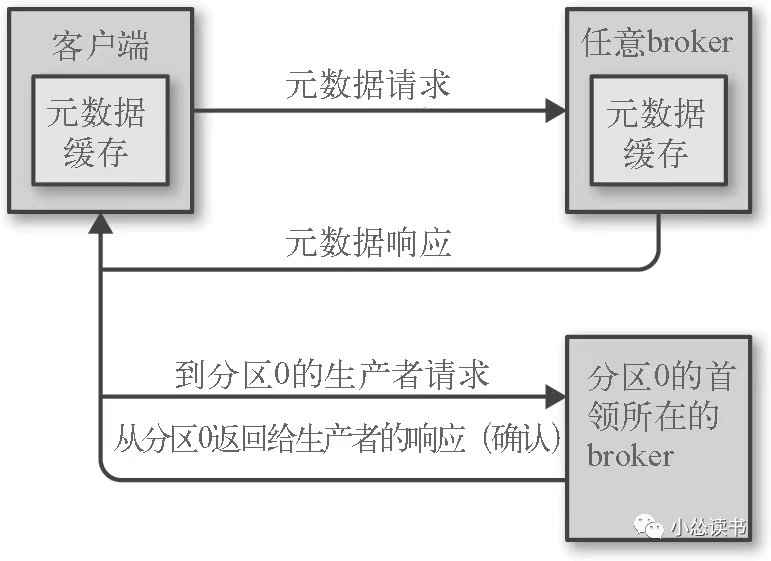
如果客户端收到“非首领”错误,它会再重发请求前先刷新元数据。
1)生产请求
之前提到过配置生产者时有个ack参数指定需要多少个broker确认才认为一个消息写入成功。acks=1,主分区写入即可;acks=all,所有分区都写入;acks=0,生产者只管发。
生产者发送的消息被写到系统缓存中,最终被写入到本地磁盘中(复制机制)。
2)获取请求
请求到达指定的分区首领(客户端自己保证请求路由正确),首领(注:首领就是主分区)检查请求时效,例如指定的偏移量在分区是否存在等。
Kafka使用零复制技术向客户端发送消息。
Kafka直接把消息从文件(Linux文件系统缓存)里发送到网络中,不经过任何中间缓冲区。这就是零复制机制(其他数据库在返回数据时会先保存在本地缓存中)。
客户端可以设置broker返回数据的上下限,例如告诉broker,有10KB数据再返回,流量不大时减少网络IO次数。该流程如下所示。
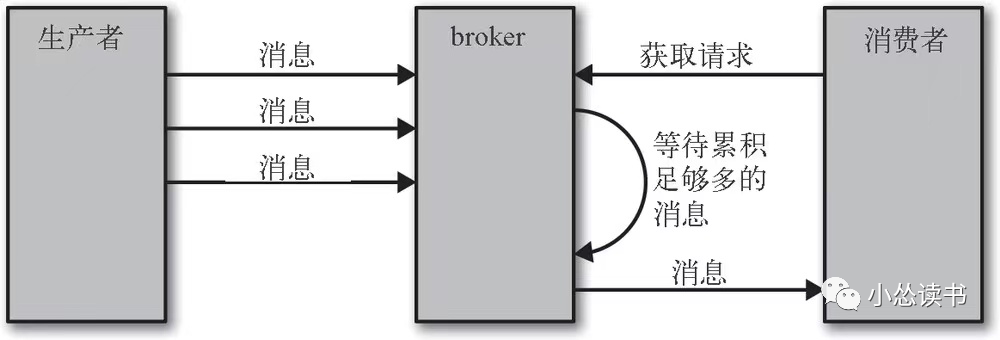
或者设置一个超时时间,告诉broker没有10KB,你到时间也给我数据吧。
并不是所有保存在主分区上的数据都可以被客户端读取!
客户端只能读取已经被写入到所有同步副本的消息,没有写到所有同步副本的数据不会返给消费者。因为Kafka认为这种情况是不安全的,如果主分区发生奔溃,另一个同步副本晋升后消息会丢失。如下图所示。
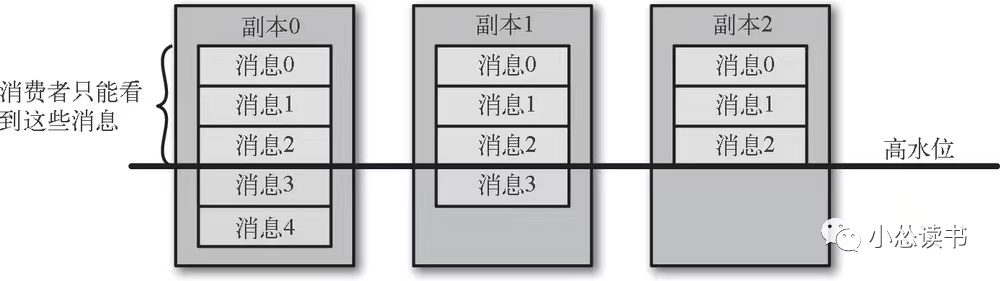
如果broker之间的消息复制因为某些原因变慢,那么消息到达消费者时间也会随着变长(影响消费者获取消息的延迟因素!!!)
4、数据存储
Kafka的基本存储单元是分区。分区无法在多个broker之间细分,也无法在同一个broker的多个磁盘上细分(说明一个挂载点(挂多个盘或一个盘)就是一个分区,而不能多块盘、多个broker构成一个分区)。
1)分区分配
Kafka如何在多个broker上分配分区,加入有6个broker,想创建10个partition,并设置3副本?要保证如下的目标。
平均分布
副本分布不同的broker
broker指定机架rack情况下,尽量将副本分配不同机架的broker
很好理解。轮询方式+上述规则 => 分配。
分区分配broker完成后,需要决定这些分区使用broker上的哪个目录来存数据。为分区在broker上分配目录(一个broker有多个主题的分区,每个分区都要有存储目录的),规则如下:
计算broker上每个目录的分区数,新的分区总是被添加到数量最少的目录。
2)文件管理
Kafka为每个主题配置了数据保留期限,规定数据被删除之前可以保留多长时间,或者清理数据之前可以保留的数据量大小。
Kafka将分区分成若干个片段(这里的分区我们可以看做是一个大的文件,消息都向这个文件里写),默认每个片段包含1GB或者一周的数据,两者取min值。
写数据时,达到片段上限后,broker关闭当前文件,打开一个新的片段。
当前正在写入数据的片段叫做活跃片段,活跃片段永远不会被删除。如果要保留一天数据,但是活跃片段包含了5天,那这5天数据都会保留。
3)索引
消费者可以从Kafka的任意可用偏移量位置开始读取消息。例如,消费者读取偏移量100开始的1MB数据,那broker会先定位到偏移量100,然后再进行消息读取。这个定位过程增加了索引,Kafka为分割分区维护了一个索引。
索引把偏移量映射到片段文件和偏移量在文件里的位置
索引也分成片段,所以在删除消息时,也可以删除相应的索引
Kafka不校验索引正确性,索引出现损坏会重新生成索引(删除索引是安全,会自动生成)
4)数据清理
通常Kafka会根据设置的时间保留数据,将超过时效的旧数据清理。
每个日志片段可以分为两部分:
干净的部分
这些消息之前被清理过,每个键只有一个值,是上次清理时保留下来的。
脏数据部分
上次清理之后写入的。如下图所示。
清理的是过期数据!!!broker启动清理管理器线程和多个清理线程,这些清理线程会选择污浊率(脏数据占比)高的分区清理。
被删除的事件
如果只为每个键保留新的的消息,当删除某个特定键所对应的所有消息时,如何处理?例如,删除某个用户在系统中的所有信息。
彻底将一个键从系统中删除,应用程序需要发送一个包含该键且值为NULL的消息。清理线程发现该消息时,先进行常规清理——保留值为NULL的消息(墓碑消息)保留一段时间,时间可配置。这期间消费者可以看到这个墓碑消息并发现它的值已经被删除,如果消费者从Kafka向数据库导数据,就知道要将这个数据从数据库中删除。时间过后,清理线程会移除墓碑消息,这个键也从Kafka分区中消失。
为什么要有这个缓冲时间?
留给消费者足够的时间看到墓碑消息,因为消费者如果离线并错过墓碑消息就不知道它已经从Kafka中删除了,也不会删除自身DB的数据了。
5、数据传递
可靠的数据传递要在系统设计之初就要考虑到。可靠性是一个系统的属性,而不是一个独立的组件,考虑可靠性要从系统整体出发。
Kafka怎么保证数据传递的可靠性?
Kafka可以保证分区消息顺序。消息B在消息A之后写入,那么消息B的偏移量比A大,消费者先读到A再读B。
只有当消息被写入分区所有同步副本时(系统缓存中,不一定写入磁盘),它才被认为是已提交
只要还有一个副本活跃,已提交的消息不会丢失
消费者只能读取已提交的消息
1)复制(即副本)
复制机制和分区多副本是Kafka可靠性保证的核心。
复制机制概述:kafka主题被分为多个分区,分区是基本数据块,存储在单个磁盘上,kafka保证分区里事件有序;分区可以在线(可用),也可以离线(不可用),每个分区有多个副本,其中一个是首领(主分区);所有事件直接发送主分区,或者从主分区读取事件,其他副本分区只管与主分区同步;首领不可用时,某一个同步副本晋升。
同步副本一定要和主副本一模一样吗,之前提到过同步副本,这里再细说一番:
它需要满足以下条件才被认为是同步的。
与zk之间有一个活跃的会话(6s内有心跳,副本的broker要存活)
10s内从主分区获取过消息,并且是最新消息
6s和10s都是可配置的。
2)非同步副本
如果一个或多个副本在同步和非同步状态之间快速切换,说明集群内部出现了问题,通常是不合理的垃圾回收配置导致的。
3)复制系数(副本数)
复制系数为N,则N-1个broker失效的情况下仍可以从主题读取或写入数据;复制系数为N,也说明至少需要N个broker,占用N倍的磁盘空间。
这是可用性和存储空间的权衡。
4)不完全的主分区选举
当分区首领不可用时,一个同步副本会被选为新Leader。如果在选举过程中没有数据丢失,即提交的数据同时存在与所有的同步副本上,name这个选举就是“完全”的(所有副本都是同步的)。但如果Leader不可用时,其他副本都是不同步的,该如何?
允许不同步的副本成为Leader,承担丢失数据和不一致的风险
不允许不同步的副本成为Leader,等待原Leader恢复,可用性降低
5)最少同步副本
min.insync.replicas.
Kafka的可靠性保证定义:消息只有被写入所有同步副本后才被认为是已提交的(也就是说,并不是所有的副本都是同步副本)。如果同步副本只有一个,它不可用了,数据就丢失了。
