




背景
我们 观远数据[1] 作为一家新锐的 BI 软件公司,在 2016 年就提出了“从 BI 到 AI”的发展方向。从决策智能全流程角度来说,传统的 BI 软件更多专注于历史数据的统计分析,AI 算法可以加入更多对未来商业状况的预测能力,并结合模拟仿真实现真正的数据驱动智能决策;从软件能力的角度来说,AI 也可以为传统的 BI 分析方式提效,增加非常多的“增强化”分析元素。而从 BI 为 AI 赋能的角度来说,绝大多数商业类问题的分析都必须从良好的数据管理基础出发,且对于数据质量,特征有效性,模型误差分析,业务指标追踪等各个流程环节,都可以借助 BI 分析工具大大提升算法落地的效率。这其实就是一种非常 Data Centric 的 AI 建设思路。
我们之前的思考主要专注于结构化类数据的 BI+AI 应用,而到了 2020 年,吴恩达老师也提出了 From Model-centric to Data-centric AI[2] 的想法,其中大量的应用案例都指向了非结构化数据方面的任务,包括 CV,NLP 等领域。在大佬的影响力之下,学术界对于这方面的重视度也与日俱增,NeurIPS 2021 开设了专门的 Data-Centric AI Workshop[3],很多关于 MLSys 方面的研究工作都把更多重心放在了数据而不是模型部分。上周斯坦福联合苏黎世联邦理工举办了一个为期 2 天的 Data Centric AI Workshop[4],这篇文章主要记录了一下观看这个 workshop 过程中的一些笔记,与大家分享探讨。
Day 1 - Stanford
Intro
首先由 James Zou 做开场的介绍,来整体介绍一下 Data Centric AI 的概念和框架。
James 先从一个识别皮肤疾病的实例开始,提出了模型准确率在学术论文与实际应用中出现的巨大偏差问题。然后引出了他们的一个工作,来自于 Stanford 的 Data Shapley[5],粗看了下简介跟用于模型解释的 shap 有着类似的思想,不过把评估目标从特征换成了具体的 training sample,即判断每一条数据 sample 对于模型最终效果的贡献度的大小。这跟可解释机器学习里的 influential instance 希望达到的效果也有些类似,但直接用 naive approach 来做从计算开销来说显然不太现实,作者应该是做了不少这方面的优化工作。
在上述实例的基础上,James 提出了实际 AI 应用从 Model Centric 到 Data Centric 转变的需求,并提出了 Data Centric AI 的一个框架:

传统的“数据处理,模型训练,模型评估,模型部署”的算法建模流程中主要在数据处理和模型评估阶段可能会涉及到一些数据相关的处理,其它的重心都放在了模型上,比如各种参数调优,模型结构调整等,前些年的论文也都集中在这个方向上。而 Data Centric 流程中,各个环节都更加关注数据的处理调整:
数据设计阶段:关注业务问题所需要的数据类型,来源,以及达到业务目标所需要的数据量是多少。以我们做商业类数据建模问题来说,我们需要多少时间段的历史数据来训练?如果业务变化迅速,可能稍久远一些的数据反而会对最终的模型结果带来反作用。 数据雕刻阶段:对于数据质量和价值的评估,数据打标,以及数据清洗等。大家常说的算法工程师会花 80%来做数据处理,其中就有很大一部分会花在数据清洗上。我们也在这方面做了很多自动化的探测和处理组件,帮助我们积累数据清洗的经验,以产品化的方式提升处理效率。 模型训练阶段:这方面的内容应该大家相对比较熟悉,比如数据增强,困难样本挖掘,active learning,curriculum learning 等。对于我们商业应用来说,传统的数据增强手段很难用上,需要更多从特征工程角度来考虑如何提高模型对数据的利用率,提升整体泛化能力。 模型监控阶段:误差分析,模型监控等相关内容。在 Data Centric 思想下,算法模型的迭代开发应该更多的从误差分析的结果出发,去指导前面几个步骤的数据处理,而不是各种调整模型参数结构看运气(这部分其实应该可以由 AutoML 来覆盖)。
除了提出这个流程框架,他们还搞了个 dcbench 任务集[6],上去看了下目前还处于开发早期,提供了 3 个任务[7],分别是:
在全量训练数据中选出尽可能少的数据,达到预期的模型效果。 在模型预测结果中找出显著表现较差的数据分组。 在有限的预算内,选择一定量需要做数据清洗的训练数据,达到最好的模型效果。
这三个问题还是挺有实际代表性的,不过整体看目前的任务还比较偏向于非结构化数据(例如前两个问题中的数据都是图片)和分类问题,后续还需要进一步来完善覆盖的数据类型和问题类型。
最后 James 也提了一下近年来关于 Responsible AI,数据交易,数据法规相关的发展,也与 Data Centric AI 有很深的联系。个人感觉这块接下来会是一个非常热门的方向,很值得投入。
Making Data Central in ML Development
第二个演讲来自于大名鼎鼎的 Matei 大佬,介绍了很多他在 Stanford 这边做的研究工作,主要分成了两个部分,如何高效获取高质量的训练数据,以及如何通过数据搜索获取方面的技术来改进 end-to-end 的大黑盒模型模式。
第一部分包含了两个方向,分别关于训练数据的搜索和选择和数据质量的检测,总共介绍了三个具体工作:
Selection with Guarantees using Proxies[8],Matei 举了个例子,比如在自动驾驶场景中,我们希望能获取到所有包含黄色交通灯状态的图片。在这篇文章中,作者通过一些 proxy function(如简单模型,规则)对数据进行分组,然后通过设计的算法来以一定的置信度获取到所需要的数据,可以达到非常高的效率。这个想法听起来跟 Snorkel 的弱监督学习会有些相似。 Similarity Search for Efficient Active Learning and Search of Rare Concepts[9],看起来主要是对 active learning 的改进,将搜索范围限定到目标样本的最近邻范围中,可以大大提升其搜索效率。虽然想法比较简单,但相关的应用非常的有效。 Finding Label and Model Errors in Perception Data With Learned Observation Assertions[10],Matei 主要举了对 label 质量检查的例子。传统的检查一般是通过人工撰写相关业务规则,或者使用一些统计值来发现一些数据质量问题,这篇文章中则通过一些手段来自动学习这些 assertion。没有仔细看实现细节,但感觉上使用一个预测模型去做预测,然后针对那些高置信度的 label 就可以实现类似的效果?
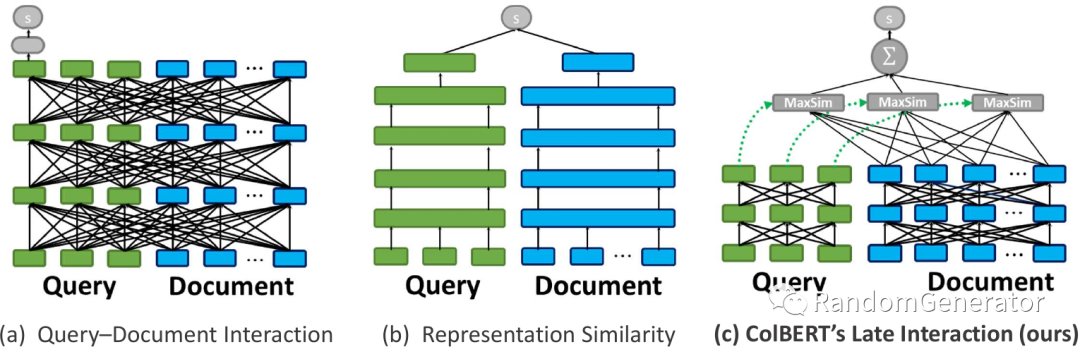
第二部分感觉挺有意思,主要介绍了 Building Scalable, Explainable, and Adaptive NLP Models with Retrieval[11] 这篇文章。作者们将数据搜索获取的思想融入到了整体模型架构中,一方面相对 end-to-end 大模型的推理来说效率提升了很多,另一方面对于模型的“决策过程”有了更多的透明度和可操作性。这个工作让我想起模型解释中通过样本来进行解释的一大类方法,包括我们在做误差分析时也经常会使用类似的方法来找到影响当前误判样本最类似的训练样本是哪些。

针对这个结构,他们设计了新的 ColBERT 模型[12] 结构,并在很多任务中达到了 SoTA 的效果。不过也给我们提出了几个值得思考的问题,在做模型设计时,我们是不是可以更多从“数据调优”的角度出发来进行设计,而不是传统的“参数调优”?另外对于 end-to-end 模型与多阶段模型如何取舍,是不是“合久必分,分久必合”?
Research Spotlights
接下来是 5 个 spotlight 演讲。简单记录一下:
Retiring Adult:提出了一个新的公开数据集,用来替代历史比较悠久,问题也比较多的 UCI Adult 数据集。 Datasets, dataflows and decisions:提出我们更应该在 dataflow/decisionflow 上验证各种算法,例如用截止 T 的数据来训练模型,在 T+1 做验证,而不是在一个静态的历史数据集上不停调优 overfit。 Building datasets for AI in dermatology:介绍了目前皮肤疾病相关数据集的一些问题,包括数据集没有被很好的共享,对于种族和肤色的覆盖度不够全,有些 label 并没有得到医学验证等,提出他们正在开发的一套新的领域数据集。 Finding Label and Model Errors in Perception Data With Learned Observation Assertions:Matei 前面已经介绍过这篇文章了,这里展开了一些细节和例子。 Beta Shapley: Noise-reduced Data Valuation Framework for Machine Learning:针对有噪声的数据,在低 cardinality 的情况下提升 Data Shapley 的估计精度,并介绍了其在 label 质量检测方面的应用。
顺带一提 QA 阶段的主持人是 Karan Goel,看过 Stanford MLSys Seminar[13] 的同学应该都不陌生吧 :)
The Voice-Enabled Internet
这个 talk 来自 Mozila 的 Katharina,主要介绍了他们的 Common Voice[14] 项目,通过众包的方式来收集各种语言的语音数据。上网站体验了一下,界面挺简洁漂亮,可以通过说话和聆听两种方式来做贡献,顺手就贡献了几条中文样本进去 :) 有点像语音界的 Captcha,很有意义的工作。从技术上来说,如何设计高效的目标单词/语句感觉需要不少领域专家的输入。另外如何推广,让更多的人参与进来也是个难点。
Healthcare Data Sharing
这个 talk 也关注于公开数据集的开发,也是意义非常重大的医学健康方向,其中大部分是放射类检查的医学图像收集。作者在 talk 中介绍了他们的整体的数据收集过程,以及其中的一些挑战,例如移除个人隐私信息,如何与多个组织进行协作等。此外他们还利用这些数据举办了一系列挑战赛,推进了领域的整体进步(如同当年 ImageNet 的巨大影响力)。从作者介绍的一系列模型结果来看,AI 辅助的医学诊断还是很有前景的。
Day 2 - ETH Part 1
Intro
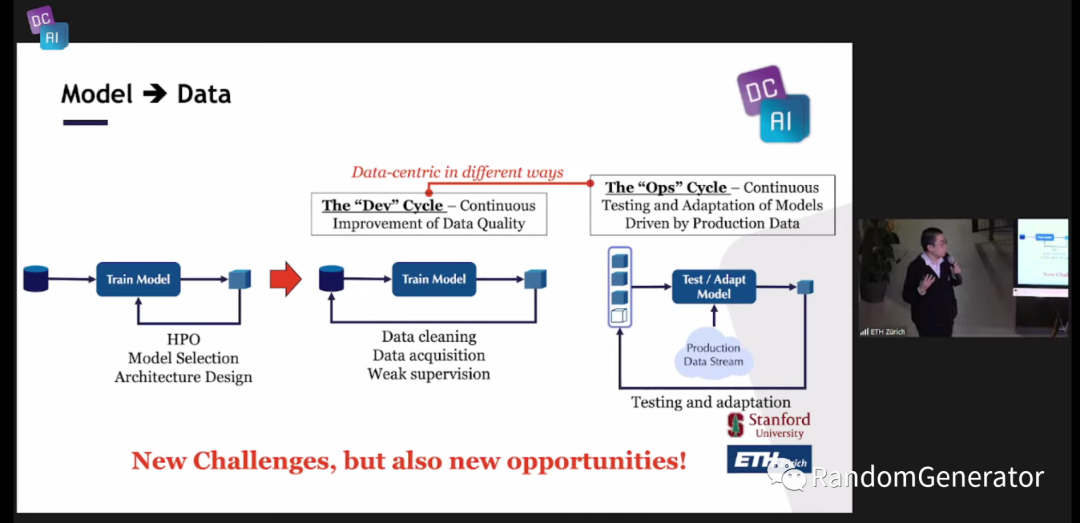
ETH 的 sessions 由 Ce Zhang 来主持,并做开场介绍。下面的这张流程转变与前一天的内容很类似,不过额外强调了一下除了 Dev cycle 外,我们还有很大一部分精力需要来处理 Ops cycle,即模型上线后的监控,自动重训练或决策的自适应等。
Bad Files, Bad Data, Bad Results
第一个演讲来自于 Hasso Plattner Institute 的 Felix。一开始介绍了一些关于数据科学家日常工作中各种任务的时间占比,我感觉老生常谈了,吴恩达老师也进一步阐述了我们大多数模型效果的提升都来自于数据方面的调整优化,也正是如此我们才愿意花费大量的时间在数据处理方面的工作上。
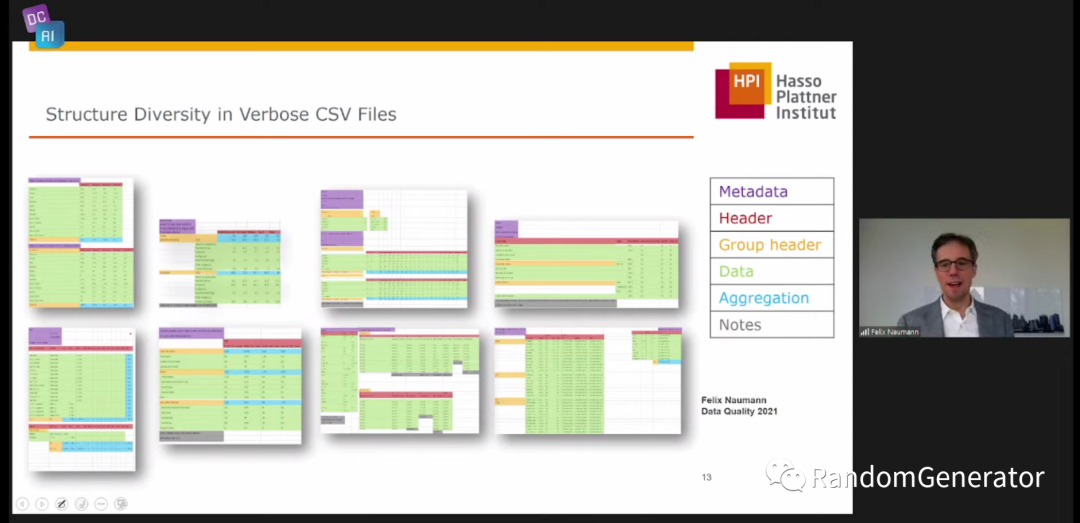
接着进入到 bad files 部分,主要涉及到数据对接方面的各种问题。数据对接不仅仅是连接一个数据库,上传一个 excel 这么简单,这位老哥举的各种例子都还挺生动,感觉到他们还是挺贴近业界的嘛。尤其到他打出了这页清洗 csv 文件的 ppt,,这绝对是个内行啊!
没想到他们还针对这类问题做了研究,发了论文,不禁令我流下了感动的泪水……
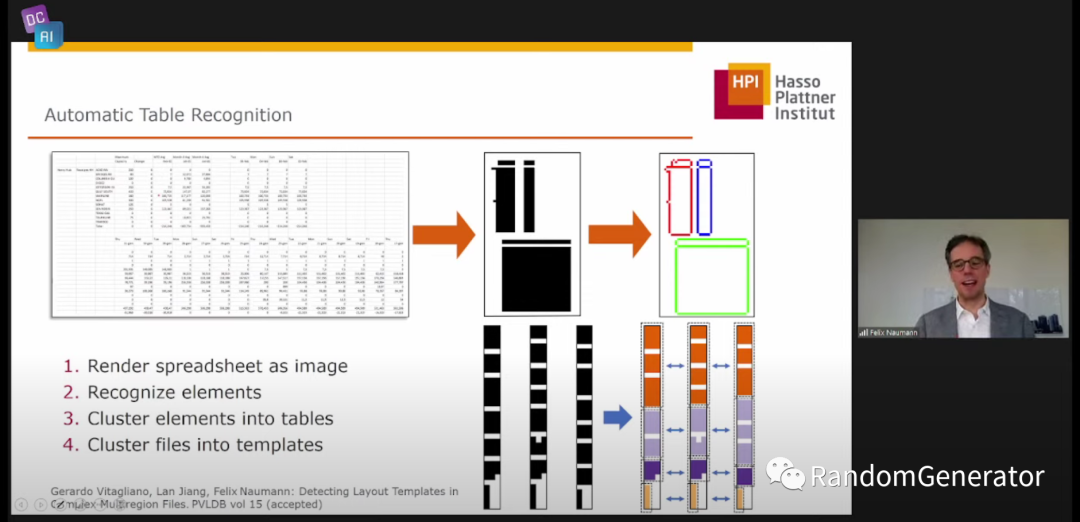
此外他们还做了各种真实世界数据问题的归类及相关系统处理能力的测试,称为 Pollock 项目[15]。感觉这个方法也可以后续应用于检测数据对接系统的健壮性。
讲完了 bad files 的问题,进入 bad data 章节。这部分主要介绍了一些数据的质量问题,也是我们在数据清洗阶段需要引起重视的。不过这部分并没有提多少具体的解决方案和技术手段。

同样最后一个章节 bad results 部分,Felix 也是主要把数据质量的框架延展到整个 AI 的生命周期中,引出各种可以探索的问题和方向:
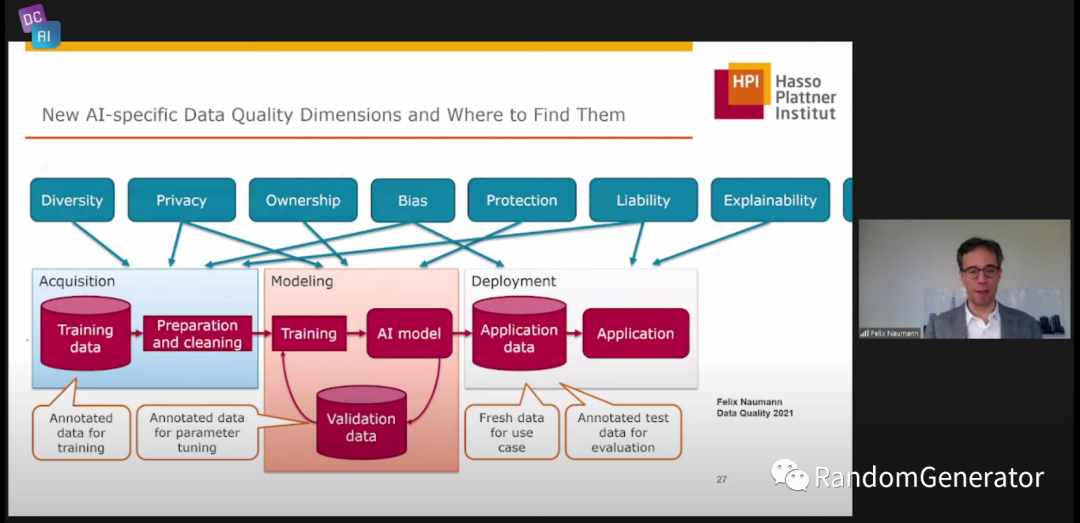
在 QA 环节有个问题挺好的,数据清洗这类问题可以说是很难从根本上完全解决的,总是会有新的数据问题出来,提问者想知道是否有这方面研究的“圣杯”?Felix 回答说他认为可能的“圣杯”是我们能够在某个模型精度的要求下,获取到应该去修复/提升整个 pipeline 中哪个部分的数据质量,并修复到什么程度的信息,这样我们就可以做整体投入的 trade-off。我感觉说的挺在理的,在 Model Centric 时代我们研究了很多 bias variance trade-off,对各种模型参数带来的优化和问题都做了研究,很多“老中医”对什么情况下调什么模型参数都很有经验,这方面的能力在 Data Centric 方向上还十分欠缺。
Understanding Data Quality in the Area of Data-Centric AI
这个 talk 来自于 Ce 的两位 PhD 学生。一开始作者补充了一下 Intro session 中的两个 Data Centric cycle 的细节:
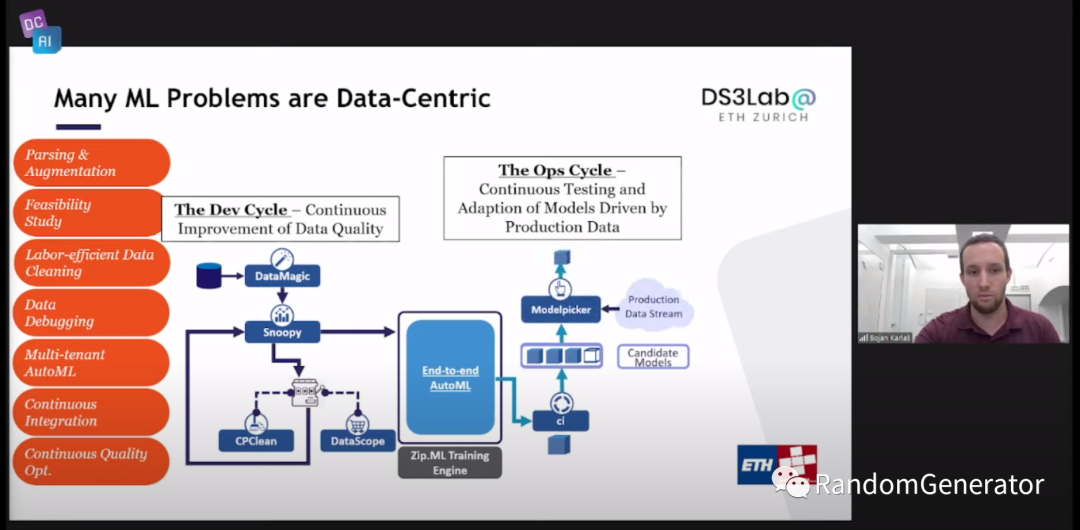
最近上吴恩达老师的 MLOps 专项课程[16] 里,在 model pipeline 部分也是直接讲 AutoML,而不再介绍各种模型的基础细节,感觉也是 Data Centric 带来的一个改变趋势。
接下来针对演讲主题,作者给出了一个总览,感觉隐约也承接了上个 talk 中提到的“圣杯”,即我们希望回答两个问题:我们的数据是不是足够好(让模型有足够的精度效果),以及如果不够好的话,如何修正:
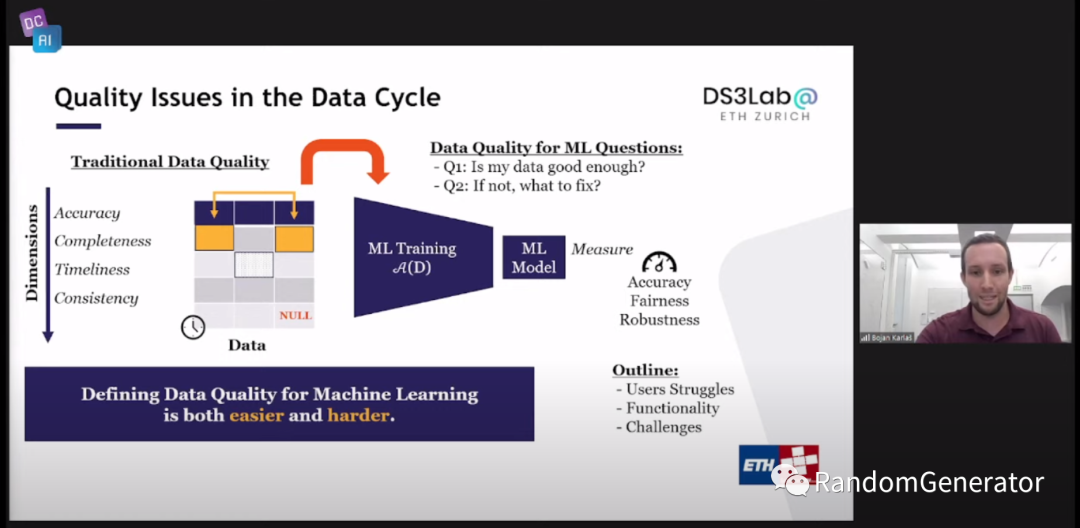
这个两个问题也很好的体现了 Data Centric AI 的思维方式与之前 Model Centric 的不同。
然后作者对训练数据的“可用性”,从 Bayes error rate 出发聊了聊他们的三篇文章:
Evaluating Bayes Error Estimators on Real-World Datasets with FeeBee[17] On Convergence of Nearest Neighbor Classifiers over Feature Transformations[18] Ease.ml/snoopy[19]
不过 BER 还是比较理想的设定,现实问题显然更加复杂,比如我们更关心的是数据集在模型上的表现,而不是数据分布下的 error rate;训练数据与测试数据的分布不一致问题;模型优化目标的多样化等等,还需要更多进一步的研究。
另一位作者继续介绍了他们对第二个问题的研究,即如果数据不够好,我们需要关注哪部分的问题。先讲了一下整体 data debugger 要解决的问题:
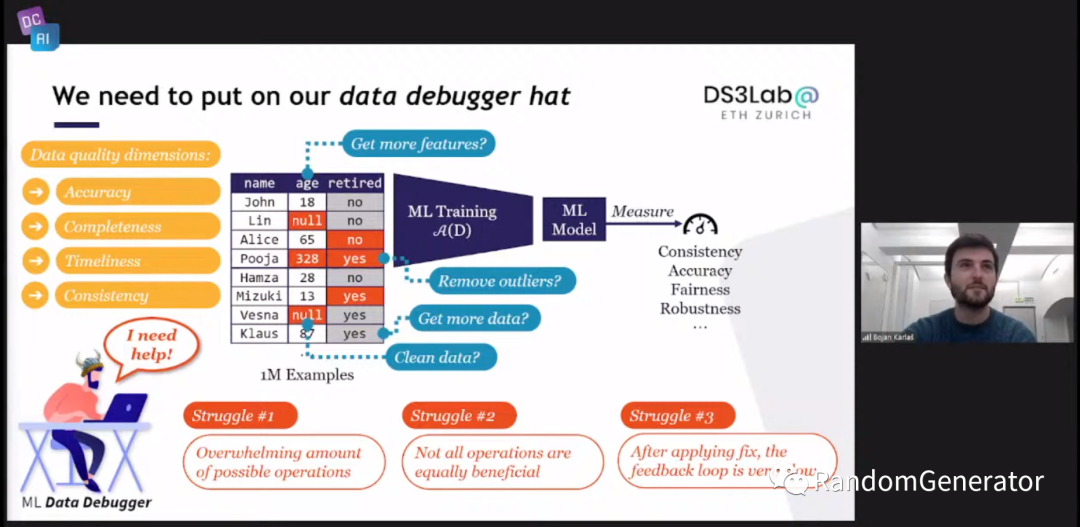
希望能够帮助用户在海量的数据,纷繁的数据问题中找到需要做的操作,并按照重要度对各种操作进行排序,最后能交互式的给出用户各种数据操作的反馈信息,跟软件 debugger 的感觉很类似。当然 data debugger 的挑战也更多,比如数据问题和清理操作的搜索空间极大,除了原始数据问题,还需要考虑用户构建特征的逻辑部分的影响,以及对于用户操作的反馈来说,往往重新运行模型 pipeline 是非常慢的,很难达到实时交互。
接下来是一些具体工作的介绍,例如对于选取缺失值数据来进行清洗的问题,有发表在 VLDB 的 Active Clean[20] 和 CP Clean[21] 两个工作:
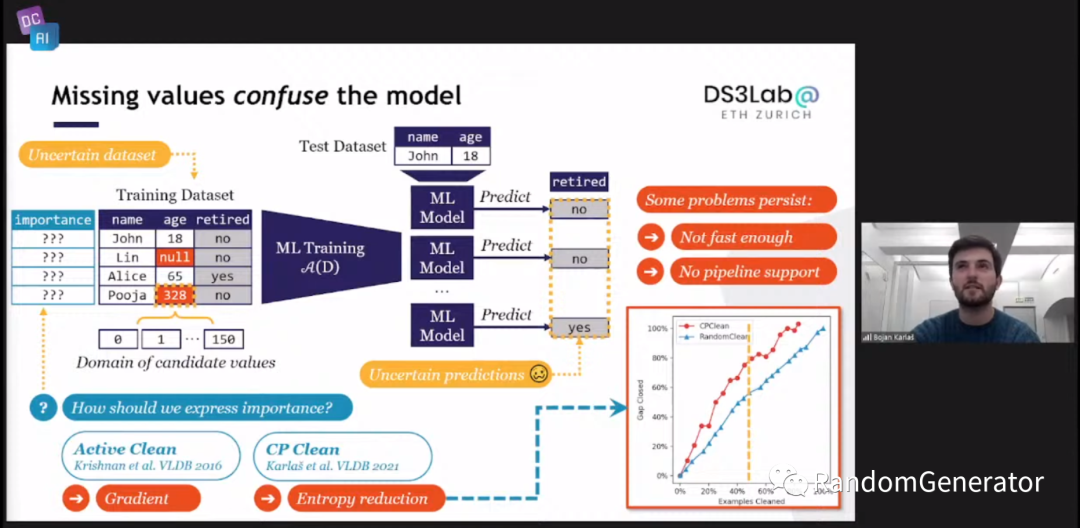
另外一块问题是对于“错误”的数据进行清洗的问题,其实跟第一天斯坦福介绍的 Data Shapley 要解决的是一类问题。这里介绍了基于 Influence Functions 方法和 Shapley 方法的几篇工作:
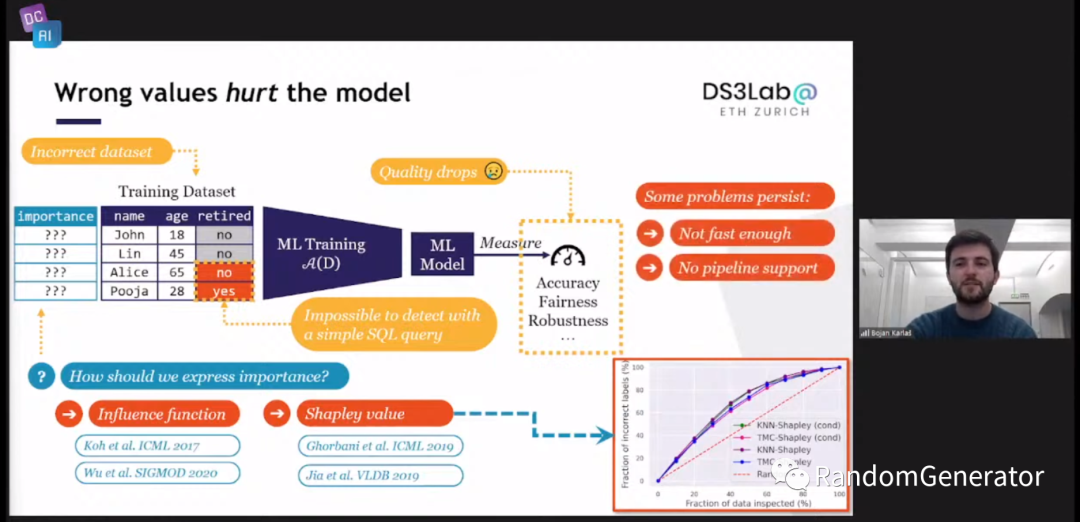
最后终于来到了他们提出的 Datascope[22] 方案,通过一系列的规则/模型近似,来获取数据实例的重要度分数,并且计算复杂度上要明显优于其它方法:
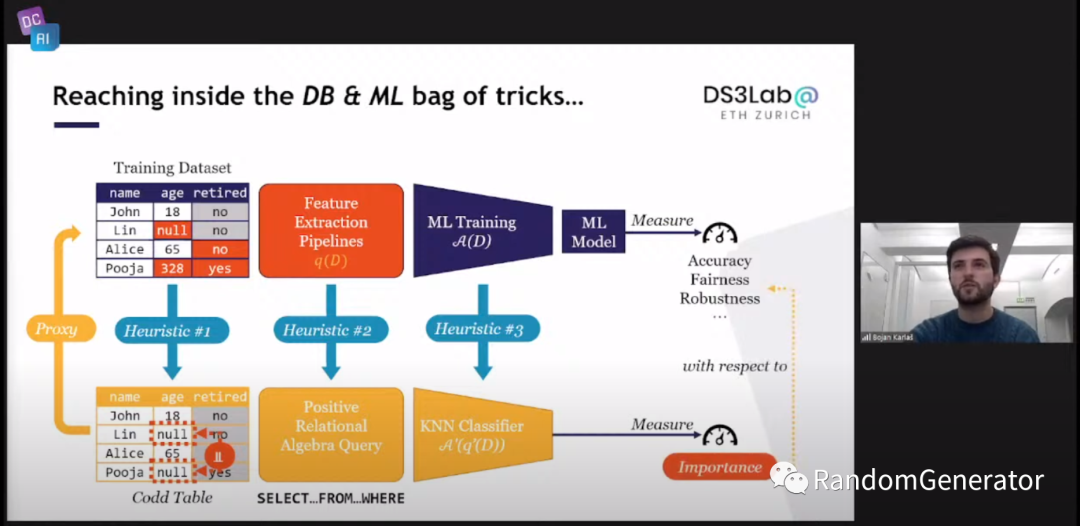
看了下作者展示的一些结果,感觉还不是很成熟,但是 ease.ml 里面的各个项目做了不少 Data Centric 方面的创新工作,后续可以系统性学习借鉴一下。
Data Independence in ML Pipelines and Data Science Workflows
这个 talk 来自于 Graz University of Technology 的 Matthias。Data Independence 的概念是数据存储和表示的形式的变化不应该暴露给上层应用。这个定义在数据库系统中比较常见,典型的比如大多数的数据库都统一对外暴露 SQL 接口,不论内部的存储计算引擎如何变化,应用层都不需要做任何修改。
在机器学习数据科学领域,数据存储和表示形式相对于 DBMS 来说更加的丰富多彩,所以作者认为这方面的挑战很大,也很有意义:

后面主要介绍了 Apache SystemDS[23] 项目和其中的一些技术实现。
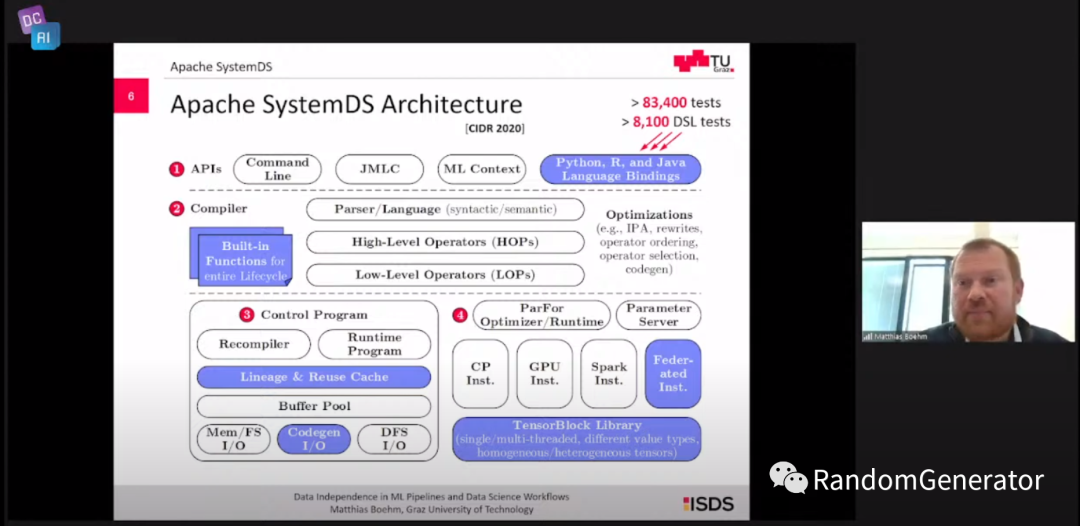
粗看感觉跟 TVM 项目有点像,不过 TVM 应该更针对深度学习模型的加速执行,而 SystemDS 则更多实现的是类似科学计算的一系列算子。在演讲中作者还提到了一些 SystemDS 有意思的特性,例如:
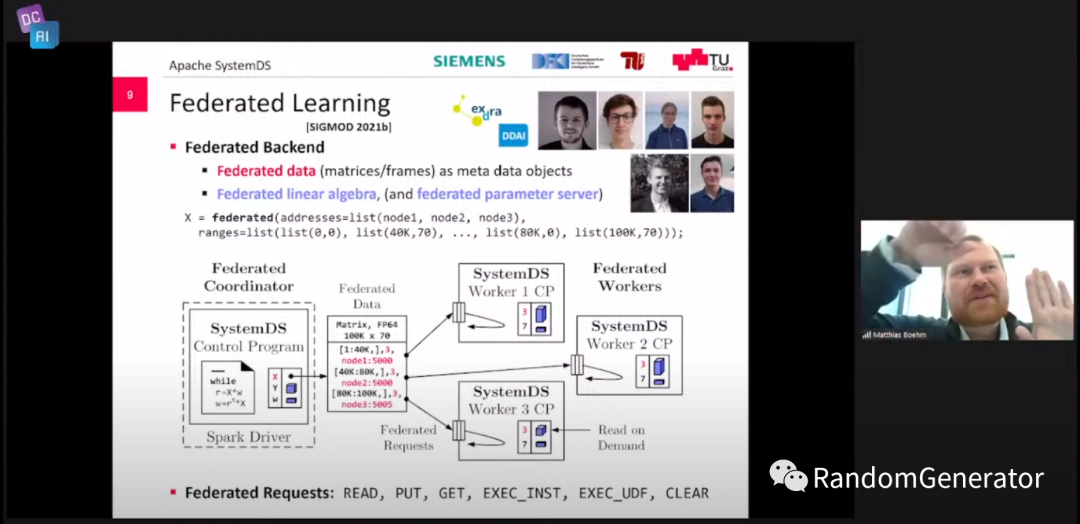
各种操作的血缘追踪,并做一些自动优化,例如中间结果重用等。 线性代数运算的压缩优化。 联邦计算的抽象和计算执行支持。 引入了 DAPHNE[24] 项目,支持分析 pipeline 的细粒度编译执行优化,并支持多种异构计算设备。
作者最后的几个思考里有一点个人比较有共鸣,对于 Data Centric 的问题,很多人都会觉得是无法完全用技术来自动化解决的,这其实是完全 OK 的。我们就是需要打造“增强化”的工具来辅助数据科学家或领域专家,来让他们更高效的完成工作,Data Centric 领域的很多产品设计是需要思考如何更好的结合 human-in-the-loop 的。
Disentangling the Roles of Curation, Data-Augmentation and the Prior in the Cold Posterior Effect
这个 talk 也是来自于 ETH 的两位 PhD 学生。演讲偏理论方向,这个主题我并不了解,看起来是想从 Data Curation 和 Data Augmentation 角度来解释 BNN 中的 CPE 现象。进一步可以从数据的预处理角度来推得模型训练时最优的 temperature 超参应该设定为多少。
RoFL: Attestable Robustness for Secure Federated Learning
这个 talk 来自于 ETH 的 Lukas。主要从两个方面来分析和加强联邦学习的健壮性:
Aggregation rule,攻击者可以通过控制某个联邦学习参与节点的行为来改变整体模型的效果。因此可以从各个参与者返回的 update 的聚合中做文章来抵御这类攻击。 Model capacity,大型模型会把不少的 capacity 花在对长尾样本的“记忆”中,因此攻击者也可以从长尾样本角度出发来改变模型的效果。作者提出了 suppressing long-tail learning 的方法来降低此类问题的影响。
感兴趣的同学可以参考他们的 RoFL 项目[25]。
Enterprise, meet Data Centric AI
来自 Nutanix 的 Debo 做的演讲。内容感觉有些散,讲了不少企业中数据管理的挑战,以及 MLOps 的巨大前景,最后顺带提了一下 Data Centric 的思想也应该应用到强化学习中,可惜没有怎么展开讲。
Start-up Session
接下来是 4 个数据相关初创公司的简短 talk:
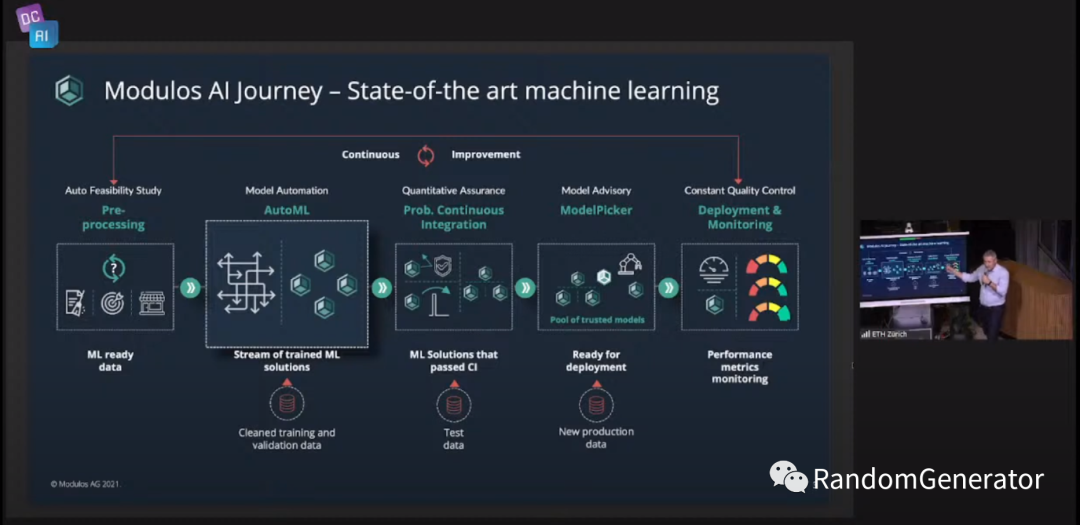
Lightly: 一家利用自监督学习和主动学习技术来帮助用户提高打标效率的公司,主要专注于 CV 领域(有点类似 scale.ai?但好像不做打标平台)。他们还开源了自己的自监督学习库 lightly[26]。 Syntheticus:利用 GAN 之类的生成式模型加上 差分隐私[27] 技术,来生成非常接近原始数据的“人工数据”,便于进行外部的分享与分析使用。看完感觉如果有效的话,tabular data 做增强也能实现了呀! LatticeFlow:他们打造了一个可以自动诊断模型问题,提供修复建议,并做一些自动修复的 AI 平台。不过从他们提到的文章来看,这里指的模型问题主要是 adversarial attack 类型的,而不是前面 talk 中反复提到的数据质量相关问题。 Modulos:构建了一个 Data Centric 的 end-to-end AI 平台,其中 Auto Data Feasibility 这块感觉很有新意。
Day 2 - ETH Part 2
Data Provenance: The Foundation of AI Governance
Part 2 的 talk 都跟 data governance 有关,开场的这个来自 University of Amsterdam 的 Sebastian。首先介绍了各国出台的数据安全隐私等方面的法规:

过去几年国内对这方面的重视和规范程度也越来越高,很多技术人员也更加关注国家政策法规的影响了,这是一个好的趋势。接着作者介绍了几个具体的例子,例如关于用户有权选择“被遗忘”:
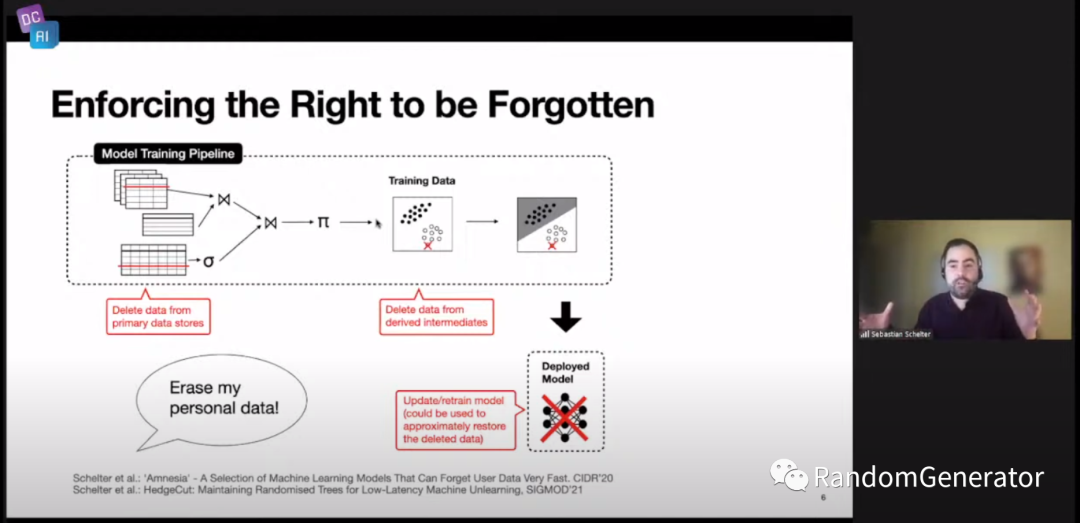
当用户希望跟自己相关的个人信息被删除时,AI 系统中需要对原始数据,模型训练数据以及训练后获得的相关 embedding 数据都进行删除,这对于传统的数据流模型流来说提出了新的需求与挑战。他们实验室开发了 mlinspect[28],能够自动从数据模型 pipeline 中提取 DAG 关系图,并记录细粒度的血缘关系,以便后续实现前面提到的单条用户数据删除时的级联更新。
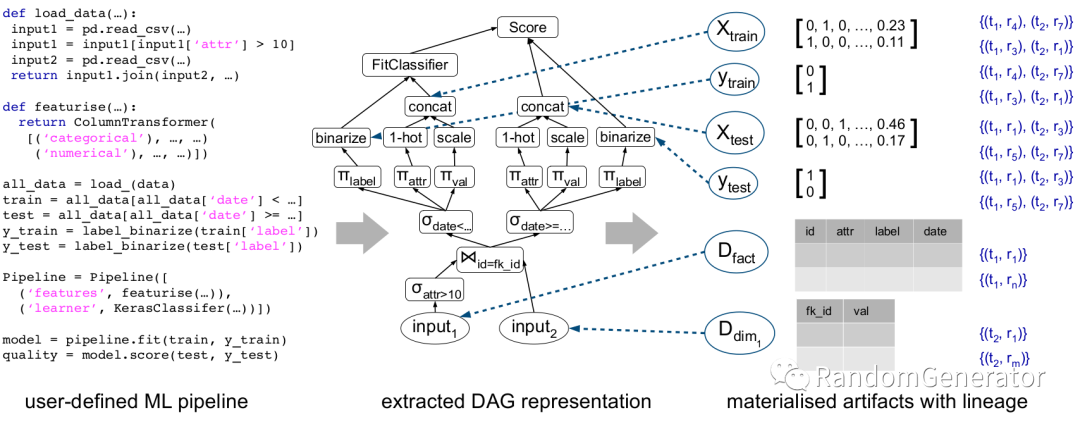
后续他们还计划在这个工具基础上结合 MLFlow 形成一整套的解决方案。
Creating Provably Fair AI Systems
这个 talk 来自于 ETH 的 PhD 学生 Mislav。主要从 Data Centric 角度出发来看待模型的公平性问题,总体的框架是通过表征学习来处理原始数据,保证学习到的 representation 后续应用于其它模型的训练都能保证公平性:
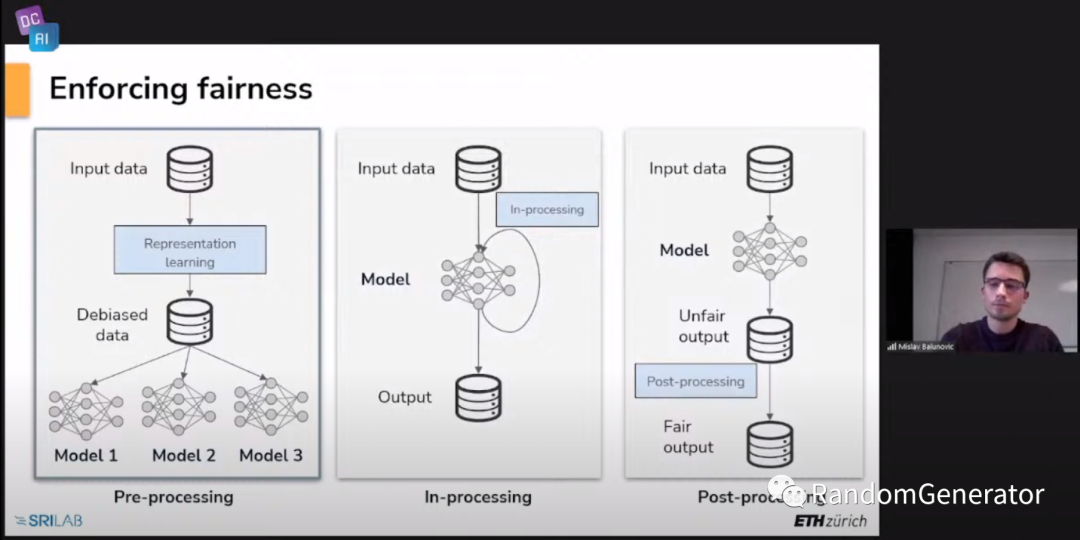
其中提到了几篇具体的工作:
Learning Certified Individually Fair Representations[29] LASSI[30] Fair Normalizing Flows[31]
Beyond Accuracy: Certified Deep Learning and Dealing with Infinite Data
这个 talk 来自 ETH 的 Martin。出发点是希望模型在优化精度的基础上,考虑其预测的“稳定性”。例如对图片做一些翻转,遮盖,亮度改变,像素变换的情况下,模型仍然能正确作出预测。这里的 infinite data 的意思是这样的变化操作是无限的,所以希望能够让模型能针对“符号表达”来学习,而不仅仅是具体的数据,于是就引出了训练 certified 模型的概念。具体可以参考他们的 diffai 项目[32]。
Pannel Session
邀请了业界各领域专业人士参与的关于 AI 与 Regulations 的讨论,其中有两个问题个人感觉比较有趣:
现有的联邦学习,隐私计算在技术上应该已经是可行的了,但为何没有在企业间大量应用起来? 我们如何把技术知识传递给所需要的非技术背景人群,例如法规的制定者,公共决策者,甚至更广泛的公民普及教育等。
Day 2 - Stanford
dcbench
斯坦福第二天的 session 由 Ce Zhang 教授先来开场,主要介绍 dcbench 这个项目。前面我先自己看了下项目的代码和文档,这里作者提出了他们的 motivation,希望成为 Data Centric 方向的 MLPerf 项目[33],并给出了对几个任务更直观的讲解,有兴趣的同学可以看下。
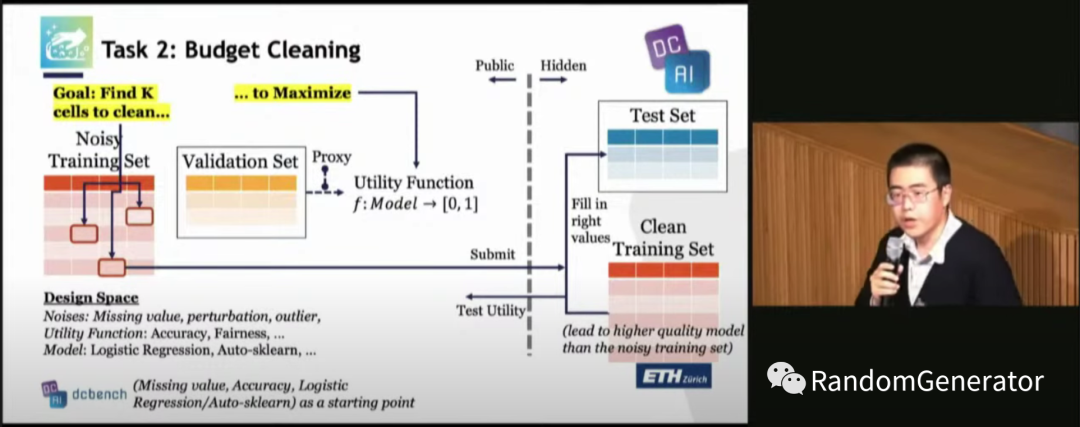
Research Spotlights
Metadata Shaping:主要想解决在 language model 中如何更好结合 domain knowledge 的问题,比如使用知识图谱或者将知识图谱与语言模型结合。作者提出的想法挺有意思,直接在训练数据中嵌入实体信息 (metadata) 而不改变模型,达到了非常好的效果,而且还很具有可解释性。 Data Budgeting for ML:研究数据集能够达到的最好效果是多少,以及最少需要多少样本达到最终效果的问题。作者在 OpenML 的数据集上做了一系列的实验,预测随着数据量增加的 performance curve,以及将样本量需求问题转化为一个多分类问题来尝试建模。使用简单模型已经能达到不错的效果。 Data Selection for Data-Centric AI:对 active learning 做了一些效率上的改进,分别是使用 proxy model 来做数据选择模型,以及在对样本做排序时先做一些 similarity search 的范围缩小,可以大大提升 active learning 的运行效率,且不影响最终精度效果。 Are We Learning Yet?:对过去发表的上百篇论文做了调研,总结其中对于模型验证方面所发生的各种问题,例如对比模型的实现不正确,baseline 没有调优,对 testset overfit,与真实世界的数据集不一致,与真实世界的 metric 不一致等。这方面的吐槽其实大家也见得挺多了…… Invisible Knowledge and the Internet:研究通过搜索引擎得到的结果中,我们看到的部分与整体数据分布的关系是怎么样的。
Interview with Feifei Li
这个 workshop 还邀请了李飞飞大佬过来,不过没有做主题演讲,而是一个简短的采访。James 跟 Feifei 聊了聊 ImageNet 的故事,在机器人领域构建“虚拟环境”的工作,dataflow 与静态数据集的问题,数据科学教育中 data centric 相关课程以及医疗健康领域的北极星目标等话题。Feifei 提到的我们在做研究工作时需要更深入的思考和明确我们的“北极星目标”,而不是跟着热度随波逐流,这一点个人非常受用。
What, who, how and why in AI
最后一个 talk 来自于 Caltech 的 Pietro,他也是李飞飞的导师。大佬的演讲也是比较 high level,提到了关于深度学习的 data efficiency 和泛化能力问题,专家知识与 AI 系统的沟通,以及相关性与因果性的问题。有一个比较有启发性的问题是,作者把数据看作是领域专家与模型进行沟通的“语言”,但是目前的沟通效率显然比较低,是否能像人类之间的沟通那样有更高效的形式?
参考资料
观远数据: https://www.guandata.com/
[2]From Model-centric to Data-centric AI: https://www.deeplearning.ai/wp-content/uploads/2021/06/MLOps-From-Model-centric-to-Data-centric-AI.pdf
[3]Data-Centric AI Workshop: https://datacentricai.org/
[4]Data Centric AI Workshop: https://www.datacentricai.cc/
[5]Data Shapley: https://arxiv.org/pdf/1904.02868.pdf
[6]dcbench 任务集: https://github.com/data-centric-ai/dcbench
[7]3 个任务: https://dcbench.readthedocs.io/en/latest/tasks.html
[8]Selection with Guarantees using Proxies: https://arxiv.org/pdf/2004.00827.pdf
[9]Similarity Search for Efficient Active Learning and Search of Rare Concepts: https://arxiv.org/pdf/2007.00077.pdf
[10]Finding Label and Model Errors in Perception Data With Learned Observation Assertions: https://ddkang.github.io/papers/2021/loa-vldb-workshop.pdf
[11]Building Scalable, Explainable, and Adaptive NLP Models with Retrieval: http://ai.stanford.edu/blog/retrieval-based-NLP/
[12]ColBERT 模型: https://arxiv.org/pdf/2004.12832.pdf
[13]Stanford MLSys Seminar: https://mlsys.stanford.edu/
[14]Common Voice: https://commonvoice.mozilla.org/zh-CN
[15]Pollock 项目: https://hpi.de/naumann/projects/data-preparation/pollock.html
[16]MLOps 专项课程: https://www.coursera.org/learn/machine-learning-modeling-pipelines-in-production
[17]Evaluating Bayes Error Estimators on Real-World Datasets with FeeBee: https://arxiv.org/abs/2108.13034
[18]On Convergence of Nearest Neighbor Classifiers over Feature Transformations: https://arxiv.org/abs/2010.07765
[19]Ease.ml/snoopy: https://arxiv.org/abs/2010.08410
[20]Active Clean: http://www.vldb.org/pvldb/vol9/p948-krishnan.pdf
[21]CP Clean: http://vldb.org/pvldb/vol14/p255-karlas.pdf
[22]Datascope: https://ds3lab.inf.ethz.ch/datascope.html
[23]Apache SystemDS: https://systemds.apache.org/
[24]DAPHNE: https://daphne-eu.github.io/
[25]RoFL 项目: https://github.com/pps-lab/rofl-project-code
[26]lightly: https://github.com/lightly-ai/lightly
[27]差分隐私: https://zhuanlan.zhihu.com/p/139114240
[28]mlinspect: https://github.com/stefan-grafberger/mlinspect
[29]Learning Certified Individually Fair Representations: https://arxiv.org/abs/2002.10312
[30]LASSI: https://openreview.net/pdf/ef57673caecc75ba98bd22450e6b7f6ef6feb4fb.pdf
[31]Fair Normalizing Flows: https://arxiv.org/abs/2106.05937
[32]diffai 项目: https://github.com/eth-sri/diffai
[33]MLPerf 项目: https://github.com/mlcommons/
