




1导读
本文花了比较多的时间梳理了InnoDB page的结构以及对应的分裂测试,其中测试部分大部分是参考了叶老师在《InnoDB表聚集索引层什么时候发生变化》一文中使用的方法,其次,本文中的测试工具用到了如下两个工具:
innblock:https://github.com/gaopengcarl/innblock
innodbruby:https://github.com/jeremycole/innodbruby
本文篇幅较长,强烈建议使用电脑阅读本文。
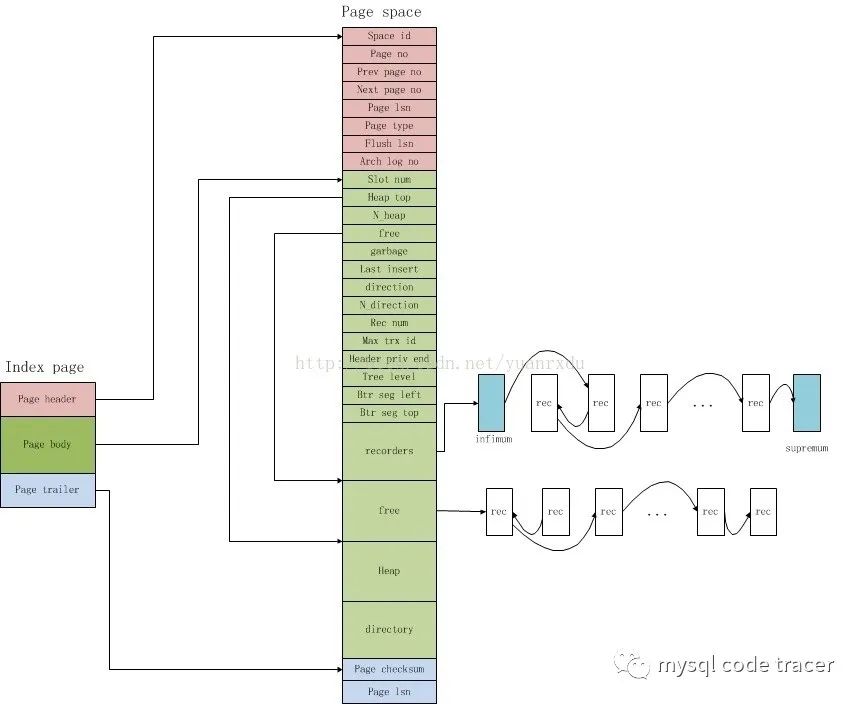
一、page结构
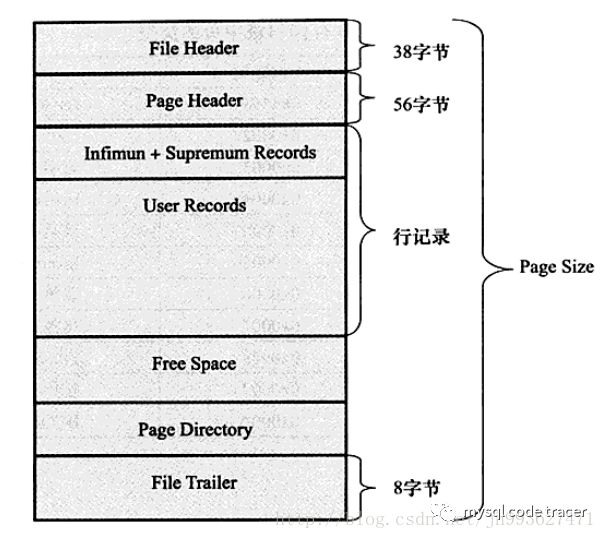
InnoDB Page结构图
1、File Header结构,记录了page页的一些头信息,一共38字节
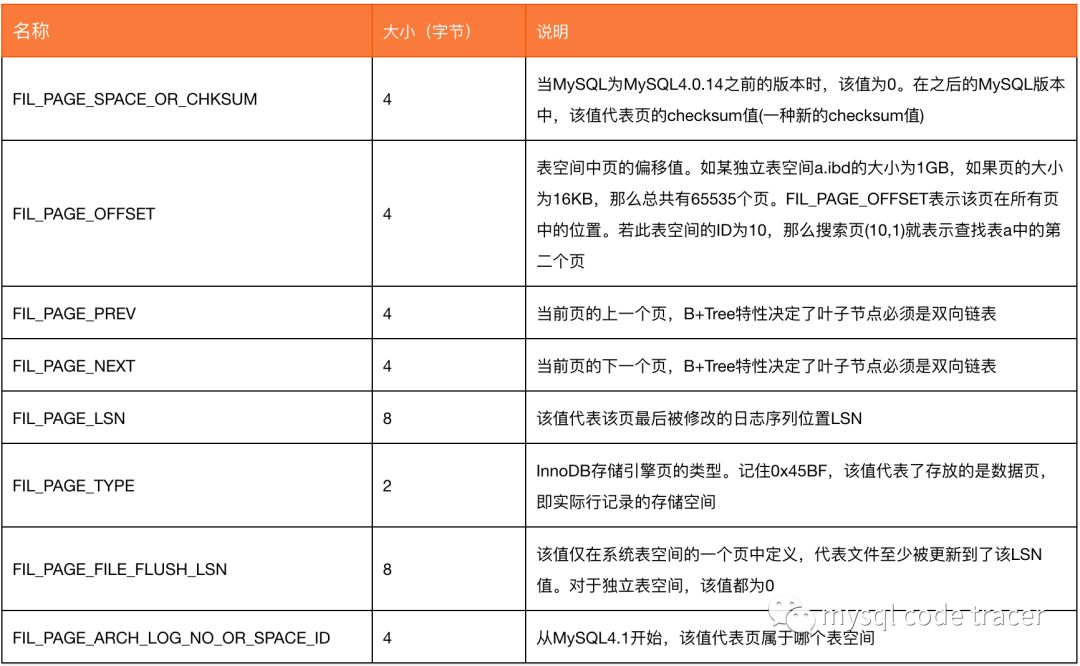
innodb存储页类型
2、page header,记录页的状态信息,共56字节
3、虚拟最大最小记录(Infimum and Supremum Records)
最大记录是这个数据页中逻辑上最大的记录,所有用户的记录都小于它。最小记录是数据页上最小的记录,所有用户记录都大于它。他们在数据页被创建的时候创建,而且不能被删除。引入他们主要是方便页内操作。
4、用户记录
用户所有插入的记录都存放在这里,默认情况下记录跟记录之间没有间隙,但是如果重用了已删除记录的空间,就会导致空间碎片。每个记录都有指向下一个记录的指针,但是没有指向上一个记录的指针。记录按照主键顺序排序。即,用户可以从数据页最小记录开始遍历,直到最大的记录,这包括了所有正常的记录和所有被delete-marked记录,但是不会访问到被删除的记录(PAGE_FREE)。
5、Free Space
从PAGEHEAPTOP开始,到最后一个数据目录,这之间的空间就是空闲空间,都被重置为0,当用户需要插入记录时候,首先在被删除的记录的空间中查找,如果没有找到合适的空间,就从这里分配。空间分配给记录后,需要递增PAGENRECS和PAGENHEAP。
6、Page Directory
用户的记录是从低地址向高地址扩展,而数据目录则相反。在数据页被初始化的时候,就会在数据页最后(当然在checksum之前)创建两个数据目录,分别指向最大和最小记录。之后插入新的数据的时候,需要维护这个目录,例如必要的时候增加目录的个数。每个数据目录占用两个字节,存储对应记录的页内偏移量。假设目录N,这个目录N管理目录N-1(不包括)和目录N之间的记录,我们称目录N own 这些记录。在目录N指向的记录中,会有字段记录own记录的数量。由此可见,目录own的记录不能太多,因为太多的话,即意味着目录太过稀疏,不能很好的提高查询效率,但同时也不能own太少,这会导致目录数量变多,占用过多的空间。在InnoDB的实现中,目录own的记录数量在4-8之间,包括4和8,平均是6个记录。如果超过这个数量,就需要重新均衡目录的数量。目录的增加和删除可能需要进行内存拷贝,但是由于目录占用的总体空间很小,开销可以忽略不计。
7、File Trailer
这个部分处于数据页最后的位置,只有8个字节。低地址的四个字节存储checksum的值,高地址的四个字节存储FILPAGELSN的低位四字节。注意这里的checksum的值不一定与FILPAGESPACEORCHKSUM的相同,这个依赖不同的checksum计算方法。
找到一张比较不错的page结构图
二、行记录格式
Record Header
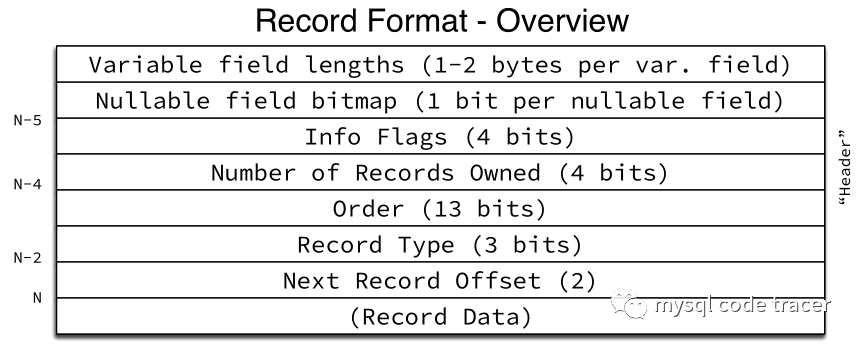
从这个图中可以看到,一条记录的Record Header至少为5字节,对Record Header长度取决于边长字段及字段是否可为空
简言之,记住几条关键规则
一条记录的record header,至少是5字节
对record header影响最大的是变长列数量,及其是否允许为NULL的属性
关于变长列
每个变长列,如果列长度 <128 字节,则需要额外1字节
每个变长列,如果列长度 >=128 字节,则需要额外2字节
如果没有任何变长列,则无需这额外的1-2字节
变长类型为char/varchar/text/blob等
同学们可能会诧异,char为什么也当做变长类型了?这是因为,当字符集非latin1时,最大存储长度可能会超过255字节,例如 char(65) utf8mb4 最长就可以存储260字节,此时在record header中需要用2字节来表示其长度,因此也被当做变长类型了
关于列允许为NULL
每个列如果允许为NULL,则增加 1bit,不足8bit也需要额外1字节
例如只有2个列允许为NULL,只需要2bit来表示,但也需要占用1字节
P.S,在InnoDB的存储结构里,从tablespace到segment,再到extent、page,还是file层面,总有各种必要的header或trailer信息需要消耗额外的字节数,不像MyISAM那么简单。
三、数据page结构
主键非叶子节点

Record Header,根据主键类型不同占用字节数不同,例如一个int主键,Record Header为5字节,另外需要考虑变长类型、是否为空
聚集索引key的长度,比如int为4字节
指向子节点指针,固定4字节
主键叶子节点

Record Header,根据主键类型不同占用字节数不同,例如一个int主键,Record Header为5字节,另外需要考虑变长类型、是否为空
聚集索引key的长度,比如int为4字节
事务ID,固定6字节
回滚段指针,固定7字节
其他列占用空间
二级索引非叶子节点

Record Header,根据主键类型不同占用字节数不同,例如一个int主键,Record Header为5字节,另外需要考虑变长类型、是否为空
二级索引列长度
主键索引列长度
指向子节点指针,固定4字节
二级索引叶子节点

Record Header,根据主键类型不同占用字节数不同,例如一个int主键,Record Header为5字节,另外需要考虑变长类型、是否为空
二级索引key大小
主键索引列长度
四、一个只有1个page的B+树page
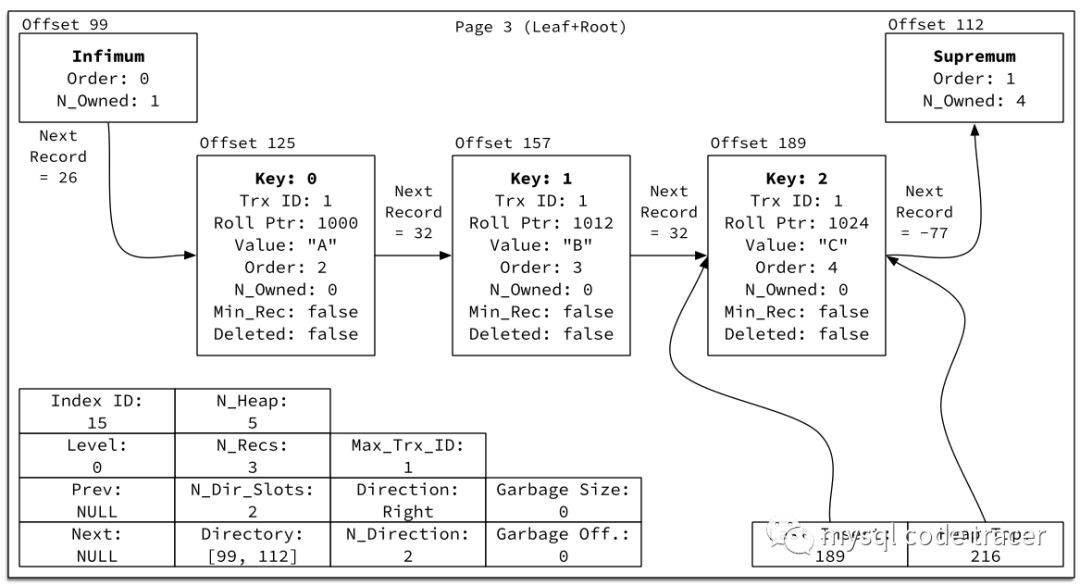
Index ID:索引ID,可在informationschema下的INNODBSYS_INDEXES表查到
Level:索引高度
Prev:上一个page指针
Next:下一个page指针
N_Heap:表内所有记录数(包含虚拟最大最小记录)
N_Recs:表内用户记录数
NDirSlots:slots数量
Directory:分别记录每个slot的最后一条数据的便宜量,是一个列表
MaxTrxD:page内所有记录的最大事务ID
Direction:上一条记录的插入方向
N_Direction:同一个方向连续插入记录数
Garbage Size:可回收空间
Garbage off:可回收空间的最近一条记录的偏移量
五、InnoDB表高度计算
相信这是一个面试经常会被问到的问题,那么以三层高度的B树来说,这也是日常生活中最常碰到树的高度了。对于一棵三层高度的B树计算最多存储记录数非常好计算,无非就是根节点最大存储记录数N1中间节点最大存储记录数N2叶子节点最大存储记录数N3得到N,这个N就是当前数据存储结构下的三层高度B树的最大存储记录数。
那么问题来了,对于这个N1、N2、N3分别应该怎么来计算呢?
N1
根节点单行长度计算公式 page大小(16*1024=16384)- 必要信息(File Header38字节+page header56字节+虚拟最大最小记录26字节+Page Directory4字节+File Trailer8字节)=16252字节
每行需要一个指向下一层page的节点的指针,占用4字节
约每4条记录占用一个slot,一个slot大小占用2字节
单行长度计算公式为:row header5字节 + 主键索引列4字节 + 指针4字节 = 13字节
那么单个page最多能容纳最多行数为 单行长度N1+N1/4*2 = 16252,N1为1203
N2
中间节点的计算方式等同于根节点
N3
不同于非叶子节点,叶子节点需要保留1/16的空间用做变长更新的保留空间,因此,叶子节点的真实可用空间约为15228字节
row header(5字节+可变长+非空占位符)+ 主键key长度(如果没有显示声明默认会创建6字节row id)+ trxid6字节+ rollptr7字节
以一个只有一个int列的主键表来说,这个单行长度就为5+4+6+7=22字节
约每4条记录占用一个slot,一个slot大小占用2字节
单行长度N3+N3/4*2 =15228,N3为676
六、测试及分析过程
15872 │ │15936 │ │16000 │ █▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋│16064 │█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋│16128 │█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋│16192 │█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋│16256 │█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋│16320 │█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋█▋███████▋│╰────────────────────────────────────────────────────────────────╯Legend (█ = 1 byte):Region Type Bytes Ratio█ FIL Header 38 0.23%█ Index Header 36 0.22%█ File Segment Header 20 0.12%█ Infimum 13 0.08%█ Supremum 13 0.08%█ Record Header 3380 20.63%█ Record Data 11492 70.14%█ Page Directory 340 2.08%█ FIL Trailer 8 0.05%░ Garbage 0 0.00%Free 1044 6.37%
分析如下:
固定开销(38字节+36字节+20字节+13字节+13字节+8字节)
记录头部3380字节(676*5)
记录大小11492字节(676*17)
共170个slot(2*170占340字节)
free space大小为1044字节(保留1024字节+20空闲)
此时B树高度为1
[root@izbp13wpxafsmeraypddyvz data]# innodb_space -s ibdata1 -T xucl/t1 -p 3 space-indexesid name root fseg fseg_id used allocated fill_factor2063 PRIMARY 3 internal 1 1 1 100.00%2063 PRIMARY 3 leaf 2 0 0 0.00%
再次插入一条数据,这个时候树的结构就发生变化了
[root@izbp13wpxafsmeraypddyvz data]# innodb_space -s ibdata1 -T xucl/t1 -p 3 space-indexesid name root fseg fseg_id used allocated fill_factor2063 PRIMARY 3 internal 1 1 1 100.00%2063 PRIMARY 3 leaf 2 2 2 100.00%
可以看到,这个时候树的高度就变成了二层,page no=3为根节点,page no=4和page no=5是它的叶子节点
[root@izbp13wpxafsmeraypddyvz data]# innodb_space -s ibdata1 -T xucl/t1 space-summarypage type prev next lsn0 FSP_HDR 0 0 704846310531 IBUF_BITMAP 0 0 704845715362 INODE 0 0 704846310533 INDEX 0 0 704846310534 INDEX 0 5 704846310535 INDEX 4 0 70484631053
我们仍然扫描page no=3这个page
16256 │ │16320 │ █▋█▋█████▋│╰────────────────────────────────────────────────────────────────╯Legend (█ = 1 byte):Region Type Bytes Ratio█ FIL Header 38 0.23%█ Index Header 36 0.22%█ File Segment Header 20 0.12%█ Infimum 13 0.08%█ Supremum 13 0.08%█ Record Header 10 0.06%█ Record Data 16 0.10%█ Page Directory 4 0.02%█ FIL Trailer 8 0.05%░ Garbage 0 0.00%Free 16226 99.04%
可以看到这个page含有2条记录,每条记录record header5字节,数据部分8字节(id列4字节+4字节指针)
扫描page no=4这个page
Legend (█ = 1 byte):Region Type Bytes Ratio█ FIL Header 38 0.23%█ Index Header 36 0.22%█ File Segment Header 20 0.12%█ Infimum 13 0.08%█ Supremum 13 0.08%█ Record Header 1690 10.31%█ Record Data 5746 35.07%█ Page Directory 172 1.05%█ FIL Trailer 8 0.05%░ Garbage 7436 45.39%Free 1212 7.40%
从统计信息可以分析出,这个page共338条数据,Garbage size为7436(注意一下,这个后面会有用到)
Legend (█ = 1 byte):Region Type Bytes Ratio█ FIL Header 38 0.23%█ Index Header 36 0.22%█ File Segment Header 20 0.12%█ Infimum 13 0.08%█ Supremum 13 0.08%█ Record Header 1695 10.35%█ Record Data 5763 35.17%█ Page Directory 170 1.04%█ FIL Trailer 8 0.05%░ Garbage 0 0.00%Free 8628 52.66%
从统计信息可以分析出,这个page共339条数据,两个page加起来共677条数据,也符合我们的结果。
到这里,二层分裂我们已经测试完了,我们继续往下测试三层高度,按照我们先前的理论基础,2层高度最多可以容纳约813228条数据(实际上并不是这个值,至于原因我后面再讲),我们利用以下脚本构造t1(我把t1表truncate了),我插入了812890条数据
#!/bin/env python#coding:utf-8import pymysqldef insert_mysql():conn = pymysql.connect(host='127.0.0.1', user='xucl',password='xuclxucl123', database='xucl', charset='utf8')cursor = conn.cursor()for i in range(812890):sql = "insert into t1 values({});".format(i)cursor.execute(sql)conn.commit()conn.close()if __name__ == "__main__":insert_mysql()
此时树高度为2层
[root@izbp13wpxafsmeraypddyvz data]# innblock xucl/t1.ibd scan 16----------------------------------------------------------------------------------------------------Welcome to use this block analyze tool:[Author]:gaopeng [Blog]:blog.itpub.net/7728585/abstract/1/ [QQ]:22389860[Review]:yejinrong@zhishutang [Blog]:imysql.com [QQ]:4700963----------------------------------------------------------------------------------------------------Datafile Total Size:28311552===INDEX_ID:2063level1 total block is (1)block_no: 3,level: 1|*|level0 total block is (1203)
根节点存储了1203条数据
我用如下方法扫描并统计了每个叶子page内的数据量
[root@izbp13wpxafsmeraypddyvz data]# cat test.sh#!/bin/bashfor i in {3..1235};doinnblock xucl/t1.ibd ${i} 16|grep n_rowsdone
扫描结果如下:
[root@izbp13wpxafsmeraypddyvz data]# sh test.shslot_nums:301 heaps_rows:1205 n_rows:1203slot_nums:86 heaps_rows:678 n_rows:338slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676slot_nums:170 heaps_rows:678 n_rows:676...
我们注意到page no=4这个page,只存储了338条记录,我们用innodb_space扫描这个page
Legend (█ = 1 byte):Region Type Bytes Ratio█ FIL Header 38 0.23%█ Index Header 36 0.22%█ File Segment Header 20 0.12%█ Infimum 13 0.08%█ Supremum 13 0.08%█ Record Header 1690 10.31%█ Record Data 5746 35.07%█ Page Directory 172 1.05%█ FIL Trailer 8 0.05%░ Garbage 7436 45.39%Free 1212 7.40%
很清楚地可以看到,Garbage size为7436,恰好为338条记录大小,至于原因我个人的猜测是因为在一层变二层高度时,由原先page内数据逐条删除,插入新的page,删除的空间变成了Garbage,新page由于是新插入的,所以不存在Garbage(以上未经求证),这里比较细节。
这样一算,插入812890条数据以后,所有的page都已经占满,这也就解释了最大记录数不是理论值813228了。接着我们再插入一条数据
root@mysqldb 20:12: [xucl]> select count(*) from t1;+---------+| max(id) |+---------+| 812890 |+---------+1 row in set (0.00 sec)root@mysqldb 20:21: [xucl]> insert into t1 values(812890);Query OK, 1 row affected (0.01 sec)
B树变成了三层高度
[Review]:yejinrong@zhishutang [Blog]:imysql.com [QQ]:4700963----------------------------------------------------------------------------------------------------Datafile Total Size:28311552===INDEX_ID:2063level2 total block is (1)block_no: 3,level: 2|*|level1 total block is (2)block_no: 36,level: 1|*|block_no: 37,level: 1|*|level0 total block is (1204)
七、遗留问题
关于heaptop,一直没有搞懂计算方法,根据我的多次观察,heaptop的便宜量总是最后一条记录的位置点-5,咱不清楚为什么
关于page no=4 garbage的问题没有深入研究
八、结论
本文对InnoDB Page有了较为详细的剖析,建议读者好好研究一下
对于InnoDB B+数的高度计算并不能光从理论计算,还需要考虑分裂导致的Garbage
对于InnoDB Page的研究强烈建议使用文中我提到的两个神器,且建议结合使用
生产环境会比我们的实验环境复杂地多,需要各位读者结合生产环境自行研究了
参考资料:《InnoDB表聚集索引层什么时候发生变化》: https://zhishutang.com/vca 《MySQL系列:innodb源码分析之page结构解析》 :https://www.2cto.com/database/201412/365376.html 《MySQL是怎样运行的--笔记二》: https://cs704.cn/?p=352
QQ群号:763628645
QQ群二维码如下, 添加请注明:姓名+地区+职位,否则不予通过

订阅我的微信公众号“杨建荣的学习笔记”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

7
近期热文
你可能也会对以下话题感兴趣。点击链接就可以查看。
8
转载热文
你可能也会对以下话题感兴趣,文章来源于转载,点击链接就可以查看。
