




1、HBase&ES
HBase是一种分布式、面向列存储的数据库

ES是基于Lucene的、分布式的搜索与数据分析引擎

2、部署架构
Hbase部署架构。
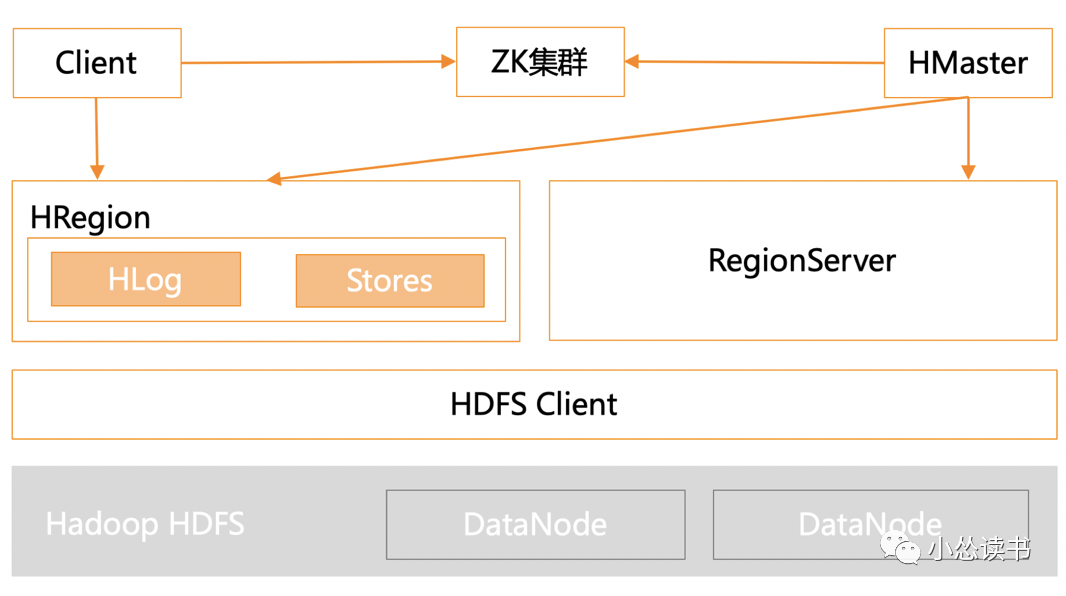
依赖zk实现master的高可用, 管理系统元数据信息, 参与RegionServer宕机恢复, 实现分布式锁依赖HDFS存储数据HMaster主要负责Hbase的各种管理工作,如用户的各种管理请求、RegionServer中Region的负载均衡、RegionServer的宕机恢复等、清理过期的日志以及文件等HRegionServer主要用来响应用户的IO请求,是Hbase中最核心的模块,除了数据的存储,数据读取和数据写入时,其他和数据相关的操作都是HRegionServer完成的
ES部署架构。
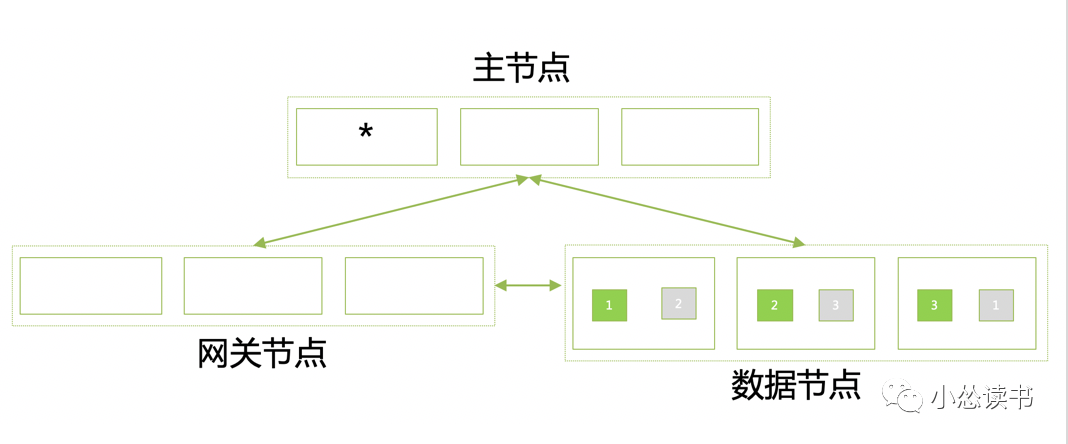
不依赖zk,ZenDiscovery实现选举基于Lucene实现的分布式存储Master节点是集群大脑,不负责数据读写,负载不高,配置不需要太高通常情况下,将网关节点也独立部署,通过配置文件指定节点类型
3、数据写入
HBase
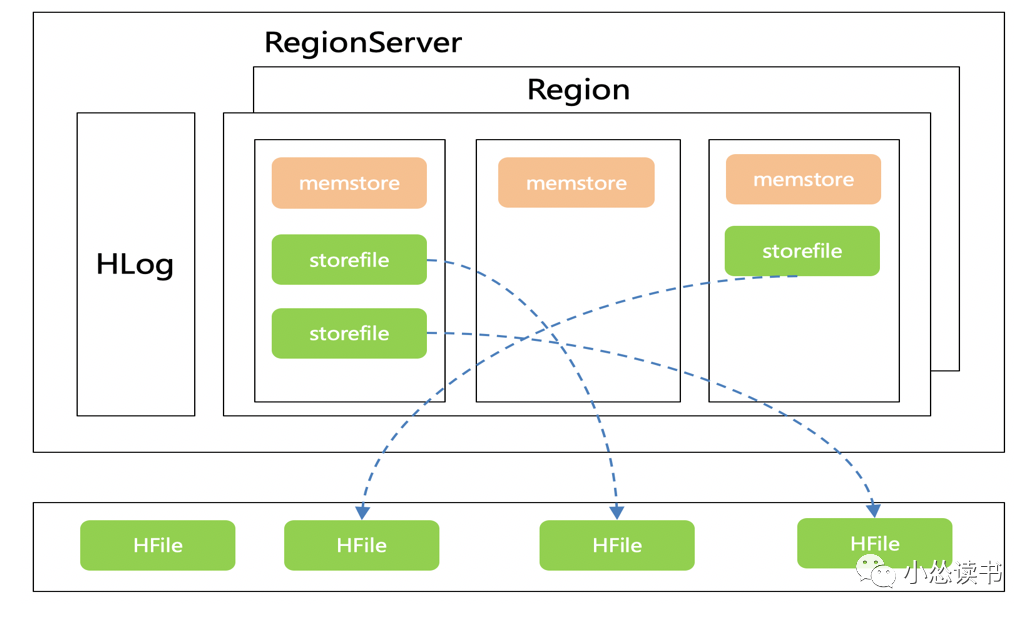
1)HbaseClient请求预处理,写入的RegionServer
2)RegionServer对数据解析,先写入HLog,再写入对应Region的Memstore中
3)Memstore超过一定的阈值后,会执行Flush操作,将内存中的数据写入文件,形成HFile
ES
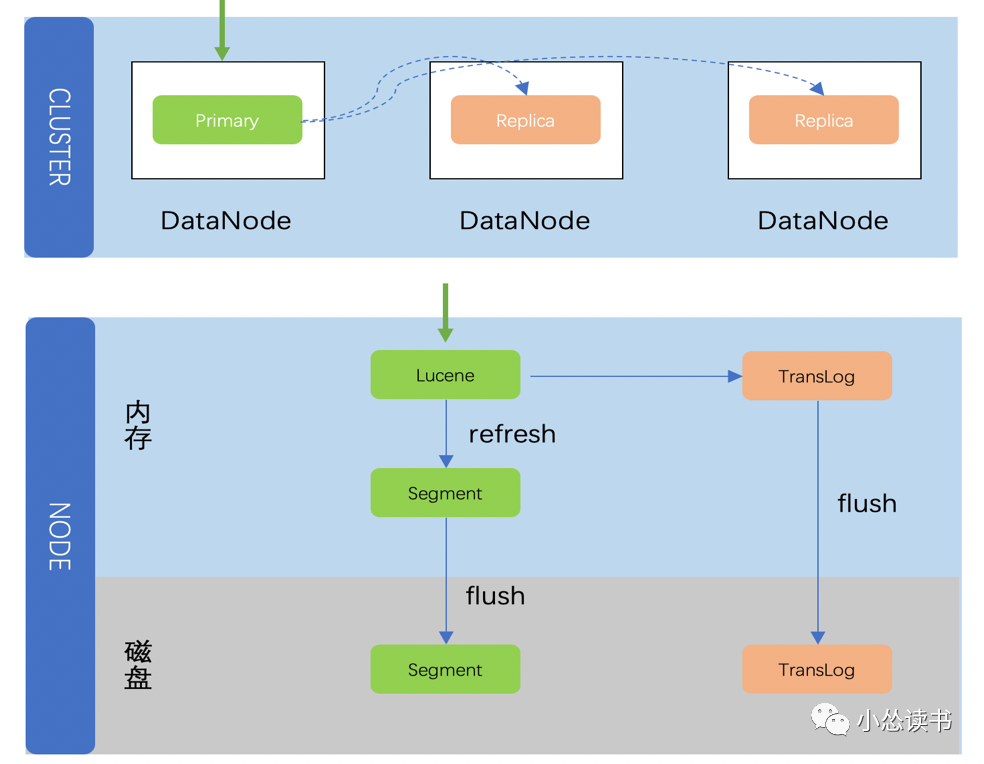
1)协调节点确定分片
2)数据节点Lucene索引构建
2)数据写入Memorybuffer中,写完索引文件之后,才会写translog
3)在Memorybuffer中的数据每隔一段时间,就会refresh到OS的文件缓存中到达一定的阈值或者indexbuffer超过设定值时,会执行Flush操作
注:这里的顺序和Hbase不一样,原因是写入Lucene时会对数据进行一些检查,可能导致Lucene写入失败。如果先写translog,Lucene检查失败时需要回滚Translog的内容。
4、数据查询
HBase
从zk获取meta地址
查找数据对应的regionserver
查询regionserver的地址
ES
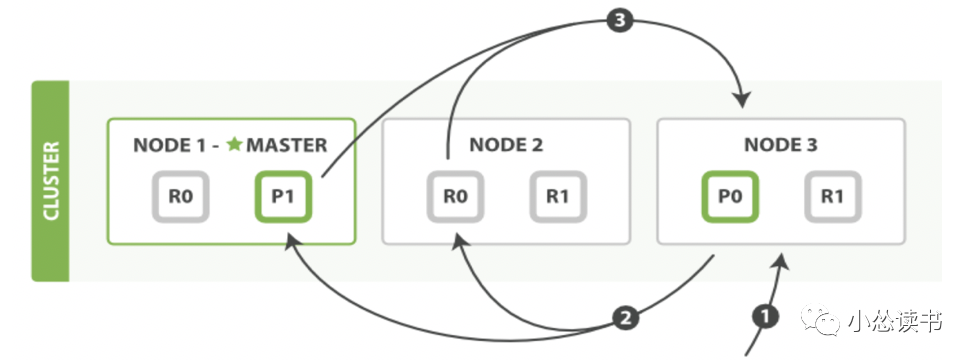
1)客户端发送一个 search 请求到 Node3 , Node3 会创建一个大小为 from+ size 的空优先队列。
2)Node3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from+ size 的本地有序优先队列中。
3)每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,也就是 Node3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
ES权威指南
5、数据合并
HBase
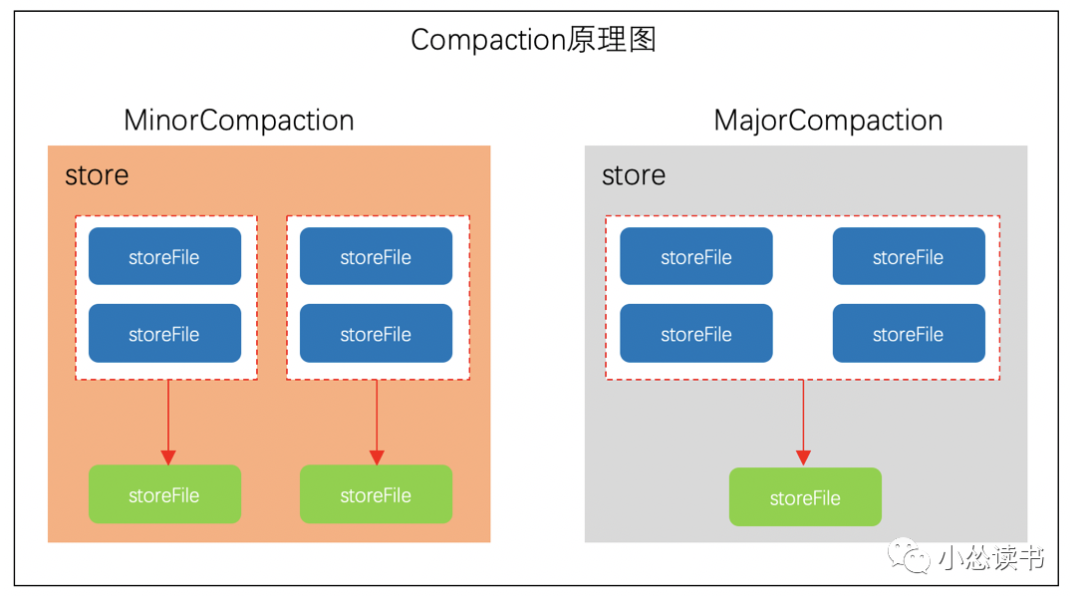
HBase不停的刷写,导致存储目录中有过多的数据文件,文件太多会导致维护困难、降低数据查询性能和效率,因此需要对数据文件进行合并,合并分为三步:排序文件、合并文件、代替原文件服务。HBase首先从待合并的文件中读出HFile中的key-value,再按照由小到大的顺序写入一个新文件(storeFile)中。这个新文件将代替所有之前的文件,对外提供服务。
Minor Compaction(小合并) & Major Compaction(大合并)
小合并是指将相邻的StoreFile合并为更大的StoreFile。大合并是将多个StoreFile合并为一个StoreFile。
ES
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
1)refresh操作会创建新的段并将段打开以供搜索
2)合并选择大小相似的段,合并成大段,不会中断索引过程
3)合并后新的段被刷新(flush)到了磁盘。 新的段被打开用来搜索。老的段被删除
6、故障容灾
HBase
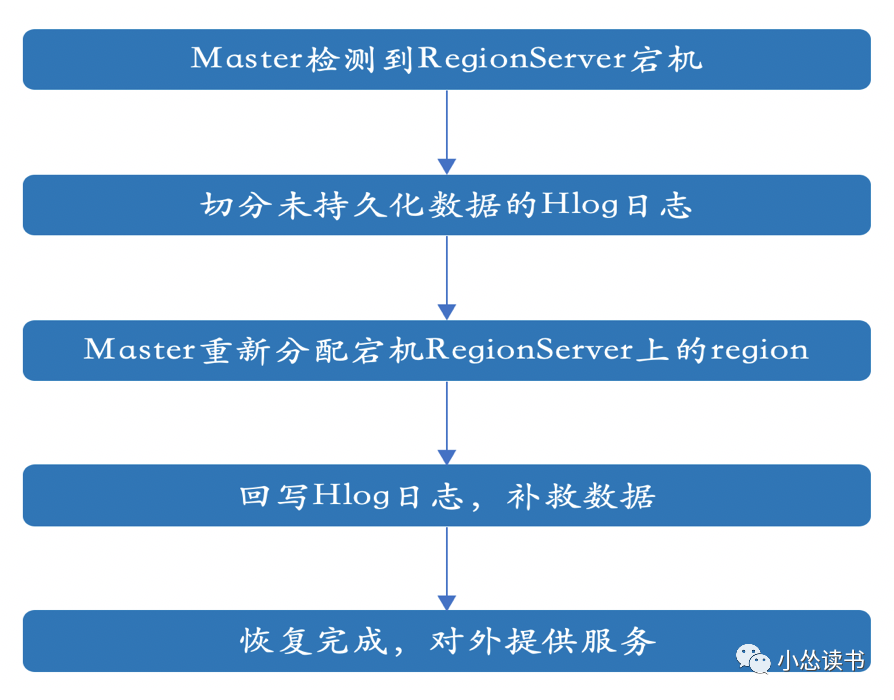
ES副本机制保证集群可容灾1台物理机宕机(1副本情况)。
7、总结
依据 | HBase | ES |
数据规模 | ✅存储海量数据,不清楚未来数据规模 | |
查询性能 | 注:数据量大的时候,查询性能降低小 | ✅ |
写入性能 | ✅ | |
复杂查询 检索功能 | ✅可视化平台、数据聚合、倒排查询、全文检索 |
数据不大,并且需要组合条件查询,选择ES
ES可以按天建索引,在存储日志等类型文件时可以考虑选择ES
数据量持续增长,并且查询比较简单的情况,选择HBase
