





Google File System(GFS)是google在2003年发表在顶会SOSP上的文章,虽然距今已经15年过去了,开源界的对标物HDFS也已经更新换代,增加了数不清的优化和特性,但是其中的基本原理仍旧适用,本文尝试梳理其中核心的几点,并给出自己的看法。
总体架构及数据流、控制流
GFS的主要组件构成,以及读写数据流,看下图应该就基本清楚:
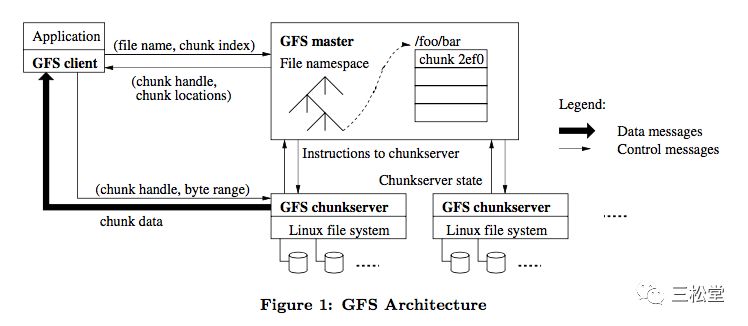
我们简述如下:
GFS将整个系统分为master、chunkserver、client三部分。master负责存储namespace、file->chunks等metadata的操作和存储。chunkserver负责数据存储。client被集成到application中。
读取流:
1)client本地计算根据offset计算出chunk index,以file name+chunk index联系master,获取三个chunk副本的handle、localtion信息;
2)client联系任意一个chunk,读取对应的数据;
写入流:
1)client联系master,获取到chunk的handle、localtion信息、主备身份信息;
2)client将data发给任意一个chunk,该chunk将data转发给其他chunk;
3)当三个chunk都成功将data写入内存,client给primary发送commit请求;
4)primary将数据落到本地log中,然后发送commit请求给其他replica。
5)当primary收到其他replica写入成功的回复后,返回client success。
任何一个副本写入失败,都会导致client进行重试;重试一定次数后仍旧失败,client则返回ERROR给用户。
写入接口及一致性模型
我们要解释的第一个点是这个图表,也是整个论文中相对费解的一部分。
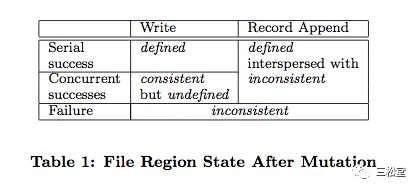
首先我们介绍部分背景。GFS将写操作分为两种:
1)write。允许用户指定offset,进行随机写。
2)record append。不允许用户指定offset,只能不断往后append写。但是要注意的是这里的append与我们通常所说的在linux fs上append一个文件不同。平常所说在linux fs上append,就是指seek到文件末尾,然后将data写在末尾的下一个byte。而gfs的append,并不保证data会写到文件末尾的下一个byte中,而是由GFS内部选定一个位置写进去,然后把这个位置的offset作为返回值返回给用户。唯一能保证的是:这个GFS内部选定的位置offset,的确在末尾以后,但是可能并不直接与末尾相邻,中间可能夹杂着failed的、duplicated的数据碎片。具体原因我们在后面解释。
GFS将文件状态分为两种:
1)consistent。也就是一个chunk的多个replica,彼此之间数据一致。
2)defined。不仅多个replica彼此之间数据一致(也即consistent),而且replica中的data与某一个用户写入的data保持一致。这句话比较难理解:replica中的数据怎么会跟用户写入的数据不一致呢?
我们一个一个场景来看:
1)单并发write,成功了。由于成功了,所以多个replica之间的数据肯定彼此一致,也即consistent(因为只有三个replica都成功了,才会返回success);又由于只有一个并发,用户写的是啥自然存放的也是啥(也即defined)。
2)多并发write,成功了。由于成功了,所以多个replica之间的数据肯定彼此一致(consistent);但是由于有多个并发,设想一个场景:user1写了70MB dataA、user2写了80MB dataB,两个用户并发写,chunkSize是64MB。由于GFS的设计,在client端70MB dataA会被切分为64MB+6MB,80MB dataB也会被拆分为64MB+16MB。此时server收到的数据包顺序可能是:64MB dataB, 64MB dataA,16MB dataB, 6MB dataA。写入成功返回之后,user3过来读,它读到的既不是完整的70MB dataA,也不是完整的80MB dataB,而是来自多个用户的dataA、dataB的碎片混淆在一起。这个混淆的数据,既不是user1写入的原始数据,也不是user2写入的原始数据。这种情况下,多个replica之间的数据是相同的,但不是任何一个用户想要写入的数据,这种状态被成为undefined。
3)write失败了,包括单并发还是多并发。显然失败了,多个副本之间可能一部分写成功了,另一部分写失败了,自然也就in-consistent、undefined了。
4)单并发append,成功了。同情况1)类似。
5)多并发append,成功了。GFS这里做了几个限制:1)单次append不能超过64MB,这就避免了client端的拆分;2)如果当前正在写的chunk剩余空间,不足以放下要append的数据,就先用0把当前chunk填补满,然后新开一个chunk来append要写的数据。两个限制的效果就是:每次append都不会被拆分,而且原子性的、完整的落在一个chunk中。哪怕是并发情况下,因为不会做数据拆分,自然也就不可能会有2)中dataA、dataB碎片被混淆在一起的问题了,进而多个replica中的数据也就跟用户写入的数据一致,所以是defined。
6)append失败了,包括单并发及多并发。跟3)类似,部分replica成功了,部分replica失败了,副本间数据不一样,所以in-consistent,也就undefined。
也正是基于以上特性,虽然GFS支持随机写write接口,但是需要在应用层做并发控制,对于分布式应用非常不友好。因此论文中只推荐使用record append接口,而且google内部也的确大量的application都基于record append接口。
下面的讨论,我们忽略write接口,全部基于record append来探讨。
分布式副本一致性
第二个点是分布式副本一致性。
了解GFS的多副本设计,自然要提出一个经典的问题:到底如何保证多个副本之间数据是一致的呢,尤其是写了一半的时候失败了?
在回答这个问题之前,我们要解释几点:
1)这里的consistency与数据库事务中的ACID中的C不一样。此处的consistency是指分布式副本一致性,也即多个副本之间数据要“一样”。ACID的C,强调的是数据库中的约束,比如外键约束,唯一性约束等等,在事务执行前后不能被break。
2)细心的读者已经注意到了上面的“一样”我特意打了双引号。虽然我们说分布式多副本要“一致”、“一样”,但是这个“一致”、“一样”并不是bytewise一致,而是从用户的角度看一致。也即我们并不要求replicaA与replicaB的每个byte都完全一一对应,丝毫不差【注意理解这一点非常重要】,只要从用户的角度replicaA和replicaB中读出来的数据是一样的就可以了。问题是:如果replicaA与replicaB不一样,怎么能读出来一样的东西呢?举个例子:假设replicaA的内容是:123ABC, replicaB的内容是:123ABCDEF。从bytewise上看,两个副本显然并不相同,但是如果我们有个手段保证replicaB的DEF被用户读不到(比如存储一个length=6,只有前6个字符被用户读到),那么从用户的角度看无论从replicaA还是从replicaB读,都是:123ABC。所以底层byte是不是相同不重要,关键是从用户看来两个副本“一样”。
这里要明确引申一点:我们将分布式概念划分为system、user。通常所述的分布式一致性,指的是整个system对外部user保持一致,但是system内部并不一定要求多个replica完全相同。不同system可能有不同的一致性实现方法。
3)replication consistency与distributed transaction protocol 2PC 也有很大差别。副本一致性强调整个系统保持对外行为一致。2PC等分布式协议强调事务的ACID特性:全做或全不做(原子性)、互不影响(隔离性)。副本一致性是比分布式事务弱得多的语义。通过分布式事务可以实现副本一致性,但是分布式事务并不是实现副本一致性的必要手段。
有了上面的说明,我们可以愉快的解释GFS副本一致性了。
我们先约定场景,对于一个chunk chunkX,有三个副本replicaA, replicaB, replicaC,有两个外部用户Client client0, client1。client0 要往chunkX apped数据data0: “123”, client1要往chunkX append数据data1: “abc”。
在写入时,要解决几个问题:
1)有三个replica,往哪个replica写?
2)写到了一个replica之后,如何同步给其他2个?
3)是全部replica都写成功了才能ack success,还是只要有部分成功了就可以ack success?
4)如果写了一半,因为网络故障、机器故障失败了,怎么办?
5)失败之后,选谁成为新primary replica?新的primary诞生后,如何处理以保证副本一致?
6)节点恢复后,是否追数据,如何追数据?
7)如何处理stale replica?
问题1)往哪个replica写?
这个问题有几种解法。PAXOS支持随便写哪个都行,但是同步起来非常麻烦,协议复杂(后面我们可以单独开文章介绍);而且并发写时,不同replica可能被写了不同的数据(也即写冲突),此时的同步更加复杂,理解起来都这么复杂,实现起来必然bug百出啊。所以更多的系统比如GFS,简化了这个过程:先选一个replica作为老大(primary replica),然后往这个老大写,再由老大同步给其他小弟(backup replica)。
怎么选老大?
GFS给出了解法:租约lease。具体的说:GFS的master只有一个,启动时三个replica都去向master要lease,master只同意一个,并且把决定告诉其他replica。从而确保一个chunk在系统中只有一个replica获得lease,成为老大。
问题远没有这么简单。如果现在老大fail了,没有老大了呢?另外如果现在的老大“假”fail了呢?
第一:lease有期限。各个replica与master之间有心跳HeartBeat,在心跳中老大每1分钟都向master申请延期。只要当前lease没有过期,其他replica就拿不到lease。
第二:如果老大真fail了,比如机器挂了进程没了,那么超过lease期限后,所有活着的replica都向master要lease,此时master会把lease分给其他小弟。于是有了新老大,除了fail期间大概1分钟系统不可写,其他的一切OK。
第三:如果老大“假”fail了,比如老大跟master之间的网络出问题了,但是老大进程还正常,于此同时其他replica跟master之间的网络没问题,这就是经典的脑裂问题。也就是同一个系统由于网络不连通等问题,被分成了两个部分,每个部分都可能还在正常工作。脑裂往往导致双主、双写等问题。过了一会儿,master会把老大地位(lease)分配给其他小弟,旧老大还活着,岂不是两个老大同时work?如果两个老大同时接受写,那么两个replica之间数据就不一致了。GFS的解决方法是:lease有期限。到了过期时间,旧老大会自动退位,不再担当老大职责。所以只要master在lease过期之后,才把lease重新分配出去,就能保证整个系统中只有一个老大,只有一个replica能够接受写请求。
第四:client的cache中有chunk的若干信息,比如角色,location等。如果lease已经被重新分配,那么client仍旧只有旧老大的信息,怎么办?此时收到写请求的旧老大,会返回特定的错误码给client,然后client找master刷新本地cache,从而认识新老大。
总结一下lease机制的目的:1)确保系统有一个老大,2)确保系统只有一个老大,3)只有老大能够接受record append请求。
注意:lease机制,并不要求多个replica所在机器的时间保持一致,但是的确要求多个机器之间时间的流逝速度一致(或误差在一个有限的区间内)。
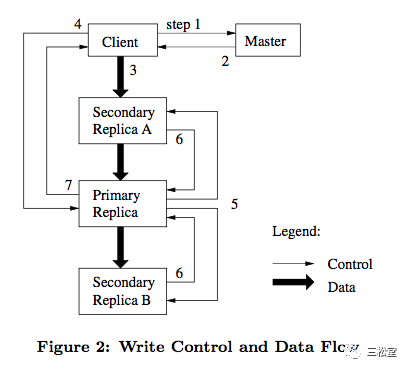
问题2)怎么从老大同步给其他小弟?
如果只有一个client0,这个问题很简单,primary replica直接写给backup replica即可。
但是client0、client1并发写呢?假设replicaA按顺序收到了data0、data1并且写下去,然后并发将两个请求转发给replicaB,由于网络的乱序、延迟导致replicaB按顺序收到的是data1、data0并且写下去,于是两个replica不一致了。
为了避免这种乱序:GFS定义了修改顺序(mutation order)。具体的说:所有record append请求到达老大之后,都在primary replica中取得一个全局连续递增的操作顺序号,然后在primary和backup中都必须按照这个顺序来落盘,从而保证了哪怕是并发写、存在网络乱序,在primary和backup之间也能够保持一致。
问题:
当老大切换之后,新的老大如何开始分配序号?如果每次分配需要都持久化保存已经分配的序号,那么性能肯定很差;如果不持久化保存,那么新老大怎么知道旧老大已经分配了哪些序号呢?
解释:
global mutation order的定义其实是两部分:
1)lease grant order或者叫chunk version number,参见问题7)的说明;这个chunk version number是会被持久化保存的,而且单调递增。
2)mutation serial number in lease。
所以primary切换后,lease grant order会+1,从而保证新primary的global mutation order一定会比旧primary的global mutation order大。
问题3)全部成功才能ack success还是部分成功就可以ack success?
PAXOS/RAFT支持大部分replica成功后,就可以直接返回成功,对应的failover模型也十分复杂。
GFS则相对更加简单,要求所有replica都成功后才能返回成功。
由此我们引申出问题4)如果中途失败了呢?
我们知道2PC协议中,要求所有的particiant都必须成功,如果失败了则要coordinator发起rollback命令。而且2PC还要应对各种失败情况,甚至于会出现未决事务,需要人为解决。
如果GFS采用2PC协议来保证副本一致性,不仅十分复杂,而且当集群达到一定规模之后fail发生概率很大,解决未决事务也是很大的难题。
GFS采用了更加简单的策略:
1) 只有全部replica都成功了,才把offset ack给client。所以一旦成功了,则所有副本都是一致的。
2)primary replica首先将数据append到本地log,然后将mutation order、log offset都发送给backup,并且要求backup有必须以相同的顺序,在相同的offset写下相同的data。
3)如果失败了,则此次写入的offset不会被返回给client,从而保证用户无法读到写入失败的data。这样即便不同副本之间in-consistent也没关系,因为in-consistent的部分,用户没有拿到offset,也自然无法读取到这些数据。
以上策略保证了:对于成功的写入(返回了offset给用户),在不同replica的相同offset上,一定存着相同的数据;对于失败的写入(没有返回offset给用户),在不同replica的相同位置上可能有相同,也可能有不同的数据,但是对用户不可见。
4)失败了,通过不返回offset,来代替2PC的rollback。
注意:包括primary、backup失败了,都是以上处理方法。也即in-consistent的数据保留着,不会被truncate或删除,但是通过给client的offset来保证无法被读到。
问题5)选谁到新老大?新老大如何保证副本一致性?
基于问题4)中阐述的事实:1)primary要求所有副本都按照自己的offset写数据;2)写失败的操作,不会返回offset,不会被用户看到;3)所有副本都成功才ack client。
可知:任何时候,不同replica之间都是consistent的,都是有所有数据的。因此在出现重新选举时,任意一个replica都可以成为primary。而且成为新老大之后,不需要额外操作,所有primary就都已经是一致的。
考虑一个场景:
replicaA是primary,它写数据到本地log,但是还没来得及将commit请求发送给其他backup,replicaA就fail了。随后replicaB被选举为新primary。此时replicaA的log,比replicaB/replicaC要长。后续新老大replicaB写数据时,可能恰好写在了与replicaA重复的offset上,由于primary replicaB要求backup使用与自己一致的offset,所以replicaA上的数据会被覆盖掉。
问题6)fail的角色重新启动后,如何处理?
在RAFT中,fail的角色启动后,会从当前primary同步自己丢失的数据,并且truncate自身多余的数据,直到保持一致后才再次加入集群中提供服务。在PAXOS则进一步放松,哪怕重启后的角色没有补全数据到一致,也能够直接提供服务,后续再异步获取丢失的数据。
在GFS中,则采取了不同的策略:
1)GFS中要求所有副本都成功,当某个replica fail之后,该chunk对应的写入会持续失败,直到master探测到并且re-replica一个新的为止。
2)之前fail的replica,后续重新启动成功了,但是因为已经过期(fail期间丢失了某些record append),所以不被加入到replica group也不被返回给client。相当于不存在一样,等待后台GC任务回收。
总结:fail的replica就彻底fail等着GC,不再如PAXOS/RAFT等后续会继续利用起来。这个处理非常简单,但是也导致了集群内流量风暴;另外跨WAN的网络经常闪断导致fail,这种处理方法会导致很差的failover性能,WAN环境下写入几乎不可用。
7)如何处理stale replica?
当backup fail,写入会持续失败,也就不可能有新的数据被写入;直到master re-replica一个新的副本,写入会继续;从而导致fail的backup丢失了某些数据,成为stale replica。GFS的处理方式是:认为该stale replication不存在,直到后台GC回收该replica。参考问题6)。
如何发现、识别stale replica呢?
每次切主,或者每隔1分钟primary都会去master续期lease,此时chunk version number(lease sequence number)会增长。
然后chunk version number会被通知给所有replica,从而保证活着的replica有最新的chunk version number。对于fail后重启的chunk,会因为错过了通知而停留在老的chunk version上,心跳汇报时会被标定为stale partition,不会被发给client进行读写操作,直到后台GC回收。
注意:Client中因为有cache,在cache过期前仍旧可能到重启后的stale replica中读取数据,此时会读到stale data。但是因为只能够append,所以读到的是premature end,而不是错误的数据。
问题:在没有切主的前提下,此时chunk version number不变,即便replicaA重启了也无法通过chunk version变化而被识别出来,如何探测一个backup是否fail过,成为stale replica了?
设想场景:
假设replicaB是primary。某个时刻replicaA fail了,master re-replica了replicD来代替replicaA。 在replicaA fail期间,replicaB新写入了几条数据,这些数据在replicaA中没有。后来replicaA重启成功,并且向master正常汇报心跳。随后到了1分钟间隔,replicaB到master续期了lease,lease sequence number增长,并且被通知给所有replica,包括A、D。于是replicaA也有了新的lease number。虽然replicaA丢失了数据,但是因为lease sequence number/chunk version number也是最新的,所以不被认为是stale replica。
解释:
1)每隔1分钟,primary都会去master续期lease,此时chunk version number(lease sequence number)会增长。即使不切主,lease number也会变;
2)在replicaA fail期间,对应chunk写入一直失败,所以chunk之间不会不一致。等到timeout时间过后,GFS按照如下顺序进行操作:a) 标记replicaA为stale,b) 开始re-replica,所以在re-replica之前failed replica就已经被标记为stale。
3)参考HDFS的做法:hdfs默认namenode连续10分钟都收不到datanode的心跳,则认为该datanode死了。在10min之前,一直会导致写入失败,因此不会出现replica不一致。10min后的操作是:a) 标记datanode为stale,b) 开始re-replica,所以在re-replica之前failed replica就已经被标记为stale。也就不存在“设想场景”中的问题了。
再考虑一个复杂场景:
当前三个副本完全一致,replicaA是primary。replicaA commit了一条logA到本地,发commit请求给replicaB、replicaC,然后replicaA fail了。该logA在replicaB中apply失败了。同时该logA被网络延迟了,直到replicaB被选举为新的primary后,才到达replicaC中。然后replicaB开始分发logB。replicaC同时获得了logA, logB两条数据,准备apply。
如果如问题2)中考虑的,不同primary切换时如果无法知道前任的mutation order,则replicaB成为primary后会不知道从哪个序号开发分配。此种情况下replicaB可能分配了一个比logA更小的mutation Order给logB。此时在replicC上有2个log:order更小的logB、order更大的logA,而且两者offset一致。如果replicaC按序apply log,则logA会覆盖logB,然后系统不再一致(replicaB中在对应offset上是logB,而replicC中在对应offset上是logA,而且该offset会被返回给用户)。
处理方法:每次grant lease时,master都分配一个chunk version number,而且递增。当replicB被选为新primary时,有了更大的chunk version number。logB携带了更大的chunk version number,replicC在考虑顺序时,是将chunk version number+mutation order共同考虑,且chunk version number为第一顺序、mutation order为第二顺序进行比较。logA的顺序更小,logB的顺序更大,故replicC先apply logA,然后apply logB,系统仍旧保持一致。
这个设计保证了mutation order在分配时不需要持久化保存,而每个1min,master分配的chunk version number则必须持久化。由于持久化频率较低,所以性能不会有太大影响。
另外,在master给client的metadata、给其他chunkserver的instruction中除了包含primary信息之外,还包含chunk version number,用于防止stale chunk。
master、primary、client通过比较replica的chunk version来判断当前replica是否过期了。
以上讨论覆盖了primary fail、backup fail、切主、脑裂、新老primary都存在且数据交叉等不同failover场景的处理方法,基本上覆盖到了分布式场景下一致性相关的问题。
Master
论文中master是SOF。
master负责所有的Heartbeat的处理,以及lease的grant和续期。这一点区别于parcificA,在parcificA中只有第一次lease是由master发放的,后续的续期都是primary与backup之间进行,减少了master的压力。中心化获取lease的另外一个缺点是:master不可用时,整个系统都会变得不可用。但是parcificA的好处在于,当中心点不可用时,primary和secondaries还可以继续工作。
master重启后,如果从replica heartbeat中看到了更大的chunk version number,则认为自己fail了,并且认同这个更大的chunk version number。
master通过WAL以及定期checkpoint来减少failover时间。
Client开发
由于GFS只支持at least once的一致性语义,因此基于GFS开发,application需要注意一些事情:
1)任意一个replica失败都会导致写入失败,所以写入要有重试。
2)client带着offset来读:没有问题,失败的都会不可见。
3)read duplicated:client不带着offset来读,此时需要在chunk内部依次遍历。如何跳过失败的写入?a) record append不会有碎片混淆问题;b) 每个写入都有length来保证读取到一个record;c) 每个record都有checksum来判断当前record是否完整写入;d)如果上面的条件都满足,则不会读到错误的数据。但是因为client在失败时会重试,所以某个replica中可能包含正确record的duplication,需要在业务上做unique id保证去重。
4) stale read:由于client cache的存在,在cache尚未刷新期间,可能导致client被路由到了stale replica上,无法读到最新的内容,直到cache timeout或者reopen of file。注意:由于数据是append only的,stale data不是错误的,而是premature end rather than outdated data.
5)read uncommitted:当不带offset读取时,client可能读到正在写入的数据。比如一个primary已经committed,但是其他replica还没有commit,此时却可能已经被client读到。
一致性模型比较
以下将gfs与其他一致性模型进行简单对比。(待补充更多)
GFS的一致性模型是:at least once。
GFS employs a simple model which guarantees that the writes are done atleast once ( i.e. it does not guarantee that there are no duplicates)
In this simple cycle, since a failure at any replica makes the client try the write again, there might be some duplicate data. Therefore GFS does not guarantee against duplicates but in anyway the write will be carried out atleast once.
对比
parcificA
PAXOS
RAFT
HDFS改进
在HDFS中针对GFS的论文进行了很多改进:
1) 提供dfs.replication参数,作为默认副本数;提供dfs.namenode.replica.min来表示最小的允许副本数。写入时,当dfs.namenode.replica.min被满足就认为成功,然后后台异步将副本恢复至dfs.replication。所以并不要求所有副本都写成功才算成功。
2)默认连续10min心跳收不到才认为datanode failed,然后开始将该datanode放到replication queue中,准备复制。这个带来的问题是:在hbase的场景中,如果hbase region server failed timeout是30s,但是datanode timeout是10min,则RS恢复了也可能仍旧在写或读一个已经fail了的datanode,于是继续不可用。
3)在namenode中记录了chunk的长度,可以判定哪些是stale的,从而在read、write pipeline中可以决定将哪些replica路由给client。
Reference
http://www.cs.utah.edu/~stutsman/cs6963/lecture/04/
gfs paper
https://users.cs.duke.edu/~chase/cps510/
http://www.cs.utah.edu/~stutsman/cs6963/
http://hadoop-common.472056.n3.nabble.com/Confusion-between-dfs-replication-and-dfs-namenode-replication-min-options-in-hdfs-site-xml-td4124375.html
https://stackoverflow.com/questions/34459602/what-hadoop-will-do-after-one-of-datanodes-down
https://community.hortonworks.com/articles/16144/write-or-append-failures-in-very-small-clusters-un.html
http://blog.cloudera.com/blog/2015/02/understanding-hdfs-recovery-processes-part-1/
https://jira.apache.org/jira/browse/HDFS-3703
https://community.hortonworks.com/questions/9451/how-does-restarting-a-data-node-affect-block-repli.html
