




本节参考了csdn博主JeanCheng的文章,地址:https://blog.csdn.net/gatieme/article/details/52384075,特表感谢。我针对最新内核做了一些修改和加了自己的理解。
对于内存管理,Linux采用了与具体体系架构不相关的设计模型,实现了良好的可伸缩性。它主要由内存节点node、内存区域zone和物理页框page三级架构组成。内存节点node是为了解决多处理器内存访问效率低的问题,而内存区域zone是为了解决32位系统内核只有1G的虚拟地址空间,无法管理大于1G的物理内存这个问题,区按照用途划分成几种类型,比如低端内存区,高端内存区,DMA内存区等。
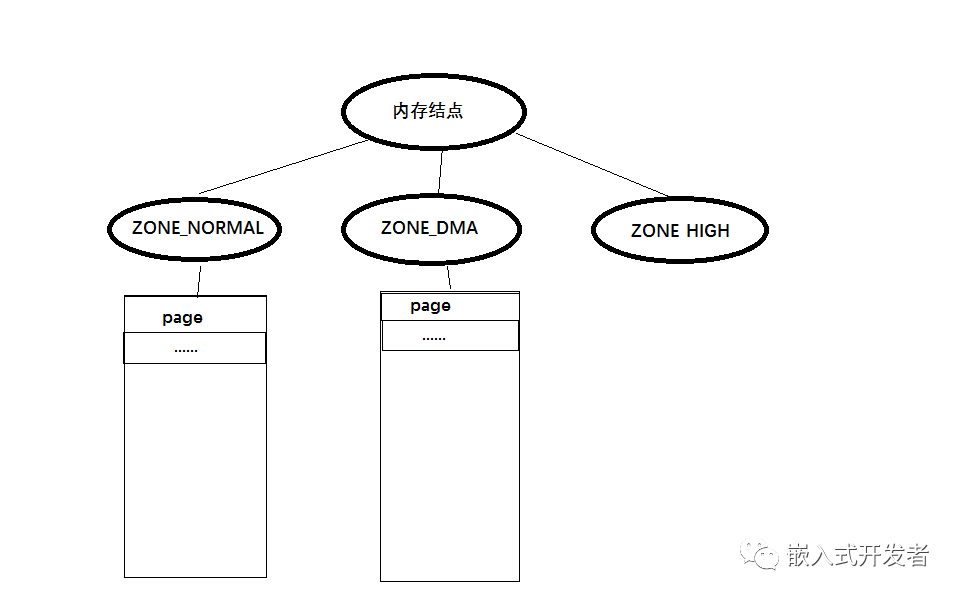
图 内核内存管理三级架构
内存节点node
内存节点node是计算机系统中对物理内存的一种描述方法,一个总线主设备访问位于同一个节点中的任意内存单元所花的代价相同,而访问任意两个不同节点中的内存单元所花的代价不同。在一致存储结构(Uniform Memory Architecture,简称UMA)计算机系统中只有一个节点,而在非一致性存储结构(NUMA)计算机系统中有多个节点。Linux内核中使用数据结构pg_data_t来表示内存节点node,我们把它叫做结点描述符。如常用的ARM架构为UMA架构。对于UMA架构只有一个内存节点,对于NUMA架构有多个内存节点。
在numa.h中有如下定义:
#ifdef CONFIG_NODES_SHIFT
#define NODES_SHIFT CONFIG_NODES_SHIFT
#else
#define NODES_SHIFT 0
#endif
#define MAX_NUMNODES (1 << NODES_SHIFT)
CONFIG_NODES_SHIFT是由用户配置的内存节点的数目。可以看到,对于UMA架构,MAX_NUMNODES等于1。
截取结点描述符pg_data_t结构体中几个重要的成员如下,很多成员的含义你现在可能不理解,有个印象就好,后面涉及时知道曾经见过。
结点的内存管理域
struct zone node_zones[MAX_NR_ZONES];
/*node_zones是一个数组,包含节点中各内存区(ZONE_DMA, ZONE_DMA32, ZONE_NORMAL...)的描述符。*/
struct zonelist node_zonelists[MAX_ZONELISTS];
/*页分配器使用的结构体数组,页分配器会根据不同的GFP申请标志来按照不同的顺序扫描对应节点中的ZONE,而该结构体就是用于制定不同的顺序。
对于UMA结构,MAX_ZONELISTS=1,
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
该结构包含了类型为 struct zoneref 的一个备用列表,由于该备用列表必须包括所有结点的所有内存域,因此由 MAX_NUMNODES * MAX_NZ_ZONES 项组成,外加一个用于标记列表结束的空指针。
*/
}
int nr_zones;
/*指示了节点中不同内存区的数目*/
结点的内存页面
#ifdef CONFIG_FLAT_NODE_MEM_MAP/* means !SPARSEMEM */
struct page *node_mem_map; /*结点中页描述符的数组,包含了此结点中所有页框描述符*/
#ifdef CONFIG_PAGE_EXTENSION/*扩展页,不分析*/
struct page_ext *node_page_ext;
#endif
#endif
int node_start_pfn;
/*节点第一页帧逻辑编号*/
int node_present_pages;
/*节点中页帧的数目*/
int node_spanned_pages;
/*节点以页帧为单位计算的数目。由于空洞的存在可能不等于node_present_pages,应该是大于等于node_present_pages。*/
int node_id;
/*结点id*/
交换守护进程
wait_queue_head_t kswapd_wait; /* kswapd页换出守护进程使用的等待队列 */
/* 指针指向kswapd内核线程的进程描述符 */
struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */
int kswapd_order;;/*需要释放的区域的长度,以页阶为单位*/
enum zone_type kswapd_classzone_idx;
每个结点都有一个内核进程kswapd,它的作用就是将进程或内核持有的,但是不常用的页交换到磁盘上,以腾出更多可用内存。不信你可以ps看一下。
页回收
/*页回收相关的两个成员,后面会专门讲页回收机制*/
/* Write-intensive fields used by page reclaim */
spinlock_t lru_lock;
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
/*结点标记*/
unsigned long flags;
ZONE_PADDING(_pad2_)
在UMA结构的机器中, 只有一个node结点即contig_page_data, 此时NODE_DATA直接指向了全局的contig_page_data, 而与node的编号nid无关,其中全局唯一的内存node结点contig_page_data定义在mmzone.h。
#ifndef CONFIG_NEED_MULTIPLE_NODES
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
#else /* CONFIG_NEED_MULTIPLE_NODES */
#include <asm/mmzone.h>
#endif /* !CONFIG_NEED_MULTIPLE_NODES */
在定义了多节点时,也就是定义了宏CONFIG_NEED_MULTIPLE_NODES,会引用头文件asm/mmzone.h。
实际上我去查了arm下没有asm/mmzone.h这个文件,也就意味着目前为止,arm并没有实现对NUMA的支持。所以,从现在开始,我们也只分析UMA架构。
内存管理区域zone
NUMA结构下, 每个处理器CPU与一个本地内存直接相连, 而不同处理器之前则通过总线进行进一步的连接, 因此相对于任何一个CPU访问本地内存的速度比访问远程内存的速度要快, 而Linux为了兼容NUMA结构, 把物理内存相依照CPU的不同node分成簇, 一个CPU-node对应一个本地内存pgdata_t。
这样已经很好的表示物理内存了, 在一个理想的计算机系统中, 一个页框就是一个内存的分配单元, 可用于任何事情:存放内核数据, 用户数据和缓冲磁盘数据等等。任何种类的数据页都可以存放在任页框中, 没有任何限制。
但是Linux内核又把各个物理内存节点分成n个不同的管理区域zone, 这是为什么呢?
因为实际的计算机体系结构有硬件的诸多限制, 这限制了页框可以使用的方式. 尤其是, Linux内核必须处理两种硬件约束。
ISA总线的直接内存存储DMA处理器有一个严格的限制:他们只能对RAM的前16MB进行寻址。
在具有大容量RAM的现代32位计算机中, CPU不能直接访问所有的物理地址, 因为线性地址空间太小, 内核不可能直接映射所有物理内存到线性地址空间。
对于每个node中的内存,Linux分成了若干内存管理区域,定义在mmzone.h的枚举类型zone_type中,
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* ArchitectureLimit
* ---------------------------
* parisc, ia64, sparc<4G
* s390<2G
* armVarious
* alphaUnlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
管理内存域 | 描述 |
ZONE_DMA | DMA设备通常直接操作内存区域,但有些设备不能遍寻整个内存空间,比如地址线不足,所以就引入ZONE_DMA这块内存区域来解决这一问题, |
ZONE_DMA32 | 不解释 |
ZONE_NORMA | 表示内核能够直接线性映射的一般内存区域。 |
ZONE_HIGHMEM | 标记了超出内核虚拟地址空间的物理内存段, 因此这段地址不能被内核直接映射,它的存在是为了解决前面提及的内存映射不够的问题。 |
ZONE_MOVABLE | 内核定义了一个伪内存域ZONE_MOVABLE, 在防止物理内存碎片的机制memory migration中需要使用该内存域,供防止物理内存碎片的极致使用。 |
ZONE_DEVICE | 不解释 |
可以看到上面有些区的定义是这样的:
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
这表明这些区是可以配置的,并不一定会存在。如在64位系统中, 并不需要高端内存, 因为64位linux支持的最大物理内存为64TB, 对于虚拟地址空间的划分,将0x0000,0000,0000,0000 – 0x0000,7fff,ffff,f000这128T地址用于用户空间;而0xffff,8000,0000,0000以上的128T为系统空间地址, 这远大于当前我们系统中的内存空间, 因此所有的物理地址都可以直接映射到虚拟地址, 不需要高端内存的特殊映射。
一个管理区域用结构体struct zone来描述,struct zone在linux/mmzone.h中定义。截取部分定义如下:
unsigned long _watermark [NR_WMARK];
每个zone在系统启动时会计算出 3 个水位值, 分别为 WMAKR_MIN, WMARK_LOW, WMARK_HIGH 水位, 这在页面分配器和 kswapd 页面回收中会用到。
enum zone_watermarks
{
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])
当系统中可用内存很少的时候,系统进程kswapd被唤醒, 开始回收释放page, 水印这些参数(WMARK_MIN, WMARK_LOW, WMARK_HIGH)影响着这个代码的行为。
每个zone有三个水平标准:watermark[WMARK_MIN], watermark[WMARK_LOW], watermark[WMARK_HIGH],帮助确定zone中内存分配使用的压力状态:
标准 | 描述 |
watermark[WMARK_MIN] | 当空闲页面的数量达到page_min所标定的数量的时候, 说明页面数非常紧张, 分配页面的动作和kswapd线程同步运行.WMARK_MIN所表示的page的数量值,是在内存初始化的过程中调用free_area_init_core中计算的。这个数值是根据zone中的page的数量除以一个>1的系数来确定的。通常是这样初始化的ZoneSizeInPages/12 |
watermark[WMARK_LOW] | 当空闲页面的数量达到WMARK_LOW所标定的数量的时候,说明页面刚开始紧张, 则kswapd线程将被唤醒,并开始释放回收页面 |
watermark[WMARK_HIGH] | 当空闲页面的数量达到page_high所标定的数量的时候, 说明内存页面数充足, 不需要回收, kswapd线程将重新休眠,通常这个数值是page_min的3倍 |
如果空闲页多于pages_high = watermark[WMARK_HIGH], 则说明内存页面充足, 内存域的状态是理想的。
如果空闲页的数目低于pages_low = watermark[WMARK_LOW], 则说明内存页面开始紧张, 内核开始将页患处到硬盘。
如果空闲页的数目低于pages_min = watermark[WMARK_MIN], 则内存页面非常紧张, 页回收工作的压力就比较大。
long lowmem_reserve[MAX_NR_ZONES];
/*zone 中预留的内存, 为了防止一些代码必须运行在低地址区域,所以事先保留一些低地址区域的内存。*/
/*NUMA体系下需要知道该zone属于哪个结点,因为有多个节点*/
#ifdef CONFIG_NUMA
int node;
#endif
/*这个zone所属内存节点所对应的构体*/
struct pglist_data* zone_pgdat;
/* cpu缓存页,关于这个成员后面重点细讲*/
struct per_cpu_pageset __percpu *pageset;
unsigned long zone_start_pfn; /*区域的起始帧号*/
unsigned long managed_pages; /*present_pages中被buddy system管理的业数*/
unsigned long spanned_pages; /* 总页数,包含空洞 */
unsigned long present_pages; /* 可用页数,不包含空洞 */
const char* name;/*名字*/
int initialized;/*是否初始化*/
ZONE_PADDING(_pad1_)
/* free areas of different sizes和伙伴系统相关,在后面讲解 */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
内存 zone 结构体中的 flag 字段描述了内存域的当前状态。暂不解释。
enum zone_flags {
ZONE_BOOSTED_WATERMARK,/* zone recently boosted watermarks.
* Cleared when kswapd is woken.
*/
};
/* Primarily protects free_area */
spinlock_tlock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
boolcontiguous;
ZONE_PADDING(_pad3_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached该变量结合上面的struct per_cpu_pageset讲解。
*/
unsigned long percpu_drift_mark;
该结构比较特殊的地方是它由ZONE_PADDING分隔的几个部分。这是因为zone结构的访问非常频繁,在多处理器系统中, 通常会有不同的CPU试图同时访问结构成员。因此使用锁可以防止他们彼此干扰, 避免错误和不一致的问题。由于内核对该结构的访问非常频繁, 因此会经常性地获取该结构的自旋锁zone->lock。ZONE_PADDING是做一些无用的填充,以使分隔的几部分分布在不同的 Cahe Line 中,提高效率。其实在介绍前面的内存节点时也有用到该宏,可以翻回去看下。
物理页框page
每一个物理页都和一个struct page结构体关联。因为内核会为每一个物理页帧创建一个struct page的结构体,因此要保证page结构体足够的小,否则仅struct page就要占用大量的内存。 出于节省内存的考虑,struct page中使用了大量的联合体union,在不同的用途下取不同的成员。现在来介绍这些成员并没有太大意义。后面用到时我会介绍,等待本系列完结我们可以回过头来总结。
下面仅对page的flags字段做说明。
页面标志flags
flags:描述page的状态和其他信息,如图:

图 page flag格式
section:主要用于稀疏内存模型SPARSEMEM,在没有使用稀疏内存模型时该字段不存在,所谓的稀疏内存模型参见前面文章。 node:NUMA节点号,标识该page属于哪一个节点。 zone:内存域标志,标识该page属于哪一个zone。 flag:page的状态标识,定义于linux/page.h,常用的见下面。
从上面的图可以看到,flags包含4个字段,每个字段的长度都是根据实际配置动态决定的,甚至还不一定存在,比如section和node。比如系统有多少个结点啊,就决定要分配多少位用于表示节点id,比如4个节点,那么两位就足以表示了。
详细的flags布局如下:
/*
* page->flags layout:
*
* There are five possibilities for how page->flags get laid out. The first
* pair is for the normal case without sparsemem. The second pair is for
* sparsemem when there is plenty of space for node and section information.
* The last is when there is insufficient space in page->flags and a separate
* lookup is necessary.
*
* No sparsemem or sparsemem vmemmap:非稀疏模式
| NODE | ZONE | ... | FLAGS |
* " plus space for last_cpupid:
| NODE | ZONE | LAST_CPUPID ... | FLAGS |
* classic sparse with space for node:稀疏模式
| SECTION | NODE | ZONE | ... | FLAGS |
* " plus space for last_cpupid:
| SECTION | NODE | ZONE | LAST_CPUPID ... | FLAGS |
* classic sparse no space for node:
| SECTION | ZONE | ... | FLAGS |
*/
Flags的flag字段可以是以下标志:
PG_locked:page被锁定,说明有使用者正在操作该page。
PG_error:指示涉及该page的IO操作发生了错误。
PG_referenced:控制页面活跃程度,在kswapd页面回收中使用,表示page刚刚被访问过。
PG_active:page处于inactive LRU链表。PG_active和PG_referenced一起控制该page的活跃程度,这在内存回收时将会非常有用。
PG_uptodate:表示page的数据已经与后备存储器是同步的,是最新的。在读操作之后置位,除非发生了IO错误。
PG_dirty:表示页面内容发生改变,页面为脏,页面内容被改写后还没有和外部存储器进行同步操作。
PG_lru:表示该page处于LRU链表上,内核使用LRU链表管理活跃和不活跃页面。
PG_slab:该page属于slab分配器。
PG_reserved:设置该标志,防止该page被交换到swap。
PG_private:如果page中的private成员非空,则需要设置该标志。
PG_writeback:回写开始前置位,写完清除。
PG_swapcache:表示该page处于swap cache中。
PG_mappedtodisk:表示page中的数据在后备存储器中有对应。
PG_reclaim:表示该page要被回收。当PFRA决定要回收某个page后,需要设置该标志。
PG_swapbacked:该page的后备存储器是swap。
PG_unevictable:该page被锁住,不能交换,并会出现在LRU_UNEVICTABLE链表中。
PG_mlocked:该page在vma中被锁定,一般是通过系统调用mlock()锁定了一段内存。
关于page的这些标志位,后面用到还会深入介绍。
Linux将所有的物理页结构体page存在一个数组中,起始地址存放在全局指针struct page *mem_map中,数组长度存放在全局变量unsigned long max_mapnr中,记住这一点,很关键。对于discontigmem内存模型,存放在节点的struct page*成员中。
