




引言
本文将从OLAP引擎的“不可能三角”出发,重点介绍数仓OLAP技术选型的4种思路,以供参考。
一、OLAP一些概念
在进入正题之前,这里先普及一些OLAP基本概念:
1
OLAP(On-Line Analytical Processing),在线分析处理,是数据仓库系统最主要的应用,专门用于支持复杂的分析操作,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理。
2
OLAP数据立方体,是一种用于支持OLAP上卷、下钻、切片、切块操作的多维数据模型。立方体的每个单元,存放一个聚合值。
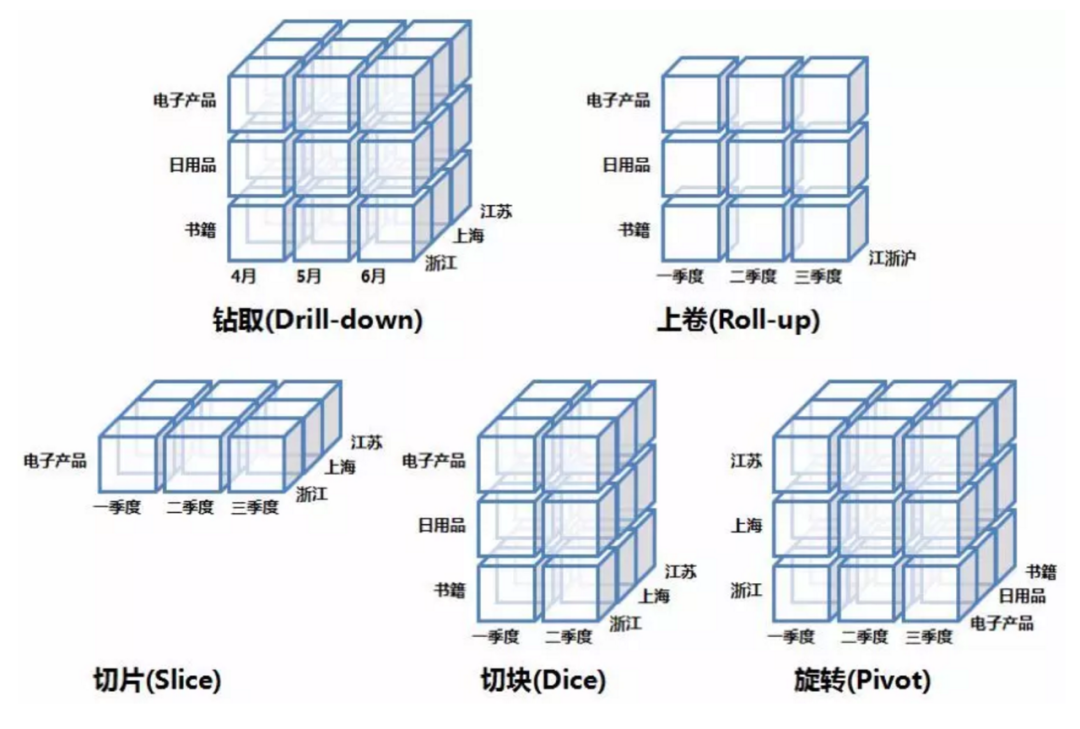
下钻(Drill-down):由粗粒度向细粒度拆分。如通过季度销售数据钻取每个月的销售数据。
上卷(Roll-up):下钻的逆操作。
切片(Slice):通过将其中一个维度选择单个值,从而创建具有较少维度的新多维数据集合。如只选电子产品销售数据。
切块(Dice):相比切片是选中多个维度。如第一季度到第二季度销售数据。
旋转(Pivot):维的位置互换,类似行列转换。
3
OLAP按数据存储格式可分类为:ROLAP、MOLAP、HOLAP
| 名称 | 描述 | 细节数据存储位置 | 聚合后的数据存储位置 |
|---|---|---|---|
| ROLAP(Relational OLAP) | 基于关系数据库的OLAP实现 | 关系型数据库 | 关系型数据库 |
| MOLAP(Multidimensional OLAP) | 基于多维数据组织的OLAP实现 | 多维数据库 | 数据立方体 |
| HOLAP(Hybrid OLAP) | 基于混合数据组织的OLAP实现 | 关系型数据库 | 数据立方体 |
ROLAP更灵活、MOLAP响应性能更好。
二、OLAP技术选型
不同的OLAP技术选型其实是从数据规模、灵活性、查询延时这三个方面的协调。
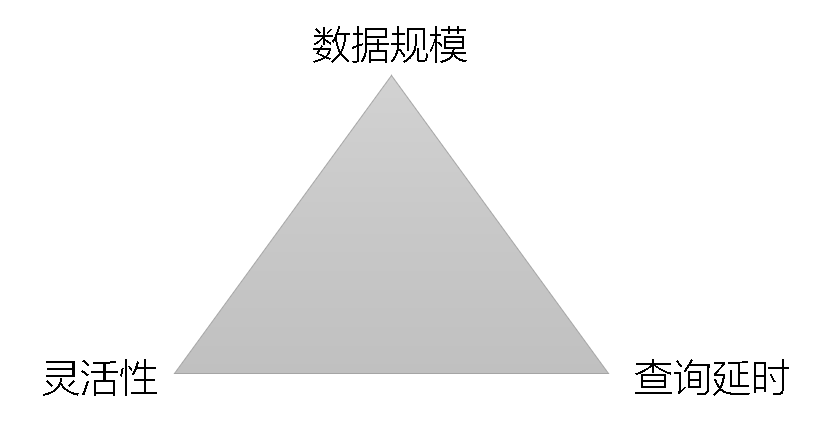
具体有以下几种思路:
1.离线批处理
场景:
用于复杂的ETL、数据挖掘等延时要求不高的场景。处理的数据规模大、灵活性高,但查询延时差。
代表:
Hive
Spark
2.MPP大规模并行处理(Massively Parallel Processor )架构
原理:
MPP架构是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
场景:
有很好的数据规模和灵活性支持,但是对响应时间是没有保证的。当数据量(达PB以上)和计算复杂度增加后,响应时间会变慢,从秒级到分钟级,甚至小时级都有可能。
代表:
Greenplum
Presto
Impala
ClickHouse
3.预计算架构
在入库时对数据进行预聚合,通过keyvalue存储结果集。进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。侧重数据规模、查询延时,灵活性差。
代表:
Druid
Kylin
4.搜索引擎架构
基本思路是在入库时创建索引,基于各自的存储模型进行优化,查询时做并行计算。侧重数据规模和灵活性,查询延迟较差,特别是涉及join操作
代表:
Elasticsearch
优点:无schema,扩展十分灵活,且支持全文检索等。缺点:join支持不友好,查询性能较差;HLL++去重非精确等。
技术选型考虑因素
在实际应用中,可结合需求,从以下几点因素考虑OLAP技术选型:
数据规模:数据量级有多大?
实时性:是否要求实时写入实时可见?
查询延时:查询响应延时要求多少?是否需要高并发?
查询类型:即席查询?固化查询?
写入吞吐:需要支持的写入吞吐是多少?
精确度:是否要求100%精确?
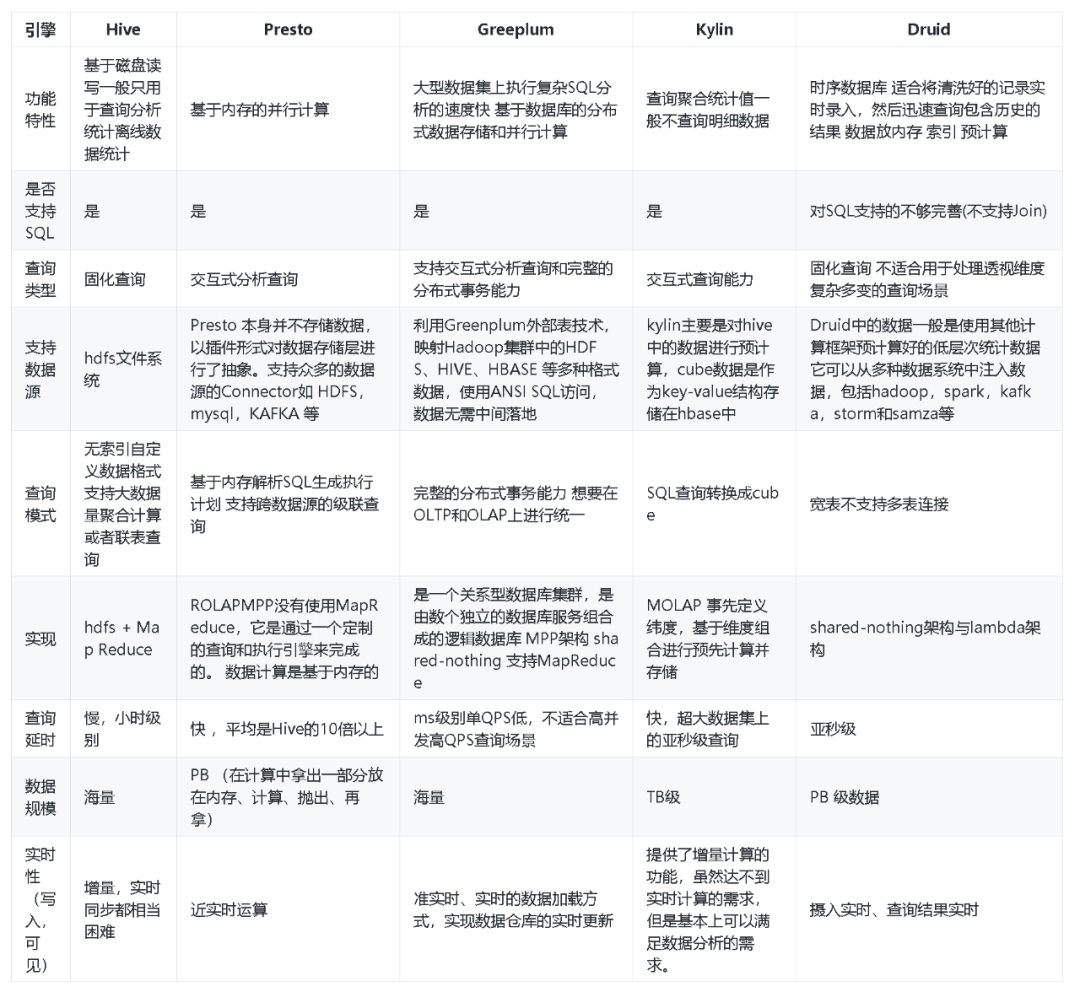
附几种OLAP引擎对比
后续文章,还会详细介绍热门开源OLAP引擎的实现原理和典型应用,欢迎持续关注。
更多大数据领域干货笔记,关注公众号:关二爷大数据笔记(bigdata_guanerye)。

公众号:关二爷大数据笔记
