写在前面
今天分享一篇论文学习笔记。
论文:
《FLOD:Oblivious Defender for Private Byzantine-Robust Federated Learning with Dishonest-Majority》
作者:董业
链接:Cryptology ePrint Archive: Report 2021/993
https://eprint.iacr.org/2021/993.pdf
在联邦学习在即解决拜占庭问题同时也要保护隐私数据是一个矛盾的问题。一方面,隐私数据保护要求禁止访问单个模型数据,或者说不能够区分各个模型之间的数据;而解决拜占庭问题则需要对全体模型数据进行数学分析从而将异常数据从正常数据中区分出来。此外现有的这方面技术也是基于诚实大多数场景假设的。本文提出了FlOD方法,基于汉明距离的方法实现对异常数据的处理,同时使用基于布尔秘密分享的方法实现安全的的两方聚合方案,从而实现了在恶意大多数场景下对上述矛盾问题的解决。经实验验证本方案在能够抵抗现有的拜占庭攻击同时损失很小的精度,此外相比较于ABY-AHE方案在离线阶段有两倍的性能提升,相比较于FLGuard有167倍以上的通信开销和3.1倍以上的运行时间开销。
预备知识
基本知识
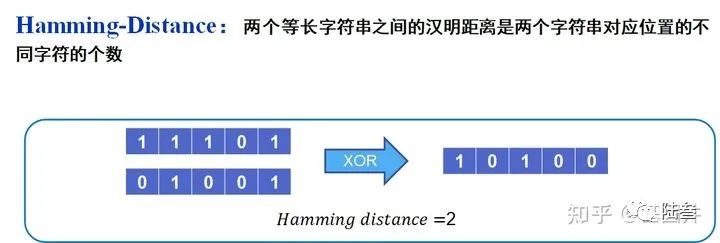
预备知识包括联邦学习、推理攻击、拜占庭攻击和汉明距离,联邦学习、推理攻击和拜占庭攻击相信大家已经很熟悉了,所以在这里给大家简单介绍汉明距离,如下图所示:
此外还需要了解一下SignSGD:
 最后还要了解一下前人的工作FLTrust:
最后还要了解一下前人的工作FLTrust: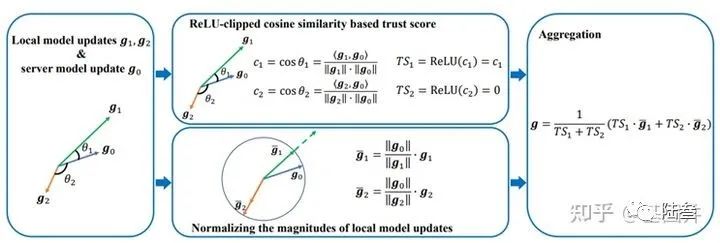
密码学知识:
包括2PC的安全计算和同态加密的基本知识。
FLOD方案
FLOD和FLTrust类似,依旧再服务器端保存一部分的训练数据Root Dataset,这个训练集可以很小,但是必须是干净的,目的就是提供一个绝对安全的参考值用来判定其他梯度向量是否异常。而且FLOD方案是可以抵御恶意大多数的拜占庭攻击的。接下来就来看看基础方案的整体设计:
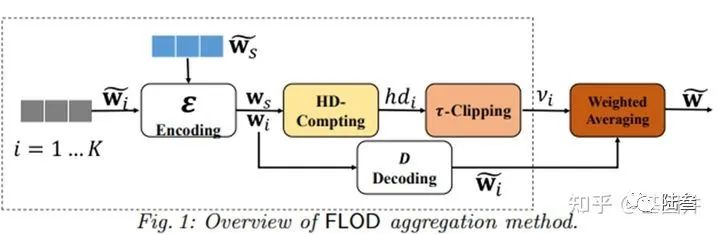
Encoding:
这里是将客户端的上传的梯度更新
e.g. 原始的梯度值为:
需要特别说明的是这里是将
HD-Computing:
对上述Encoding的结果分别与服务器端梯度更新的结果运算来计算两者的汉明距离,具体如下:
得到的结果就是汉明距离,后面会以汉明距离为基础来判定数据是否异常,那么为什么汉明距离能够其作用呢?文中也给出了证明如下:对于已经使用SignSGD的梯度向量
证明表明,余弦距离和本文使用得汉明距离是具有线性关系得,因此可以使用汉明距离直接替换汉明距离。
这一步就类似于 FLTrust 中的 Relu() 函数那一步骤,也就是根据超参
也就是如果汉明距离大于等于
Weight Average:
这一步就很简单了,就是将客户端的数据乘上
随后用结果更行自己的模型参数,并将结果发送给每个客户端即可。
至此,我们已经了解了整体的FLOD模型框架,但是已依然还没有添加密码学工具来保护数据隐私,下面就来介绍如何将密码学工具应用到FLOD框架中。本文的方法呢就是将FLOD部署再两方的服务器
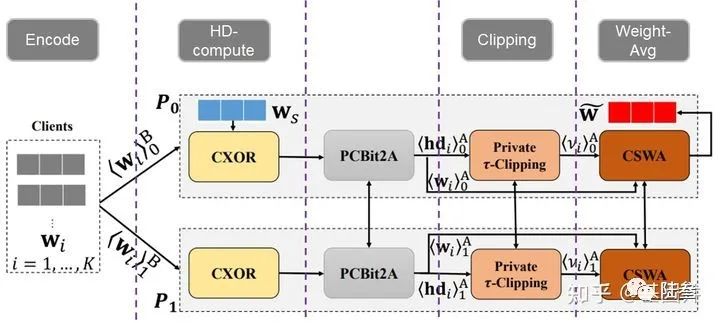
依然先是Encode编码为
Correlated XOR (CXOR):
这一步的就是在不泄露用户梯度数据的情况下计算原始梯度更新与服务器参考的梯度更新之的汉明距离,并将结果依旧用Boolean sharing的方式保存再两方服务器上,具体方法如下:
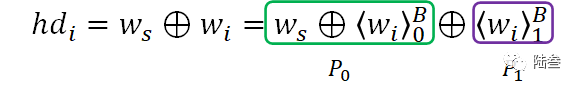
Partial Correlated Bit to Arithmetic Conversion (PCBit2A) :
因为后面
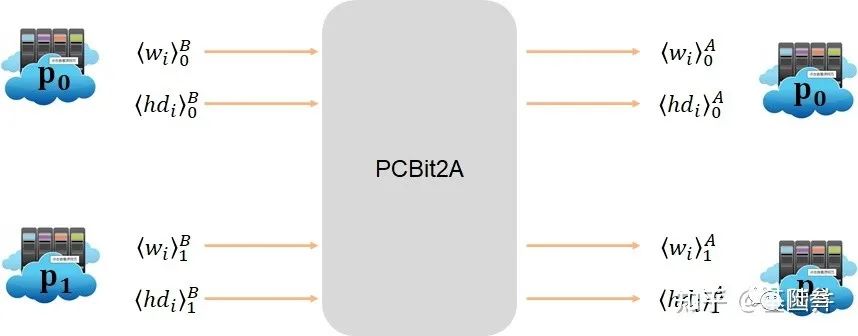
在实现方面,使用了部分元组的方法来进行的,如下图:
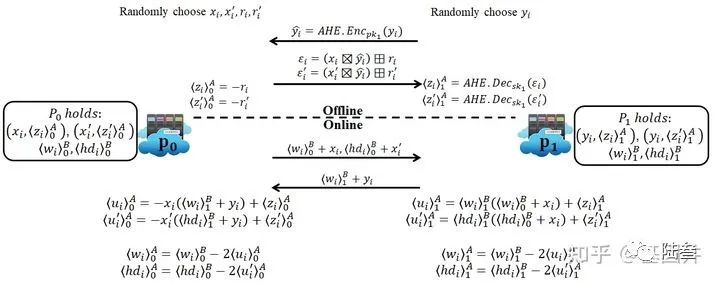
图中
Private
此步骤和最开始一样,进行裁剪,对于汉明距离超过
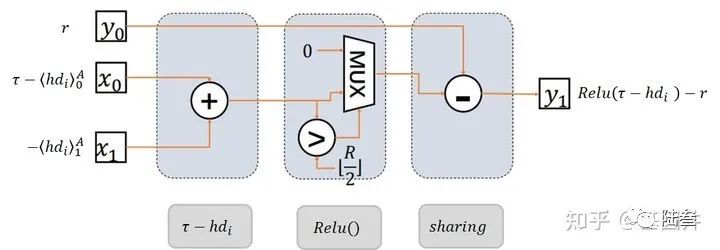
此过程运行过后,
Correlated Secure Weighted Aggregation(CSWA):
该模块功能很简单,就是根据前面得到的梯度更新参数向量以及private
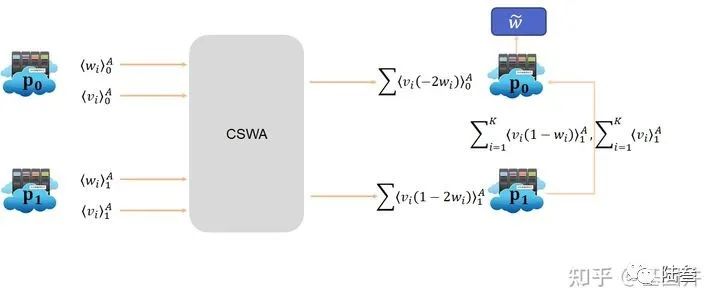
需要特别说明的是,最终的聚合结果将由
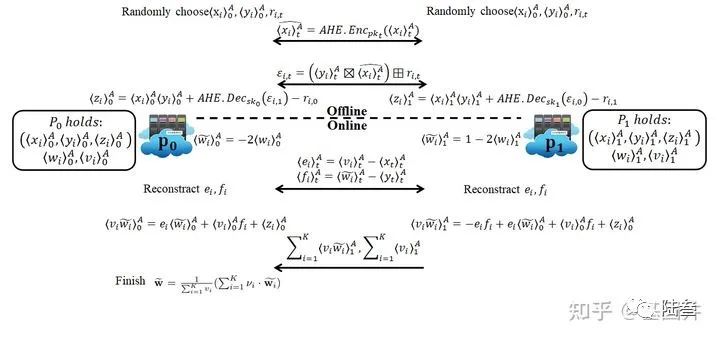
离线阶段是生成
Evaluations
首先是在MNIST和CIFAR10数据集上对无恶意用户场景下与FedAvg、SIGNSGD的比较,可以看出本文的方法在该情境下的精确度表现非常好,和FedAvg相比仅有很小的差距。
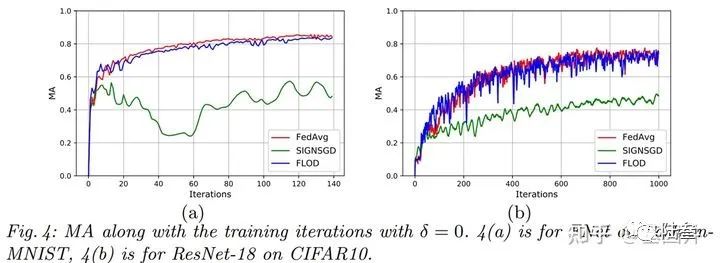
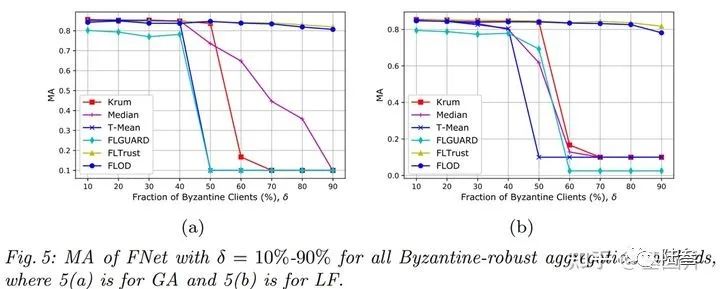
接下来是在不用恶意用户比率下与现有的一些方法作比较,其中(a)图是在高斯攻击下的实验,(b)图是在标签反转攻击下的实验。可以看出,本文的方案是非常有效的,并且很明显的看出本文的方法是可以解决恶意大多数下的拜占庭将军问题。
接下来就就需要考虑方案的计算复杂性和通信复杂性,因为隐私保护的很多方案不能够被使用的原因就在于高昂的通信和计算消耗,所以衡量方案的通信和计算消耗很有必要:
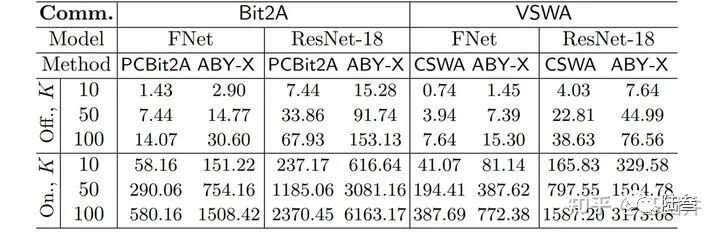
首先是PCBit2A 与 ABY-AHE中的B2A 和 CSWA 与 ABY-AHE中的乘法在通信复杂度上作比较,可以看出无论是在线还是离线状态,都有2倍或以上的提升。而且计算消耗具有同样的情况,具体可以看原文实验。
Summary
拜占庭鲁棒性:
提出一个基于汉明距离的联邦学习算法,该方案可以在恶意大多数场景下解决拜占庭鲁棒性问题。
隐私保护:
在半诚实假设下,在设计了在两方上使用 FLOD 方案来完成聚合过程,从而保护用户数据隐私。
实验性能:
1、在很小的精度损失和收敛速率损失下能够抵抗所有现有的拜占庭攻击.
2、相比于ABY-AHE方法,该方法在 B2A 转化上离线阶段性能提升2倍以上。
3、相比于FLGUARD算法,总体的在线运行时间和通信时间分别提升3.1倍和167倍以上。
参考文献
[1] Bernstein J, Wang Y X, Azizzadenesheli K, et al. signSGD: Compressed optimisation for non-convex problems[C]//International Conference on Machine Learning. PMLR, 2018: 560-569.
[2] Cao X, Fang M, Liu J, et al. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping[J]. arXiv preprint arXiv:2012.13995, 2020.
[3] Nguyen T D, Rieger P, Yalame H, et al. FLGUARD: Secure and Private Federated Learning[J]. arXiv preprint arXiv:2101.02281, 2021.
[4] Demmler D, Schneider T, Zohner M. ABY-A framework for efficient mixed-protocol secure two-party computation[C]//NDSS. 2015.
[5] agdasaryan, E., Veit, A., Hua, Y., Estrin, D., Shmatikov, V.: How to backdoor federated learning. In: International Conference on Artificial Intelligence and Statistics. pp. 2938–2948. PMLR (2020)
[6] Bookstein, A., Kulyukin, V.A., Raita, T.: Generalized hamming distance. Information Retrieval 5(4), 353–375 (2002)
作者简介:
井渭展,本科毕业于南京航空航天大学信息安全专业,目前在中国科学院信息工程研究所攻读硕士学位。研究兴趣包括隐私保护、安全多方计算、同态加密和机器学习。知乎:基因井
往期内容:
论文笔记:IJCAI 2021 Decentralized Federated Graph Neural Networks

欢迎投稿
邮箱:kedakeyin@163.com
参与更多讨论,请添加小编微信加入交流群