




微信公众号:二进制人生
专注于嵌入式linux开发。问题或建议,请发邮件至hjhvictory@163.com。
更新日期:2020/04/01,内容整理自网络,转载请注明出处。
内存管理系列文章:
内容整理自网络和自己的认知,旨在学习交流,请勿用于商业用途。
linux内存管理(一)开篇介绍
linux内存管理(二)两种内存架构和三种内存模型
linux内存管理(三)内存管理三级结构
linux内存管理(四)分页机制概述
linux内存管理(五)内存源头
linux内存管理(六)分页机制的演进
linux内存管理(七)arm页表机制
linux内存管理(七七)arm硬件页表
linux内存管理(八)页表最初的初始化--从内核启动的第一段代码谈起
linux内存管理(九)内存管理临时机制-memblock
linux内存管理(十)内核空间虚拟内存布局
linux内存管理(十一)arm低端内存映射
linux内存管理(十二)arm高端内存映射之kmap映射(永久映射)
linux内存管理(十三)arm高端内存映射之fix映射(临时映射)
linux内存管理(十四)arm高端内存之vmalloc(非连续内存区映射)
linux内存管理(十五)伙伴系统概述
linux内存管理(十六)伙伴系统实现
linux内存管理(十七)slab分配器实现
linux内存管理(十九)brk和sbrk介绍
linux内存管理(二十)malloc背后的机制--简单阐述(番外篇)
linux内存管理(二十一)malloc背后的机制--深入探索
linux内存管理(十九)总结
目录
前言结论具体内容内存分配的原理具体分配过程思考
前言
今天在阅读博客时发现了一篇好文,和大家分享下,查了下网上转来转去一大堆,找不到原作者,如知道原作者可以联系我,我会备注上。
文中的知识点我还没有阅读源码验证,但写得挺好的,把它纳入我们的内存管理系列文章吧,姑且叫番外篇,讲的比较浅显,大家阅读起来应该没什么压力。
结论
1)当开辟的空间小于 128K 时,调用 brk()函数,malloc 的底层实现是系统调用函数 brk(),其主要移动指针 _enddata(此时的 _enddata 指的是 Linux 地址空间中堆段的末尾地址,不是数据段的末尾地址)
2)当开辟的空间大于 128K 时,mmap()系统调用函数来在虚拟地址空间中(堆和栈中间,称为“文件映射区域”的地方)找一块空间来开辟。
关于brk和mmap我后面会推出相应文章
。
具体内容
当一个进程发生缺页中断的时候,进程会陷入核心态,执行以下操作:
1)检查要访问的虚拟地址是否合法
2)查找/分配一个物理页
3)填充物理页内容(读取磁盘,或者直接置0,或者什么都不做)
4)建立映射关系(虚拟地址到物理地址的映射关系)
5)重复执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页就是 majfit(major fault:大错误),否则就是 minflt(minor fault:小错误)
内存分配的原理
从操作系统角度看,进程分配内存有两种方式,分别由两个系统调用完成:brk 和 mmap (不考虑共享内存)
1)brk 是将数据段(.data)的最高地址指针 _edata 往高地址推
2)mmap 是在进程的虚拟地址空间中(堆和栈中间,称为“文件映射区域”的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
具体分配过程
情况一:malloc 小于 128K 的内存,使用 brk 分配。
将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
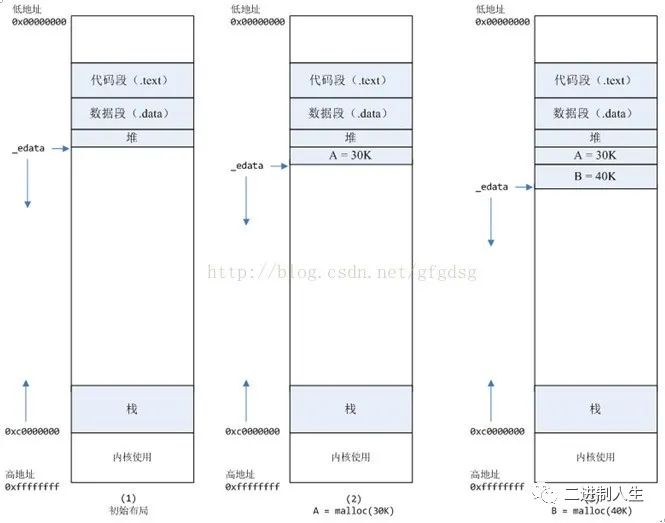
1,进程启动的时候,其(虚拟)内存空间的初始布局如图1所示
2,进程调用A=malloc(30K)以后,内存空间如图2:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配
你可能会问:难道这样就完成内存分配了?
事实是:_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3,进程调用B=malloc(40K)以后,内存空间如图3。
情况二:malloc 大于 128K 的内存,使用 mmap 分配(munmap 释放)
4,进程调用C=malloc(200K)以后,内存空间如图4。
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存
这样子做主要是因为:
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,因为只有一个_edata 指针,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5,进程调用D=malloc(100K)以后,内存空间如图5。
6,进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。
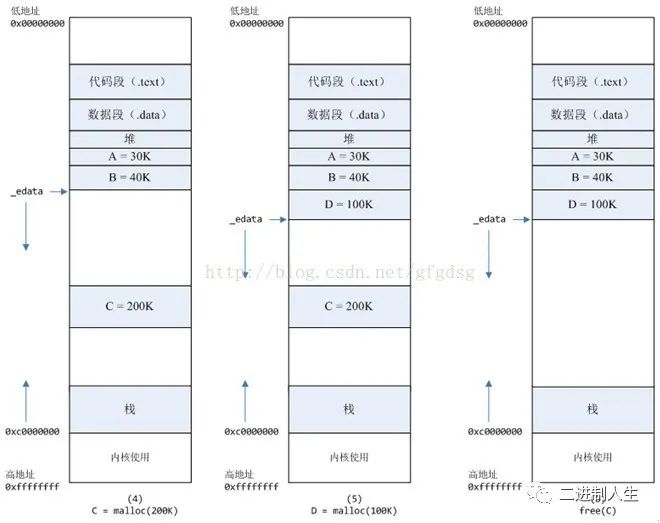
7,进程调用free(B)以后,如图7所示。
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了
8,进程调用free(D)以后,如图8所示。
B和D连接起来,变成一块140K的空闲内存。
9,默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
思考
既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。因此, glibc 的 malloc 实现中,充分考虑了 brk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD,
每天进步一点点…
图:二进制人生公众号

