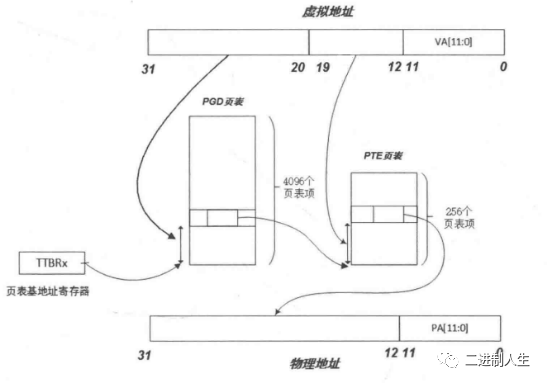
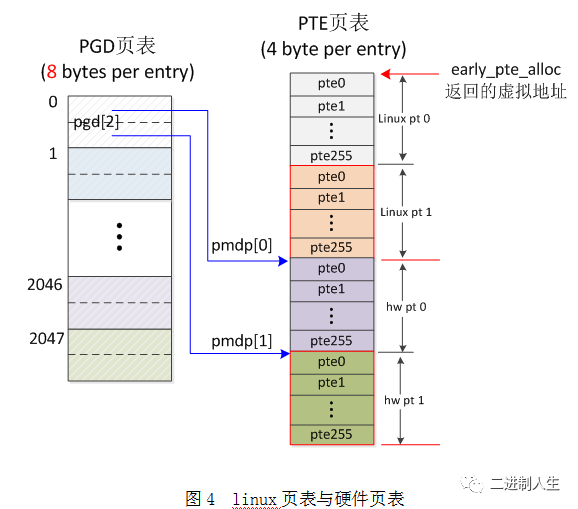
1)PTE entry中的低12位大部分被硬件使用了,没有多余的空位用于linux需要的“accessed”、“dirty”等标志位。 参考内核代码注释:Hardware-wise, we have a two level page table structure, where the first level has 4096 entries, and the second level has 256 entries. Each entry is one 32-bit word. Most of the bits in the second level entry are used by hardware, and there aren't any "accessed" and "dirty" bits。
/* * Hardware-wise, we have a two level page table structure, where the first * level has 4096 entries, and the second level has 256 entries. Each entry * is one 32-bit word. Most of the bits in the second level entry are used * by hardware, and there aren't any "accessed" and "dirty" bits. * * Linux on the other hand has a three level page table structure, which can * be wrapped to fit a two level page table structure easily - using the PGD * and PTE only. However, Linux also expects one "PTE" table per page, and * at least a "dirty" bit. * * Therefore, we tweak the implementation slightly - we tell Linux that we * have 2048 entries in the first level, eachof which is8 bytes (iow, two * hardware pointers to the second level.) The second level contains two * hardware PTE tables arranged contiguously, preceded by Linux versions * which contain the state information Linux needs. We, therefore, end up * with512 entries in the "PTE" level. * * This leads to the page tables having the following layout: * * pgd pte * | | * +--------+ * | | +------------+ +0 * +- - - - + | Linux pt 0 | * | | +------------+ +1024 * +--------+ +0 | Linux pt 1 | * | |-----> +------------+ +2048 * +- - - - + +4 | h/w pt 0 | * | |-----> +------------+ +3072 * +--------+ +8 | h/w pt 1 | * | | +------------+ +4096 * * See L_PTE_xxx below for definitions of bits in the "Linux pt", and * PTE_xxx for definitions of bits appearing in the "h/w pt". * * PMD_xxx definitions refer to bits in the first level page table. * * The "dirty" bit is emulated by only granting hardware write permission * iff the page is marked "writable"and"dirty"in the Linux PTE. This * means that a write to a clean page will cause a permission fault, and * the Linux MM layer will mark the page dirty via handle_pte_fault(). * For the hardware to notice the permission change, the TLB entry must * be flushed, and ptep_set_access_flags() does that for us. * * The "accessed"or"young" bit is emulated by a similar method; we only * allow accesses to the page if the "young" bit isset. Accesses to the * page will cause a fault, and handle_pte_fault() will set the young bit * for us aslongas the page is marked present in the corresponding Linux * PTE entry. Again, ptep_set_access_flags() will ensure that the TLB is * up todate. * * However, when the "young" bit is cleared, we deny access to the page * by clearing the hardware PTE. Currently Linux does not flush the TLB * for us in this case, which means the TLB will retain the transation * until either the TLB entry is evicted under pressure, or a context * switch which changes the user space mapping occurs. */
/* * "Linux" PTE definitions. * * We keep two sets of PTEs - the hardware and the linux version. * This allows greater flexibility in the way we map the Linux bits * onto the hardware tables, and allows us to have YOUNG and DIRTY * bits. * * The PTE table pointer refers to the hardware entries; the "Linux" * entries are stored 1024 bytes below. */ #define L_PTE_VALID (_AT(pteval_t, 1) << 0)/* Valid */ #define L_PTE_PRESENT(_AT(pteval_t, 1) << 0) #define L_PTE_YOUNG (_AT(pteval_t, 1) << 1) #define L_PTE_DIRTY (_AT(pteval_t, 1) << 6) #define L_PTE_RDONLY(_AT(pteval_t, 1) << 7) #define L_PTE_USER (_AT(pteval_t, 1) << 8) #define L_PTE_XN (_AT(pteval_t, 1) << 9) #define L_PTE_SHARED(_AT(pteval_t, 1) << 10)/* shared(v6), coherent(xsc3) */ #define L_PTE_NONE(_AT(pteval_t, 1) << 11) ......
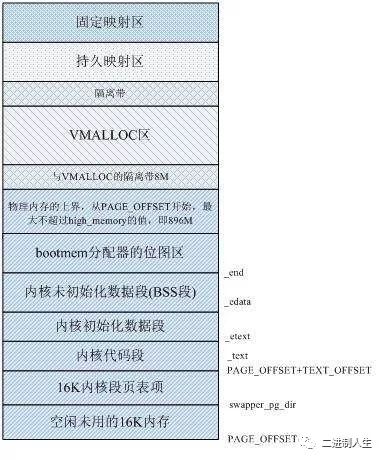
/* * swapper_pg_dir is the virtual address of the initial page table. * We place the page tables 16K below KERNEL_RAM_VADDR. Therefore, we must * make sure that KERNEL_RAM_VADDR is correctly set. Currently, we expect * the least significant 16 bits to be 0x8000, but we could probably * relax this restriction to KERNEL_RAM_VADDR >= PAGE_OFFSET + 0x4000. */ #define KERNEL_RAM_VADDR (PAGE_OFFSET + TEXT_OFFSET) #if (KERNEL_RAM_VADDR & 0xffff) != 0x8000 #error KERNEL_RAM_VADDR must start at 0xXXXX8000 #endif
#ifdef CONFIG_ARM_LPAE /* LPAE requires an additional page for the PGD */ #define PG_DIR_SIZE 0x5000 #define PMD_ORDER 3 #else #define PG_DIR_SIZE 0x4000 #define PMD_ORDER 2 #endif