




一、搭建环境
操作系统:centos7.2 ,准备两台主从服务器
二、准备安装软件
安装软件:jdk-8u181-linux-x64.gz、hadoop-2.7.5.tar.gz
三、开始安装
1、使用 SecureCRTP 登录centos7.2 系统,创建工作目录
mkdir ysn
2、使用WinSCP,登录centos7.2 系统,将jdk-8u181-linux-x64.gz、hadoop-2.7.5.tar.gz文件上传到ysn目录下
配置hostname
vi /etc/hostname
修改名称为
master
设置免密
ssh-keygen -t rsa
配置hosts
vi /etc/hosts
添加一行ip映射主master
你的ip地址 master
复制SSH密钥到目标主机,开启无密码SSH登录
su root
ssh-copy-id master

登录到master不用输入密码
ssh master
3、使用 SecureCRTP,进入bigdata目录,分别解压hadoop-2.7.5.tar.gz文件
cd /ysn
tar -zxvf hadoop-2.7.5.tar.gz
4、将解压目录,移动到对应的目录下
mv hadoop-2.7.5 /usr/local/hadoop
5、配置hadoop
cd /usr/local/hadoop
cd etc/hadoop
ls
修改core-site.xml文件
vi core-site.xml
configuration中添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml文件
vi hdfs-site.xml
configuration中添加如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
configuration中添加如下配置:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
在master服务器配置hadoop环境变量
vi /etc/profile
配置如下:
exprot HADOOP_HOME=/usr/local/hadoop
export PATH=.:$JAVA_HOME/bin:$ZK_HOME/bin:$KAFKA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置生效
source /etc/profile
配置hadoop的jdk
cd /usr/local
cd hadoop
cd etc/hadoop
vi hadoop-env.sh
配置jdk参考如下:
export JAVA_HOME=/usr/local/jdk
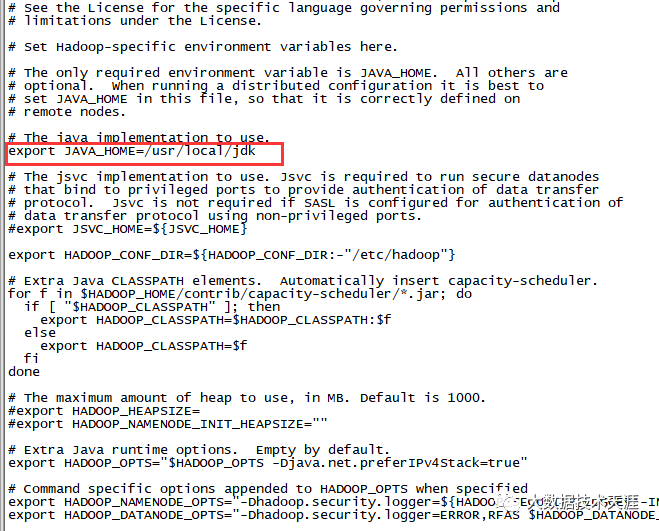
在master服务器主从配置
配置slaves
vi slaves
master
slave
配置hosts
vi /etc/hosts
添加一行ip映射从slave
你的ip地址 slave
ssh登录slave服务器配置hostname
vi /etc/hostname
修改名称为
slave
设置免密
ssh-keygen -t rsa
在master服务器执行拷贝到slave服务器
cd /usr/local
scp -r jdk slave:/usr/local/
scp -r hadoop slave:/usr/local/
scp -r /etc/profile slave:/etc/
scp -r /etc/hosts slave:/etc/
在slave服务器执行拷贝操作
ssh-copy-id slave
ssh-copy-id master
在master服务器执行拷贝操作
ssh-copy-id slave
验证查看是否拷贝成功
cd ~/.ssh
ls
可以查看到这几个文件
authorized_keys id_rsa id_rsa.pub known_hosts
more authorized_keys
在master服务器是否免密登录主从
登录主master,如果登录成功,再退出
ssh master exit
登录从slave,如果登录成功,再退出
ssh slave
exit
格式化hadoop
hadoop namenode -format
启动hadoop
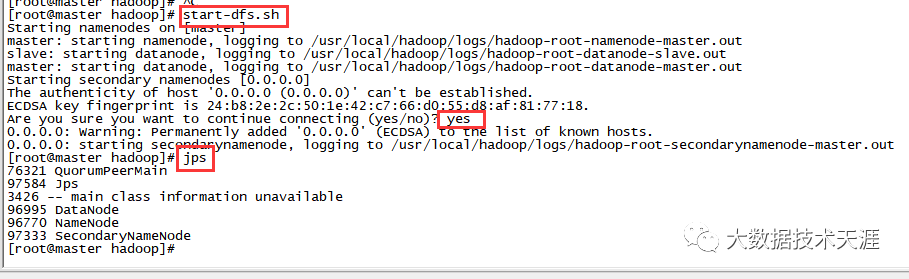
start-dfs.sh
在启动过程中输入yes,启动后输入jps 查看是否有hadoop进程,如下图:
在slave服务器查看是否有hadoop进程,如下图:

关闭防火墙
systemctl stop firewalld.service
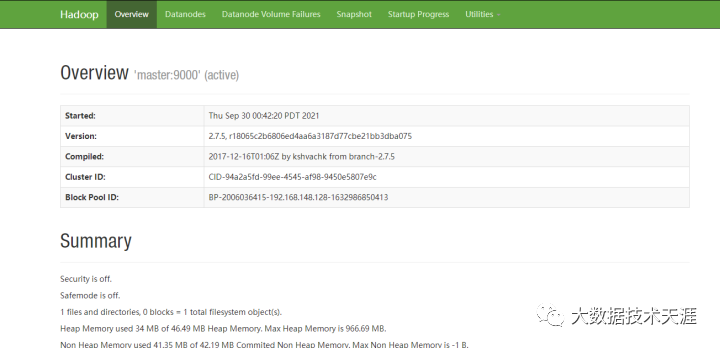
在浏览器访问hadoop,输入http://你的master的ip地址:50070,出现如下界面表示正常访问
启动yarn
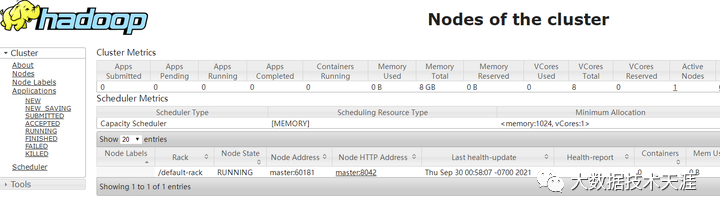
start-yarn.sh
在浏览器访问输入http://你的master的ip地址:8088,出现如下界面表示正常访问
如果觉得文章能帮到您,欢迎关注微信公众号:“大数据技术天涯” ,共同进步!
持续分享java技术,大数据技术、职场、程序员创业经历等原创文章。
