




一、NUMA出现的背景
处理器的对称与非对称
SMP(Symmetric Multiprocessing):对称多处理器架构,是目前最常见的多处理器计算机架构
AMP(Asymmetric Multiprocessing):非对称多处理器架构,则是与SMP相对的概念
两者之间主要区别有以下几点:
| SMP | AMP |
|---|---|
| 多个处理器都是同构的,使用相同架构的CPU | 多个处理器则可能是异构的 |
| 多个处理器共享同一内存地址空间 | 每个处理器则拥有自己独立的地址空间 |
| 多个处理器操通常共享一个操作系统的实例 | 每个处理器可以有或者没有运行操作系统,运行操作系统的CPU也是在运行多个独立的实例 |
| 多处理器之间可以通过共享内存来协同通信 | 需要提供一种处理器间的通信机制 |
从上面的特性中可以看出,现今主流的x86多处理器服务器(UMA架构与NUMA架构)都是SMP架构的, 而很多嵌入式系统则是AMP架构的。
UMA 架构
x86多处理器发展历史上,早期的多核和多处理器系统都是UMA(Uniform Memory Access)架构的。如下所示,这种架构下,多个CPU通过同一个北桥(North Bridge)芯片与内存链接。北桥芯片里集成了内存控制器(Memory Controller)。这样的访问对于软件层面来说非常容易实现:总线模型保证所有的内存访问是一致的,即每个处理器核心共享相同的内存地址空间,不必考虑由不同内存地址之前的差异。
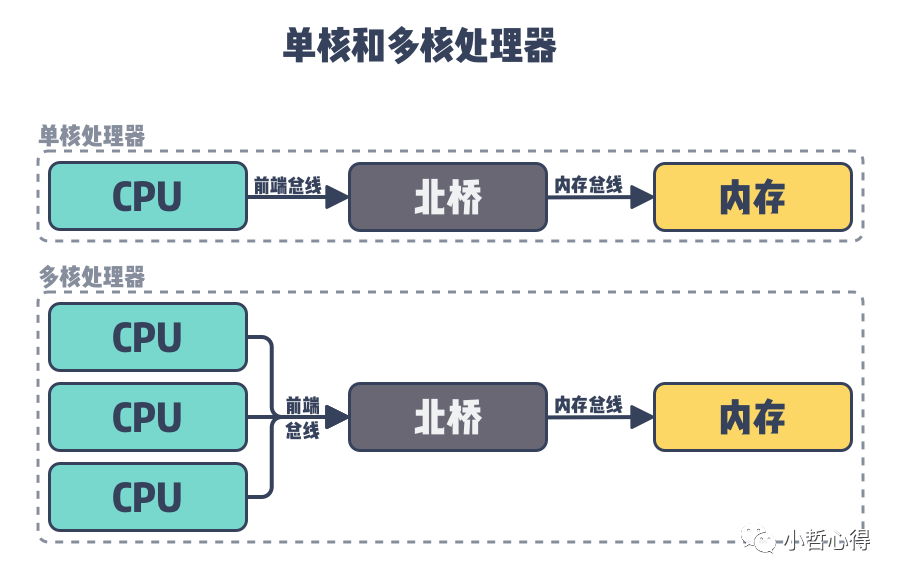
下图是一个典型的早期 x86 UMA 系统,四路处理器通过 FSB (前端系统总线, Front Side Bus) 和主板上的内存控制器芯片 (MCH, Memory Controller Hub) 相连,DRAM 是以 UMA 方式组织的,延迟并无访问差异。
NUMA 出现的原因
在NUMA架构出现前,CPU朝着频率越来越高的方向发展(纵向发展)。受到物理极限的挑战,又转为向着核心数越来越多的方向发展(横向发展),越来越多的核心被尽可能地塞进了同一块芯片上。
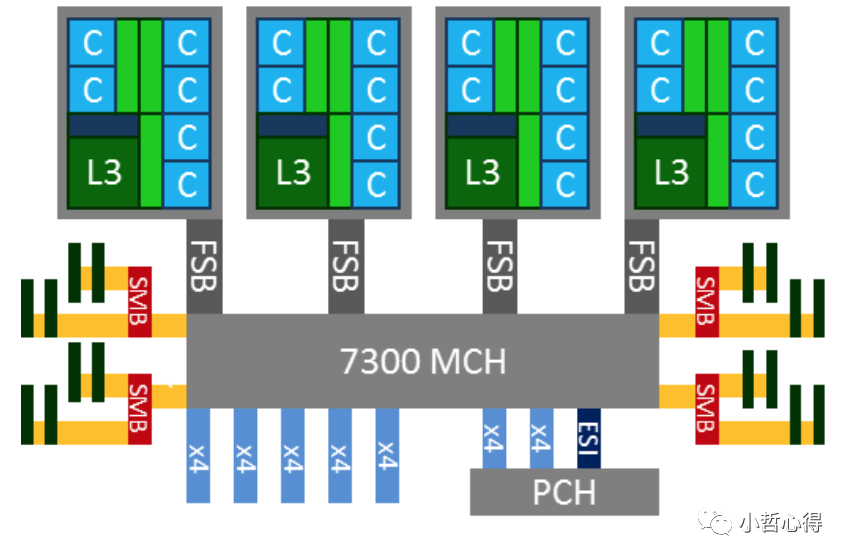
在UMA 架构下,各个核心对于内存带宽的争抢访问成为了瓶颈;此时软件、OS方面对于SMP多核心CPU的支持也愈发成熟,故而出现了NUMA(Non-uniform memory access)架构。利用NUMA技术,可以较好地解决原来SMP系统的扩展问题,在一个物理服务器内可以支持上百个CPU。但NUMA技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
AMD 在引入64 位 x86 架构时,实现了 NUMA,Intel 也推出了 x64 的 Nehalem 架构,x86 终于全面进入到 NUMA 时代。下图就是一个典型的 x86 的 NUMA 架构:
二、NUMA架构的组成
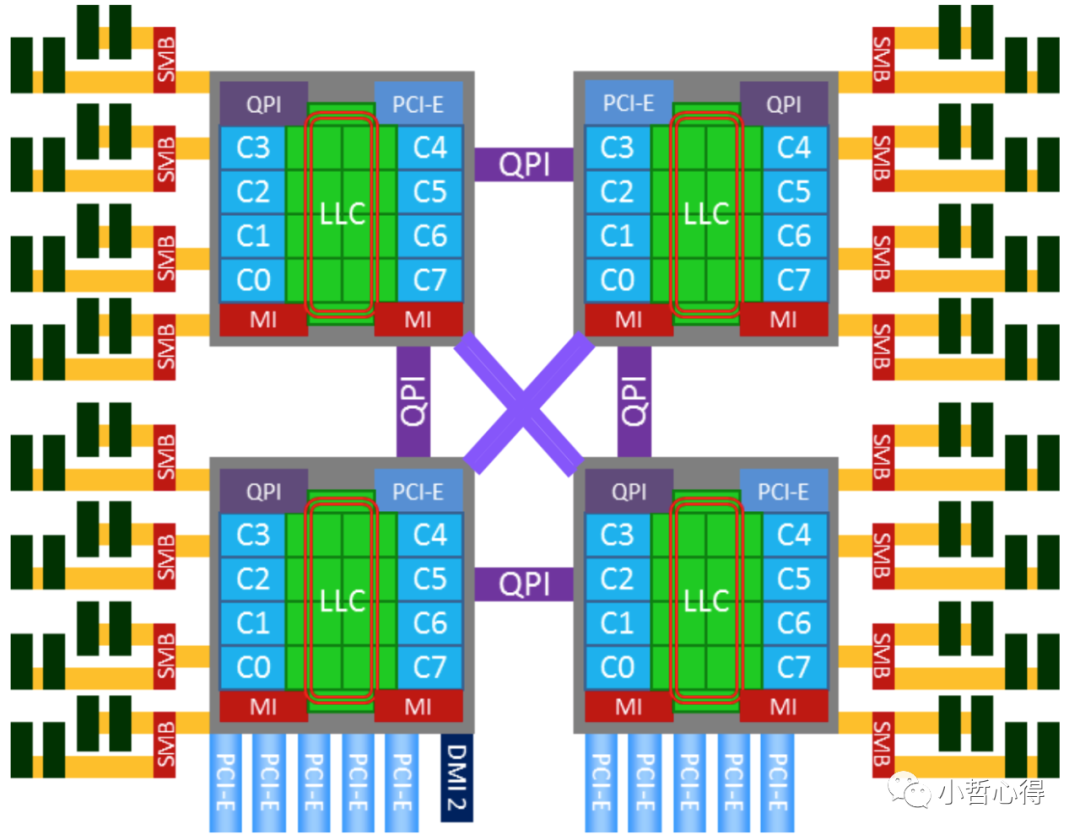
NUMA架构中,不同的内存器件和CPU核心从属不同的Node,内存控制器芯片(IMC,Integrated Memory Controller)被集成到处理器内部。在 Node 内部,架构类似SMP,使用IMC Bus进行不同核心间的通信;不同的 Node间通过QPI(Quick Path Interconnect)进行通信,如下图所示:
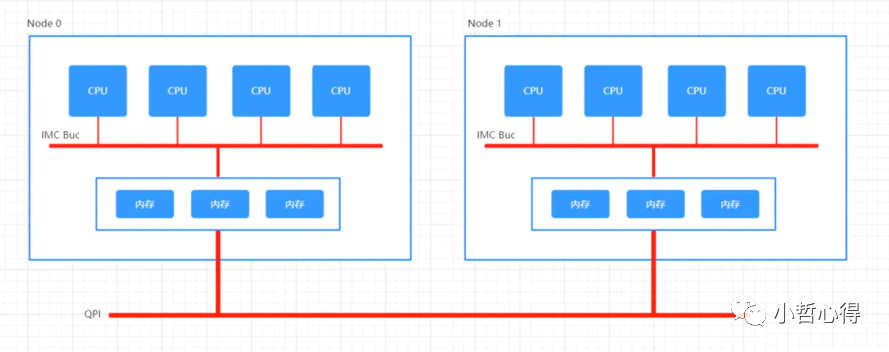
很明显的,在上图所示的架构之下,两个socket各自管理1/2的内存插槽,如果要访问不属于本socket的内存则必须通过QPI link。也就是说内存的访问出现了本地/远程(local/remote)的概念,内存的延时是会有显著的区别的。
一个NUMA Node内部是由一个物理CPU和它所有的本地内存(Local Memory) 组成的。广义的讲, 一个NUMA Node内部还包含本地IO资源,对大多数Intel x86 NUMA平台来说,主要是PCIe总线资源。ACPI规范就是这么抽象一个NUMA Node的。
物理 CPU:一个CPU Socket里可以由多个CPU Core和一个Uncore部分组成。每个CPU Core内部又可以由两个CPU Thread组成。每个CPU thread都是一个操作系统可见的逻辑CPU。对大多数操作系统来说,一个八核HT打开的CPU会被识别为16个CPU。先介绍一下里面包含的概念
Socket
Node
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题。每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量。通常一个 Socket 有一个 Node,也有可能一个 Socket 有多个 Node。
Core
Uncore
Intel x86物理CPU里没有放在Core里的部件都被叫做Uncore。Uncore里集成了过去x86 UMA架构时代北桥芯片的基本功能。在Nehalem时代,内存控制器被集成到CPU里,叫做iMC(Integrated Memory Controller)。而PCIe Root Complex还做为独立部件在IO Hub芯片里。到了SandyBridge时代,PCIe Root Complex也被集成到了CPU里。现今的Uncore部分,除了iMC,PCIe Root Complex,还有QPI(QuickPath Interconnect)控制器, L3缓存,CBox(负责缓存一致性),及其它外设控制器。
本地内存
在Intel x86平台上,所谓本地内存,就是CPU可以经过Uncore部件里的iMC访问到的内存。而那些非本地的远程内存(Remote Memory),则需要经过QPI的链路到该内存所在的本地CPU的iMC来访问。
一个Socket对应一个物理CPU。这个词大概是从CPU在主板上的物理连接方式上来的,可以理解为 Socket 就是主板上的 CPU 插槽。处理器通过主板的Socket来插到主板上。尤其是有了多核(Multi-core)系统以后,Multi-socket系统被用来指明系统到底存在多少个物理CPU。
CPU的运算核心。x86包含了CPU运算的基本部件,如逻辑运算单元(ALU), 浮点运算单元(FPU), L1和L2缓存。一个Socket里可以有多个Core。如今的多核时代,即使是Single Socket的系统, 也是逻辑上的SMP系统。但是,一个物理CPU的系统不存在非本地内存,因此相当于UMA系统。
在Intel x86上,NUMA Node之间的互联是通过 QPI((QuickPath Interconnect) 连接的。CPU的Uncore部分有QPI的控制器来控制CPU到QPI的数据访问。
三、Linux对NUMA的策略
Linux,内核mm/mmzone.c , include/linux/mmzone.h文件定义了NUMA的数据结构和操作方式,Linux Kernel中NUMA的调度位于kernel/sched/core.c函数int sysctl_numa_balancing中,其调度策略有以下几项:
在一个启用了NUMA支持的Linux中,Kernel不会将任务内存从一个NUMA node搬迁到另一个NUMA node;
在正常的调度之中,CPU的core会尽可能的使用可以local访问的本地core,使得在某些 CPU 中出现内存倾斜;
如果某个 CPU 中持续出现严重的内存资源紧张,则会触发系统的 kswapd 服务开始做内存回收操作;
NUMA node之间有不同的拓扑结构,各个 node 之间的访问会有一个距离(node distances)的概念,距离不同响应时间也不同。
查看CPU和NUMA的拓扑信息
$ numactl --hardwareavailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23node 0 size: 65175 MBnode 0 free: 3128 MBnode 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31node 1 size: 65536 MBnode 1 free: 9274 MBnode distances:node 0 10: 10 211: 21 10
从上述输出结果可以看出,该机器上包含两个 NUMA 节点,每个节点上都包含 16 个 CPU 以及 64GB 的内存,最后的节点距离(node distances)可以看出两个 NUMA 节点访问内存的开销,其中 NUMA 节点 0 和 NUMA 节点 1 互相访问对方内存的延迟是各自节点访问本地内存的 2.1 倍(21 / 10 = 2.1),所以如果 NUMA 节点 0 上的进程如果在节点 1 上分配内存,会增加进程的延迟。
正是因为 NUMA 节点访问不同内存的开销不同,所以操作系统会为应用程序提供接口控制 CPU 和内存的分配策略,在 Linux 系统中,可以使用 numactl 命令控制进程使用的 CPU 和内存。
numactl 提供了 cpunodebind 和 physcpubind 两种策略为进程分配 CPU,这两种策略分别提供了不同粒度的绑定方法:
cpunodebind — 将进程绑定到某几个 NUMA 节点上;
physcpubind — 将进程绑定到某几个物理 CPU 上;
除了这两种 CPU 分配策略之外,numactl 还提供四种不同的内存分配策略,分别是:localalloc、preferred、membind 和 interleave:
localalloc — 总是在当前节点上分配内存;
preferred — 倾向于在特定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配;
membind — 只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败;
interleave — 内存会在传入的节点上依次分配(Round Robin),当指定节点的内存不足时,操作系统会在其他节点上分配。
从上面的策略可以看出,NUMA 架构实际就是系统为了让 CPU 能够尽可能利用高性能的内存资源.对于某些大内存访问的应用,比如MySQL这可能会导致内存资源分配不均匀的问题。
四、NUMA 操作
检查NUMA设置
由于 NUMA 的设置是关于多个 CPU 对多个内存区进行非均匀的内存分配,所以如果整个系统默认就只有一个内存区,则无需做调整了。
以 Linux Centos 7.6 系统为例,通过以下命令可以查看 CPU 和内存的分配情况
$> numactl --hardwareavailable: 1 nodes (0)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31node 0 size: 130696 MBnode 0 free: 117220 MBnode distances:node 00: 10
如果 available = 1 nodes,则证明无需做其他 NUMA 的设置。
如果出现 available > 1 nodes,则证明存在多个内存区域,需要主动关闭 NUMA 设置。
$> numactl --hardwareavailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23node 0 size: 65175 MBnode 0 free: 2066 MBnode 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31node 1 size: 65536 MBnode 1 free: 11286 MBnode distances:node 0 10: 10 211: 21 10
关闭NUMA
以 Linux Centos 7.6 系统为例,使用 root 用户对 etc/default/grub 文件进行编辑,在 GRUB_CMDLINE_LINUX 参数的末尾增加 :numa=off,例如:
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off"
如果系统中存在/etc/grub2.cfg 文件(MBR 分区表),则执行
grub2-mkconfig -o etc/grub2.cfg
如果系统中存在/etc/grub2-efi.cfg 文件(EFI + GPT分区表),则执行
grub2-mkconfig -o etc/grub2-efi.cfg
然后重启服务器,再检查系统的启动日志,可以发现系统已经主动关闭了NUMA的设置。
$> grep -i numa var/log/dmesg…[ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-693.21.1.el7.x86_64 root=/dev/mapper/vg_root-root ro crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off[ 0.000000] NUMA turned off[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-693.21.1.el7.x86_64 root=/dev/mapper/vg_root-root ro crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off…
同理,通过 numactl --hardware 命令检查,同样也会显示 available = 1 nodes。
通过numa-maps-summary.pl工具查看 NUMA 使用情况
$> perl numa-maps-summary.pl < /proc/3110447/numa_mapsN0 : 10955968 ( 41.79 GB)N1 : 9116857 ( 34.78 GB)active : 8344965 ( 31.83 GB)anon : 20023608 ( 76.38 GB)dirty : 20069176 ( 76.56 GB)kernelpagesize_kB: 1804 ( 0.01 GB)mapmax : 227 ( 0.00 GB)mapped : 3836 ( 0.01 GB)
五、 NUMA 对 MySQL 的影响
几乎所有NUMA + MySQL
关键字的搜索结果都会指向:Jeremy Cole大神的两篇文章
The MySQL “swap insanity” problem and the effects of the NUMA architecture A brief update on NUMA and MySQL
大神解释的非常详尽,有兴趣的读者可以直接看原文。结合两边文章和个人的理解,认为NUMA 架构对于数据库的的影响有以下几点:
由于内存页没有动态调整策略,使得大部分内存页都集中在node 0上,导致的内存资源紧张,或者持续触发 kswapd 服务,影响性能;
因为
Reclaim
默认策略优先淘汰本Chip上的内存,使得大量有用内存被换出,导致cache 数据被释放,降低数据库访问时的内存命中率;整体系统剩余大量的内存,但是数据库却遇到 OOM 错误,甚至被 Killer 强行退出服务的现象;
操作系统出现内存不足问题,导致大量数据被暂时保存于Swap交换空间中,系统响应速度降低,甚至出现卡死现象。
现在简单分析一下 NUMA 架构下可能存在的分配不均的情况
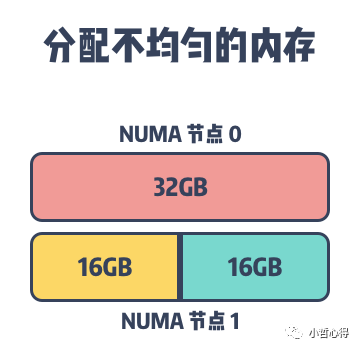
因为 MySQL 等数据库的运行会占用大量的内存,在默认情况进程会先在所在的 NUMA 节点上分配内存,当本地内存不足时,才会在远程分配内存。如上图所示,主机上包含两个 NUMA 节点,其中每个节点都有 32GB 的内存,但是当 MySQL InnoDB 的缓存池占用 48GB 的内存时,它会在 NUMA 节点 0 和 NUMA 节点 1 分别分配 32GB 和 16GB 的内存。
虽然 48GB 的内存远远没有到达主机 64GB 的内存上限,但是当某些数据必须要在 NUMA 节点 0 的内存上分配时,就会导致 NUMA 节点 0 中的内存被交换到了文件系统上为新的内存请求让出位置,InnoDB 缓存池中内存的频繁换入和换出会使 MySQL 的查询随机地出现延迟,而一旦发生了交换分区,可能就是性能螺旋下降的开始。
Linux 中的 zone_reclaim_mode
可以允许工程师设置在 NUMA 节点内存不足时内存的回收策略,在默认情况下该模式都会处于关闭状态,如果我们在 NUMA 系统中通过该配置启用了激进的内存回收策略,可能会影响程序的性能,MySQL 也会受到内存回收策略的影响,但是仅仅关闭该策略并不会解决它遇到的频繁触发交换分区的问题。
想要解决该问题,我们需要使用前面提到的 numactl 将内存的分配策略改为 interleave
,使用该内存分配策略会使得 MySQL 的内存均匀地分配到不同的 NUMA 节点上,能够降低页面频繁换入换出的可能性。
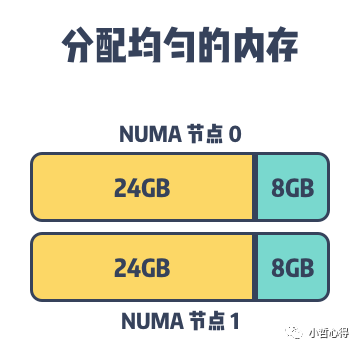
该问题并不是 MySQL 独有的,很多占用大量内存的数据库都会遇到上述问题,虽然使用 interleave
能够暂时解决这些问题,但是 MySQL 进程访问远程内存时,与本地内存相比仍然会遇到性能损失,想要一劳永逸地避免服务在 NUMA 上运行的额外开销,最好的办法还是开发能够感知底层 NUMA 架构的应用程序。以 MySQL 为例,Jeremy Cole 在文章中提出了如下的修改,可以更好地利用 NUMA 的本地内存:
将缓存池中的数据按照块或者索引智能地分配到不同节点上
numactl --interleave=all
;为正常的查询线程保留默认的分配策略,内存还是会优先分配本地节点上,将简单的查询线程重新调度到能够访问本地内存的节点上;
在MySQL进程启动前,使用
sysctl -q -w vm.drop_caches=3
清空文件缓存所占用的空间Innodb在启动时,就完成整个
Innodb_buffer_pool_size
的内存分配
六、PERCONA 对 NUMA 的优化
在 percona 官方文档中可以看到,自5.5.28-29.1版本后,就引入了Twitter关于 NUMA 的优化,在mysqld_safe启动时添加以下参数即可
variable `flush_caches`Command Line: YesConfig File: YesLocation: mysqld_safeDynamic: NoVariable Type: BooleanDefault Value: 0Range: 0/1When enabled this will flush and purge buffers/caches before starting the server to help ensure NUMA allocation fairness across nodes. This option is useful for establishing a consistent and predictable behavior for normal usage and/or benchmarking.variable `numa_interleave`Command Line: YesConfig File: YesLocation: mysqld_safeDynamic: NoVariable Type: BooleanDefault Value: 0Range: 0/1When this option is enabled, mysqld will run with its memory interleaved on all NUMA nodes by starting it with numactl --interleave=all. In case there is just 1 CPU/node, allocations will be “interleaved” between that node.
七、总结
NUMA 架构的目的就是为了让 CPU 能够尽可能利用高性能的内存资源,对于MySQL大内存访问的应用,可能会导致内存资源分配不均匀的问题。那么问题究竟是出在哪里了呢?
对于NUMA架构来说,本身没有错,是CPU发展的一种必然趋势。但是NUMA的出现使得操作系统不得不关注内存访问速度不平均的问题。
Linux Kernel内存分配策略的初衷是好的,为了内存更接近需要他的线程,但是没有考虑到数据库这种大规模内存使用的应用场景。同时缺乏动态调整的功能,使得这种悲剧在内存分配的那一刻就被埋下了伏笔。
对于 MySQL来说,数据库设计者也许从一开始就不会意识到NUMA的流行,或者甚至说提供一个透明稳定的内存访问是操作系统最基本的职责,但是作为使用者可能需要更好的理解 NUMA。
我们作为软件的维护者或是软件工程师,可能认为操作系统以及底层的硬件与我们的距离非常遥远,在开发软件时不需要考虑这么多细节,对于绝大多数的应用程序来说,这一点都是成立的,操作系统能够为我们屏蔽很多底层的实现细节,能够将更多的精力投入到业务逻辑的实现上。
正如前面文章中提到的,哪怕操作系统做出再多的隔离和抽象,物理世界存在的限制还是会在暗处影响我们的应用程序,想要提高软件的性能,必须要关注下层甚至更底层的实现细节。
参考文档
The MySQL “swap insanity” problem and the effects of the NUMA architecture:http://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/ A brief update on NUMA and MySQL:http://blog.jcole.us/2012/04/16/a-brief-update-on-numa-and-mysql/ Percona Server for MySQL 文档:https://www.percona.com/doc/percona-server/5.5/performance/innodb_numa_support.html 为什么 NUMA 会影响程序的延迟:https://draveness.me/whys-the-design-numa-performance/#fn:4 NUMA架构的CPU -- 你真的用好了么 :http://cenalulu.github.io/linux/numa/ NUMA架构与数据库的一些思考:https://cdn.modb.pro/db/28677 NUMA架构详解:https://houmin.cc/posts/b893097a/#comments 深挖NUMA:https://zhuanlan.zhihu.com/p/33621500 这绝对是你的知识盲点,NUMA的为什么存在:http://blog.itpub.net/69999013/viewspace-2770468/
