





1、前言
1https://rda.ucar.edu/
1http://rda.ucar.edu/data/ds083.2
时间分辨率:逐6小时
2、批量下载数据
1import requests
2import datetime
3
4# 定义登录函数
5def builtSession():
6 email = "xxxxxxx" #此处改为注册邮箱
7 passwd = "xxxxxxxx" #此处为登陆密码
8 loginurl = "https://rda.ucar.edu/cgi-bin/login"
9 params = {"email":email, "password":passwd, "action":"login"}
10 sess = requests.session()
11 sess.post(loginurl,data=params)
12 return sess
13
14# 定义下载函数
15def download(sess, dt):
16 g1 = datetime.datetime(1999,7,30,18)
17 g2 = datetime.datetime(2007,12,6,12)
18 if dt >= g2:
19 suffix = "grib2"
20 elif dt >= g1 and dt <g2:
21 suffix = "grib1"
22 else:
23 raise StandardError("DateTime excess limit")
24 url = "http://rda.ucar.edu/data/ds083.2"
25 folder = "{}/{}/{}.{:0>2d}".format(suffix, dt.year, dt.year, dt.month)
26 filename = "fnl_{}.{}".format(dt.strftime('%Y%m%d_%H_00'), suffix)
27 fullurl = "/".join([url, folder, filename])
28 r = sess.get(fullurl)
29 with open(filename, "wb") as fw:
30 fw.write(r.content)
31 print(filename + " downloaded")
32
33# 批量下载
34if __name__ == '__main__':
35 print("downloading...")
36 s = builtSession()
37 for i in range(2): #共下载多少个时次
38 startdt = datetime.datetime(2018, 5, 16, 0) #开始时次
39 interval = datetime.timedelta(hours = i * 6)
40 dt =startdt + interval
41 download(s,dt)
42 print("download completed!")
1downloading...
2fnl_20180516_00_00.grib2 downloaded
3fnl_20180516_06_00.grib2 downloaded
4download completed!
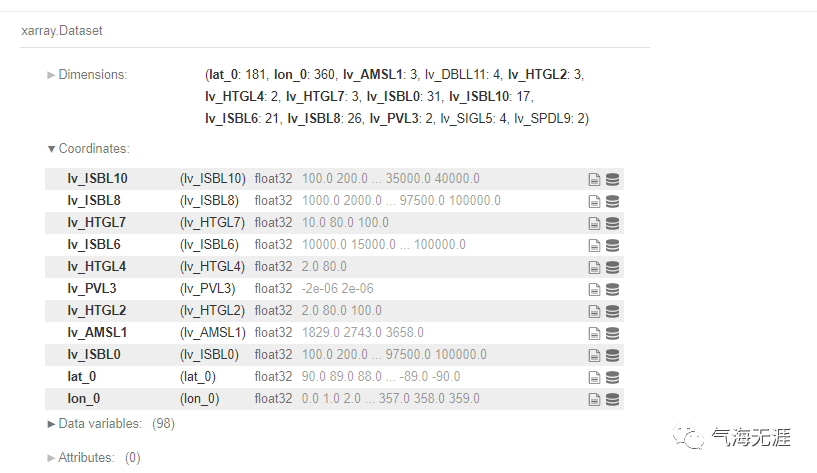
3、读取示例数据
1import xarray as xr
2ds = xr.open_dataset('./fnl_20180516_00_00.grib2',engine='pynio')
3ds
有问题可以到QQ群里进行讨论,我们在那边等大家。
QQ群号:854684131
文章转载自气海无涯,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
