




2月9号的时候分享了篇Oracle针对大表在线修改的脚本,主要是使用Oracle自带的在线重定义功能,对于表结构的修改,非常的方便,强列推荐使用。
脚本下载地址:oracle大表字段类型修改在线重定义脚本.txt
最近在客户现场测试最大的24亿行记录的分区表,整个变更过程花费3个多小时,符合预期。
网上相关的文章比较多,但都只是告诉我们怎么用,对于大表环境下的坑,讲的都比较少,如下是我在一线客户现场测试上10亿的大表字段修改过程中所遇到的问题汇总及规避方法,希望能帮助到大家。
每次看大神的文章第一时间就是看看什么版本、什么环境,心心想自己的环境适用不,废话有点多,直接看配置吧。
- CPU:物理4个,每个10核心,共计80个Processor(Intel® Xeon® CPU E7-4820 v3 @ 1.90GHz)
- 内存:500 GB
- OS版本:redhat Linux release 7.5 (Maipo)。
- 存储:huawei 某型号。
- DB版本:Oracle 12c RAC nocdb(12.2.0.1.0)。
一. 简单介绍一下Oracle在线重定义
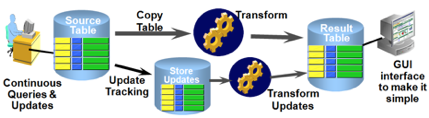
1. 在线重定义表是什么
- Oracle 支持在线重定义表,也就是说我们可以在修改表结构(DDL)的同时进行相关的DQL、DML操作,使得前端的DML根本感觉不到表结构实际上已经发生了变化,对于用户而言是完全透明的。当然在线重定义期间,前端性能会稍微有所下降。Oracle提供的重定义包dbms_redefinition即是用与完成此操作。其实质是Oracle使用了智能物化视图及物化视图日志的方式。在对象结构重组期间,表现为一个本地对象的复制,重组期间发生的任何变化都会被刷新到最新。
2. 在线重定义表的主要功能,如下:
- 修改表或簇的存储参数.
- 为表添加,修改或删除列
- 为表添加或删除分区,改变分区结构
- 增加并行查询支持
- 重建表以减少碎片
- 将堆表变为索引组织表或相反
- 普通表转为分区表
- 分区表转普通表
- 改变物化视图日志或者Streams Advanced Queuing queue 表结构
- 将表移动到相同或不同schema下不同的tablespace(如果不要求表始终可用的话,也可以直接使用alter table move 实现)
3. 支持数据库版本
- mos上查询到是支持10.2.0.4及更高版本 - Doc ID 1304838.1.
二、实施过程中需要避免的坑
- 创建临时表 - [仅创建基础表结构和注释]
临时表的表结构即是我们最终要的表结构。创建临时表时只创建基础的表和注释,不要创建索引、主键、及其它约束,针对小表可以使用COPY_TABLE_DEPENDENTS,而如果是大表建议最后开并行来跑,效率更高。因为第一次实施的时候我偷懒,直接取了原表的ddl改个名字就创建临时表,发现问题比较多,效率也慢。
如下是我创建的分区临时表。
CREATE TABLE "ENMO"."INT_ENMO_SQM" (
"MO_ID" VARCHAR2(10),
"CUST_ID" NUMBER(20),
"PROP_INST_ID" NUMBER(20), --varchar2改number
"OFFERING_INST_ID" NUMBER(20),--varchar2改number
"PROP_ID" NUMBER(20),--varchar2改number
"PROP_CODE" VARCHAR2(32),
"PROP_NAME" VARCHAR2(64),
"COMPLEX_FLAG" VARCHAR2(1),
"PROP_VALUE" VARCHAR2(512),
"P_PROP_INST_ID" NUMBER(20),--varchar2改number
"EFF_DATE" DATE,
"EXP_DATE" DATE,
"ENTITY_TYPE" VARCHAR2(2),
"ENTITY_ID" NUMBER(20),
"ENTITY_NAME" VARCHAR2(256),
"ENTITY_CODE" VARCHAR2(64),
"CREATE_DATE" DATE,
"CUSTID_INDEX" NUMBER,
"OPER_CODE" VARCHAR2(32),
"MSISDN" VARCHAR2(32),
"P_PROP_ID" NUMBER(20),--varchar2改number
"RECORD_STATUS" NUMBER(3) DEFAULT 1,
"MODIFY_DATE" DATE,
"STATUS" VARCHAR2(20)
)
PARTITION BY LIST ( "MO_ID" ) ( PARTITION "P_000" VALUES ( '000' ),
PARTITION "P_001" VALUES ( '001' ) SEGMENT CREATION DEFERRED,
PARTITION "P_002" VALUES ( '002' ),
PARTITION "P_100" VALUES ( '100' ),
PARTITION "P_200" VALUES ( '200' ),
PARTITION "P_210" VALUES ( '210' ),
PARTITION "P_220" VALUES ( '220' ),
PARTITION "P_230" VALUES ( '230' ),
PARTITION "P_240" VALUES ( '240' ),
PARTITION "P_250" VALUES ( '250' ),
PARTITION "P_270" VALUES ( '270' ),
PARTITION "P_280" VALUES ( '280' ),
PARTITION "P_290" VALUES ( '290' ),
PARTITION "P_311" VALUES ( '311' ),
PARTITION "P_351" VALUES ( '351' ),
PARTITION "P_371" VALUES ( '371' ),
PARTITION "P_431" VALUES ( '431' ),
PARTITION "P_451" VALUES ( '451' ),
PARTITION "P_471" VALUES ( '471' ),
PARTITION "P_531" VALUES ( '531' ),
PARTITION "P_551" VALUES ( '551' ),
PARTITION "P_571" VALUES ( '571' ),
PARTITION "P_591" VALUES ( '591' ),
PARTITION "P_731" VALUES ( '731' ),
PARTITION "P_771" VALUES ( '771' ),
PARTITION "P_791" VALUES ( '791' ),
PARTITION "P_851" VALUES ( '851' ),
PARTITION "P_871" VALUES ( '871' ),
PARTITION "P_891" VALUES ( '891' ),
PARTITION "P_898" VALUES ( '898' ),
PARTITION "P_931" VALUES ( '931' ),
PARTITION "P_951" VALUES ( '951' ),
PARTITION "P_971" VALUES ( '971' ),
PARTITION "P_991" VALUES ( '991' ),
PARTITION "P0" VALUES ( DEFAULT )
);
COMMENT ON COLUMN "ENMO"."INT_ENMO_SQM"."BE_ID" IS
'xxID';
COMMENT ON COLUMN "ENMO"."INT_ENMO_SQM"."CUST_ID" IS
'xxx标识';
COMMENT ON COLUMN "ENMO"."INT_ENMO_SQM"."PROP_INST_ID" IS
'xxxID';
COMMENT ON COLUMN "ENMO"."INT_ENMO_SQM"."OFFERING_INST_ID" IS
' xxxxxID';
注:我这里原表是分区表,如果原表是分区表,需要提前把分区建好,在线重定义不能直接转分区。如果是普通表想在改字段时随带改为分区表,只需要在建临时表时建好分区就行,反之也可以。
- 并行度问题
生产环境建议在业务闲时操作,如果能申请停业务最好,把硬件资源充分利用上。
非区表: 建议配置逻辑cpu的一半。
分区表:如果cpu够的话,建议配置成分区数。
-- 打开并行度
define PARALLEL_NUM = 35; --这里配置成分区数
ALTER SESSION ENABLE PARALLEL DML ;
alter session force parallel dml parallel &PARALLEL_NUM;
alter session force parallel query parallel &PARALLEL_NUM;
- 表上没主键问题
在线重定义支持主键、rowid、唯一约束,建议在实施过程中使用rowid进行定义。
begin
DBMS_REDEFINITION.START_REDEF_TABLE(uname => '&USERNAME',
orig_table => '&SOURCE_TAB',
int_table => '&INT_TAB',
col_mapping => 'ID ID,to_number(RANDOM_ID) RANDOM_ID', 前是原表字段,后是临时表字段,中间空格。
options_flag => DBMS_REDEFINITION.CONS_USE_ROWID); --使用rowid定义
end;
/
- 字段映射问题 - [只转换原表字段]
在涉及到类型转换时,比如varchar2转number,在映射时需要使用to_number(原表字段),将原表字段转换成目标表的number类型,如果只是改长度不需要转换。
--利用正则筛选出非全数字的行记录,大表处理起来效率较低
select PROP_INST_ID from OM_PRODUCT_INST_ATTR where regexp_replace(PROP_INST_ID,'\d','') is not null;
- 复制依赖问题
如果表小,依赖可以全部复制,省事。在客户场景验证10-20亿的表时发现,如果复制索引、约束、统计信息效率非常差,10亿的表跑4-5个小时都没结果,建议最后开并行重建索引、约束和统计信息,测试下来24亿的表,35个分区,建普通索引开35个并行,只需5分钟左右,效率还行。
DECLARE
num_errors PLS_INTEGER;
BEGIN
DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS(uname => '&USERNAME',
orig_table => '&SOURCE_TAB',
int_table => '&INT_TAB',
copy_indexes => 0,-- 等于0不复制索引,最后开并行创建
copy_triggers => FALSE, --这个基本没有用
copy_constraints => FALSE, --最后手工创建
copy_privileges => TRUE,
ignore_errors => FALSE,
num_errors => num_errors,
copy_statistics => FALSE); --统计信息最后开并行手工收集
END;
/
- 空间、日志问题
检查表空间空量,空闲的空间需要大于原表占用的空间。
会产生大量的redo和undo,容易塞满归档空间,需要提前进行扩容或清理,单个redo日志建议配置1-2G。
- 收尾注意事项
- 如果定义使用rowid方式,重定义完的表上会多出一个隐藏字段M_ROW$$,从10.2开始M_ROW$$的隐藏列会被命名为SYS_%DATE%的形式,且默认即为unused状态,如果表小可以删除,在脚本中有提供方法。测试24亿的表完全删除不动,业务使用不受影响,暂时未处理。
--查出有隐藏unused字段的表名
select * from dba_unused_col_tabs ;
--大表慎用
alter table &SOURCE_TAB drop unused columns;
- 表变更完成验证后,记得删除临时表。
- 清除表和索引上的并行度。
--清除索引并行度
alter index idx_xxxx noparallel;
--清除表的并行度
alter table tbl_xxxx noparallel;
三、总结
-
在线重定义整体流程:1.创建临时表==> 2.检查是否满足要求==> 3.启动重定义进程==> 4.复制依赖==> 5.开启异步同步==>6.切换完成重定义==>7.重建索引、约束==>8.收集统计信息==>9.清理临时表及并行度等。
-
针对大表的在线重定义,建议提前做好备份,防患于未然,希望大家能少踩坑。
