




通过上次专题数据库方面的操作,我们对kettle有了比较完整的认识,但数据很多时候不仅仅来源于数据库,也可能来源于文件。
我会用两次的专题,分别将各种数据文件的输入和输出的使用总结一下,以便能够轻松的将这些数据库之外的数据按照不同的数据格式和文件格式轻松的插入到数据库中,也可以将数据库或不同类型文件的数据按照指定数据格式和文件格式存储于文件中。本次主要说说作为文件的输入控件。
1、xls和xlsx文件
日常通过excel处理的数据集,这种文件格式最常见。我们要区分excel的2003版本和2007版本差异,并熟悉sheet的行列关系。
2、csv文件
逗号分割值文件,当然也可以使用其它字符进行字段分隔,其实就是一种不带格式的文本文件,表头就是字段名称,很多数据库都支持这种格式的导出。
3、txt文件
除了csv格式的文本文件外,还有很多特殊规则的文本文件,由于内部逻辑随意,因此处理起来要比csv文件复杂一些。
4、xml文件
可扩展标记语言,在webservice接口和简易信息聚合(RSS)中比较常见,很多配置文件也使用xml格式。
5、json文件
是一种轻量级的数据交换格式文件,在web应用开发中作为前后台的数据交换格式,由于解析快速,压缩率高,现在非常流行。比如很多web地图渲染文件、字典数据都通过json方式存储,对于mongodb数据库,输出的就是这种数据格式。
6、yaml文件
是一个可读性高,用来表达数据序列化的文件格式,如docker的k8s和ansible之类的编排工具使用yaml文件进行配置。现在很多应用程序也开始使用这种文件进行程序运行环境配置。
kettle不仅支持以上这些文件作为输入,还支持其它方式的输入,比如ldap、http请求等,但对于任何方式的数据作为输入,必须以数据格式处理为技术点,通过深入学习这些格式的处理方法,就能够在多种格式中随意搭配,完成复杂的业务逻辑。
1、xls和xlsx文件
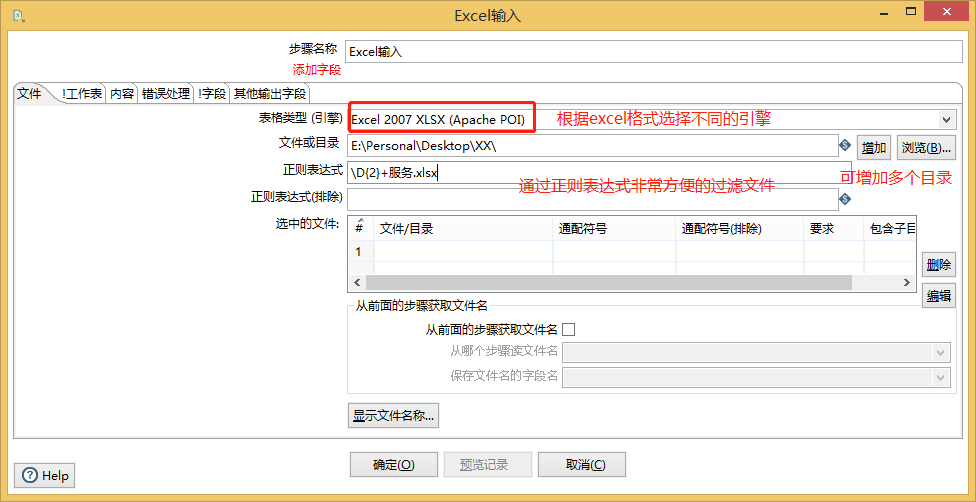
配置工作表名称
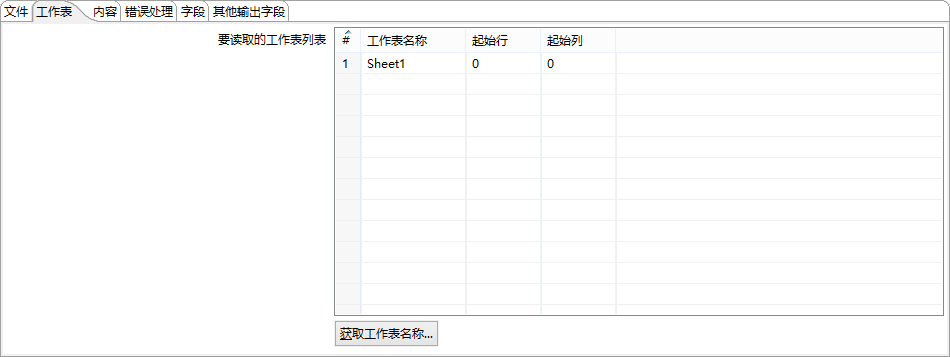
配置字段
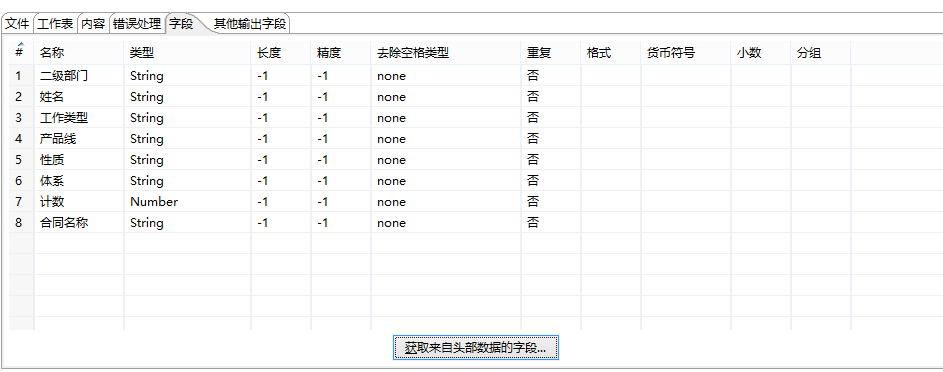
还可以将文件的其它属性信息提取出来作为数据字段进行后期处理,比如文件的分拆合并都可以通过此处的逻辑实现。
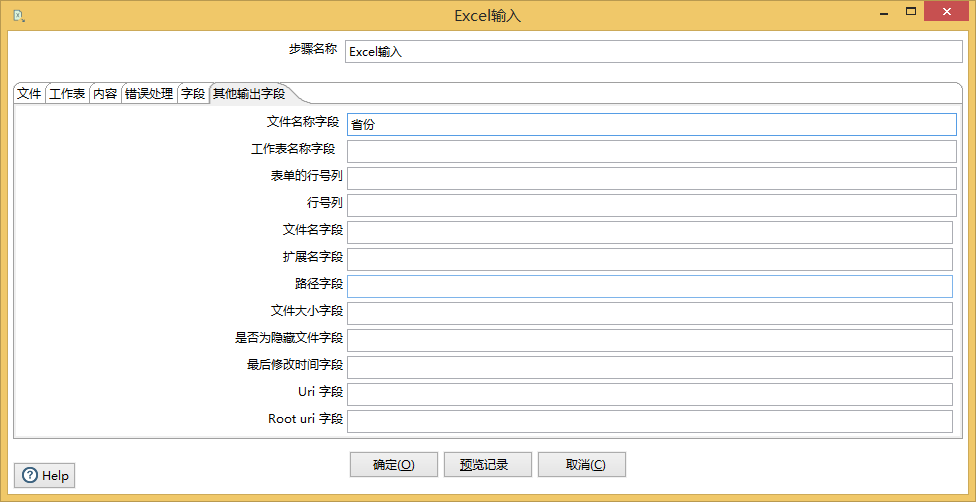
如下图,我们就可以通过一个简单的excel输入和一个excel输出进行多个文件数据合并到一个文件,或者增加一个Switch case控件,将一个文件按照某个字段进行分拆到多个文件。
2、csv文件
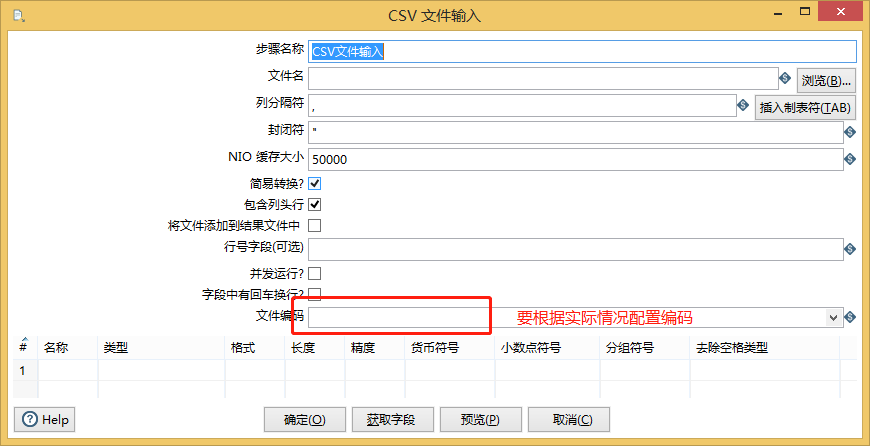
重点要说的就是编码,常见的编码有GBK和UTF-8,要根据实际情况调整,避免乱码。
3、txt文件
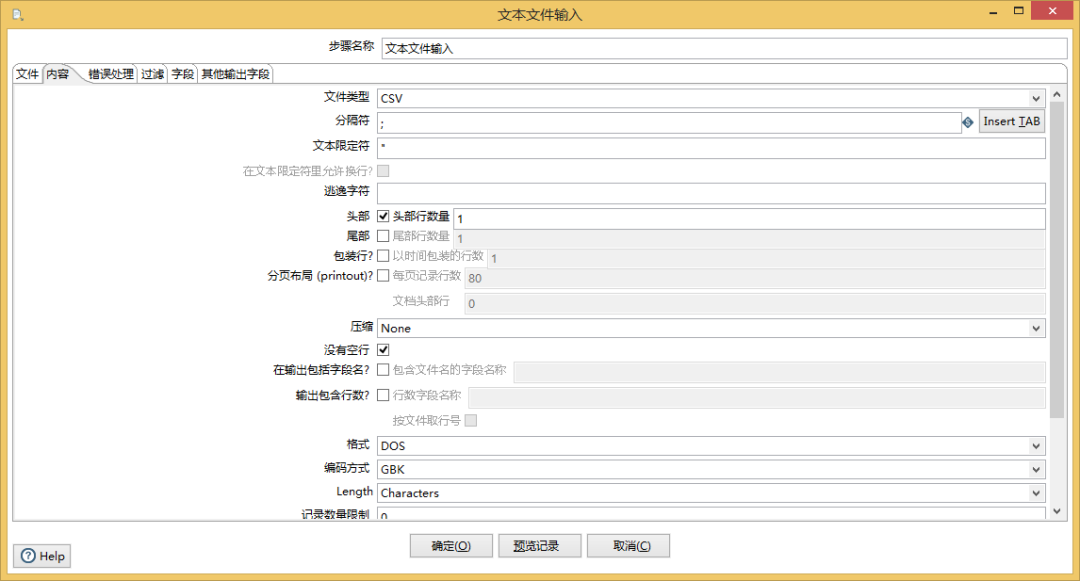
对于txt文件,大多数其实处理的都是不规则的csv文件,因此我们可以通过复杂的配置逻辑,将不规则的csv逻辑上转化为csv文件进行输入。
4、xml文件
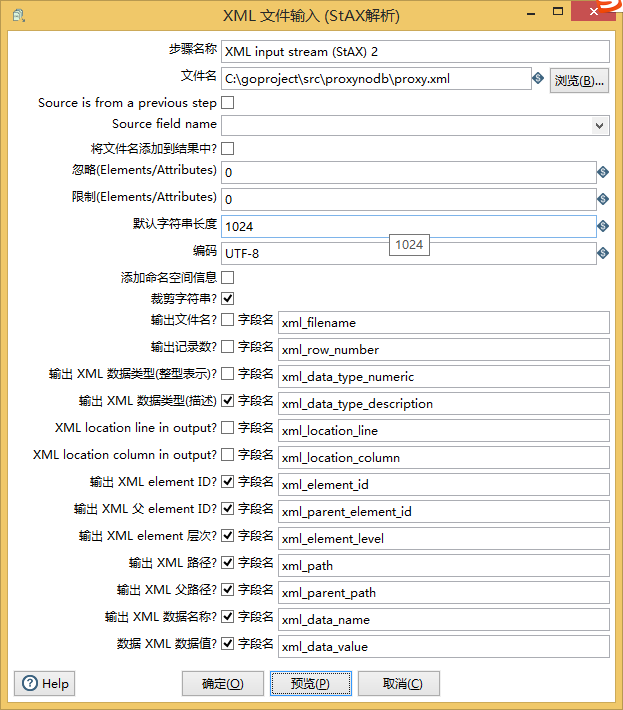
通常只需要配置文件名就可以获取xml的数据
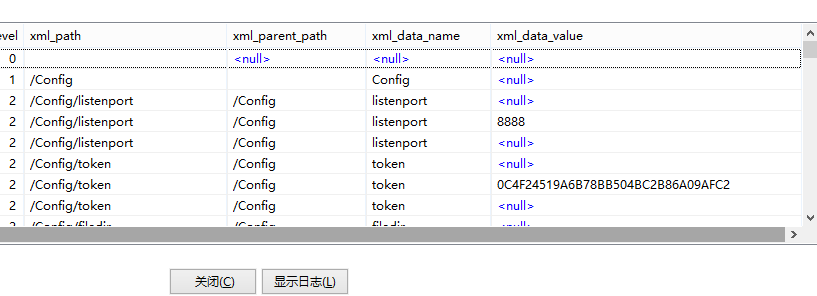
在此基础上可以通过xml_pah、xml_parent_path、xml_data_name、xml_data_value这几个字段的过滤处理,就可以将xml变成数据库通常规则的关系型数据。
5、json文件
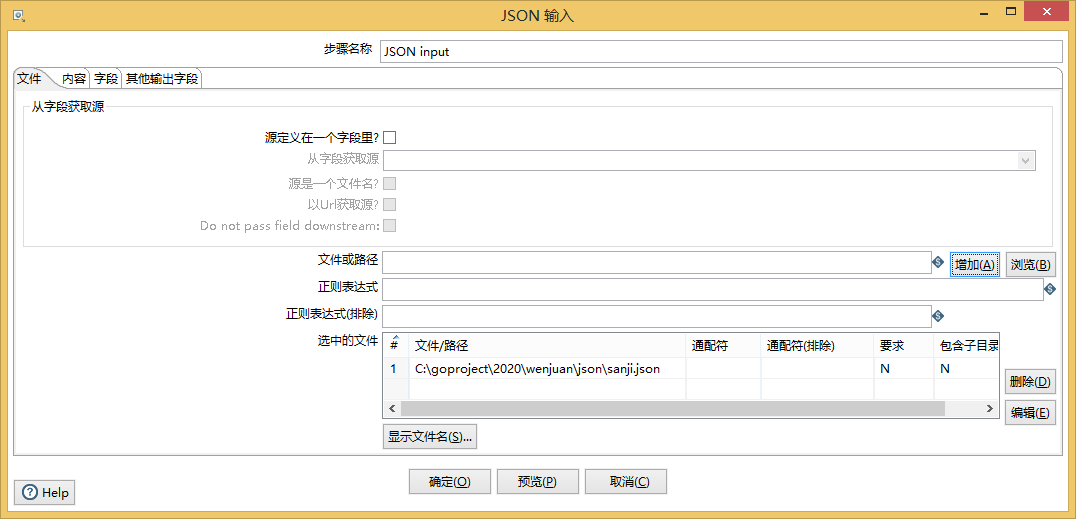
通过预览进行勾选字段
对于json的普通字段可以映射到数据库的字段上,对于列表可以通过行拆列等方式进行处理。
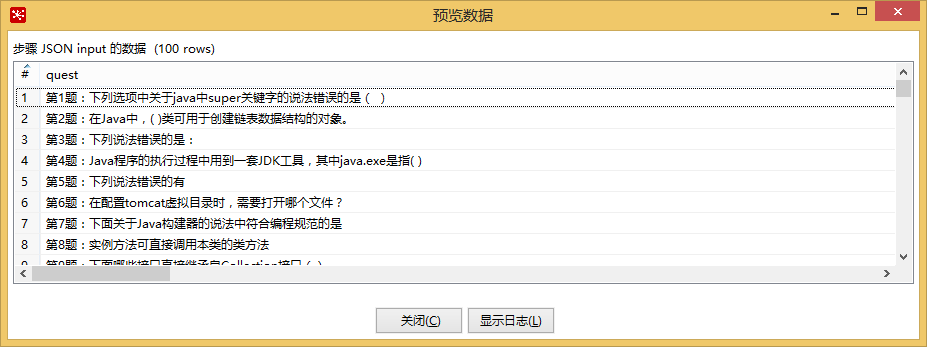
6、yaml文件
先看一个yaml文件内容
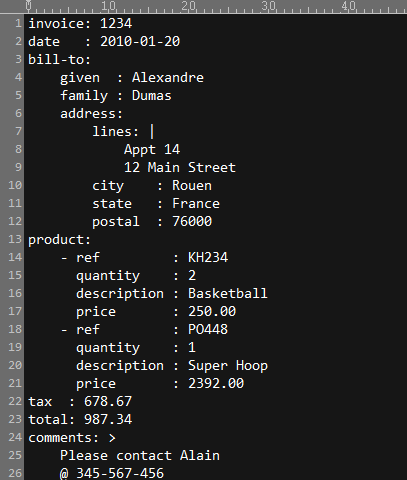
文件内容上看,yaml通过使用缩进表示层级关系,如果能够解析这种文件的配置信息,后期可以对配置信息进行处理,比如可以将配置文件中的一些参数更换为自己的参数后输出,完成自动化部署。
1、每个控件都有很多个性化配置,我们全部了解是不现实的,要根据实际工作需要,阶段性的熟悉自己需要使用的控件,并掌握细节配置逻辑,这能很好的避免逻辑上的错误导致最终配置的任务失败。
2、你提供的文件格式的可能kettle没有提供相应的处理控件,但我们可以通过kettle的其它转换控件、或者通过外部程序将数据转换为通用格式的数据,然后再进行后续转换的设计。
3、前期可以通过较小数据量的操作来熟悉控件,但一旦处理正式数据,首先要思考的是效率问题,对于机器cpu、内存、IO消耗严重的处理流,要通过拆分等方式将每个单个任务的消耗量降下来,这样可以拿时间换空间。
其它文档阅读


