




目录
在上一篇文章中我给大家介绍了Vertica数据库脱颖而出的15个特性中的前5个,那么,今天我们继续介绍另外5个。好的,我们现在开始!

不依赖于底层存储

Vertica数据库以对基础设施的不可知而出名,它不在乎是什么品牌的供应商,这些供应商的存储设备可以装载TB容量级的数据,存储设备内置FPGA和GPU芯片并通过InfiniBand这样的高速带宽技术进行网络连接。

从上图我们可以看出,Vertica数据库甚至可以将一个表的不同分区的数据保存在不同的存储设备上,也可以将不同的表放在不同的存储上,如:本地磁盘和HDFS,或者是,SAN存储和亚马逊的S3上。还有一点,建议将表中的旧分区数据保存在价格相对便宜的存储上。另外,这些存储对用户来说,是完全透明的。

为物联网和点击流场景而生
Vertica数据库可以兼容ANSI SQL标准,能够对数据进行实时的洞察和分析,以了解当前新的趋势。一般来说,物联网和点击流场景正需要像Vertica这样的大数据分析平台。
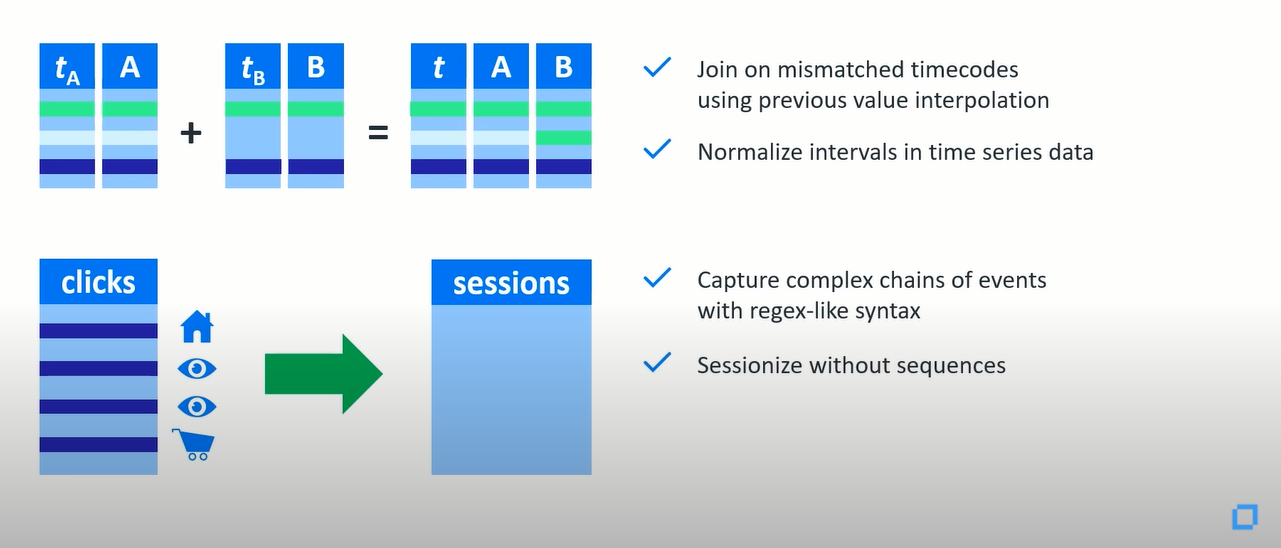
Vertica总是领先一步,它现在提供对OLAP扩展的全面支持,像地理空间分析、时间序列和机器学习这样的场景。
现在我们只考虑物联网场景的时间序列。假如,这里有两个传感器的数据不同步,如何把它们很好地结合起来?您只需在不匹配的时间码上插入值并连接两个表,您还可以对时间序列数据中的间隔进行标准化。如果你想让你的传感器数据变得有意义,一定需要做很多事情。
接着,让我们谈一下点击流场景中的复杂事件处理,您需要捕获在几个小时中发生的一系列事件,这个没有问题。将单个事件定义为连续的条件为B和C并查找包含B和C的正则表达式,客户输入您的站点,您在网站内进行了购买,是否还有其他东西定义了整个点击链?它是作为单个用户会话的整个序列,然后找到它发生的所有时间,这里会话作为您的数据,而不使用性能瓶颈序列或者填补数据的空白。因为传感器总是不可靠的,您不需要写自定义代码或为此安装专用的时间序列数据库。这一切都是开箱即用的!!!

支持端到端的机器学习工作流
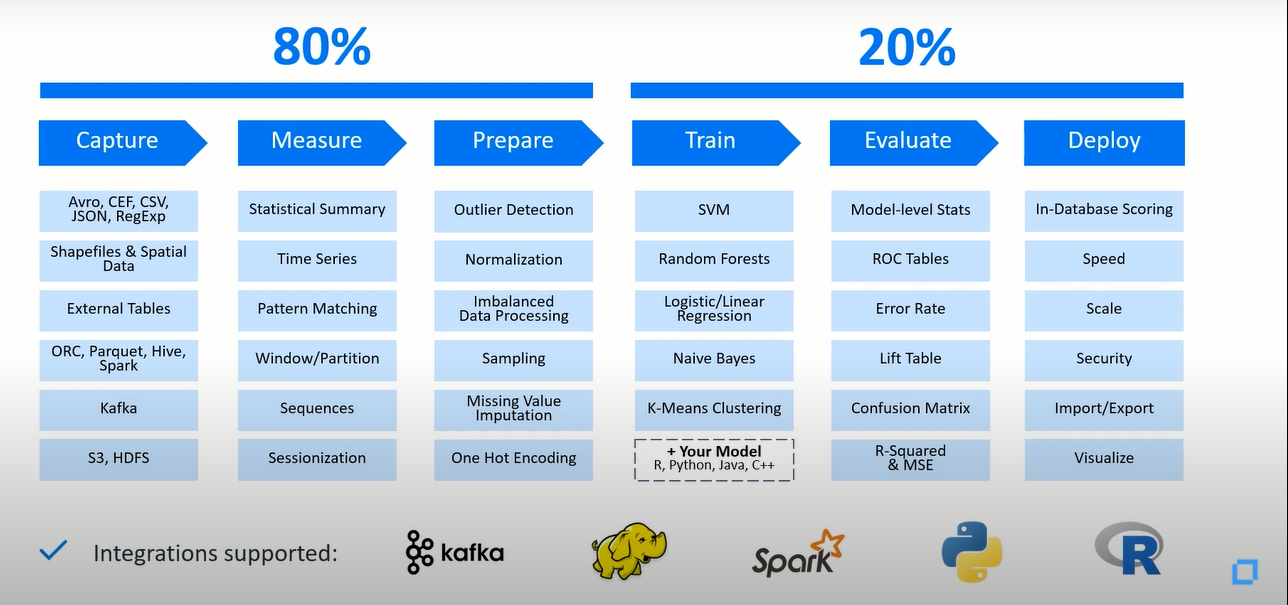
现在人们已经意识到,是时候将他们以某种方式存储了多年的数据进行变现或盈利了。他们认为这是一件明智的事情,但机器学习是一个技术门槛极高的新型行业,数据科学家是高级DBA们年龄的一半,那么您如何很好地弥合这一差距?您只需要一个单一的平台,为您提供使用机器学习的整个流程,将数据变现所作的一切工作会占据您80%的时间(在捕获数据、标准化数据、准备数据这三个阶段)。
众所周知,数据科学家们不开发和研究机器学习的算法,他们只负责收集和准备数据。为机器学习准备大量的源数据,这是一项极其艰巨的任务,我们内置了所有必需的PB数量级的工具(包括:异常值检测、缺失值插补、标准化、一次性热编码)。
如果数据科学家想要在Python中工作,他们可以使用原生的Python客户端、本机Python库、用于用户定义函数的本机Python API,包括机器学习算法。
如果分析师想做机器学习相关的工作,可是他们想要使用用SQL做所有事情,没有问题。这一切都是原生的SQL,它是一个SQL数据库。我们没有额外的硬件、没有额外的软件、没有自定义代码。一切都是开箱即用!!!

支持原生JSON、日志格式、Hive的orc和parquet文件存储格式

Vertica数据库支持原生JSON、日志格式、Hive的Orc和Parquet文件存储格式,它不仅与基础架构和存储无关,而且在很大程度上也与文件存储格式无关。如果您想使用正则表达式记录日志文件,您无需为此费心。我们使用弹性表(Flexible Table) 可以做得更好更快,您想将JSON映射到关系数据库结构模型上,我们可以使用弹性表更好更快地实现。您想从设备的日志中收集CSV文件,但列的顺序已更改,适合于一次更新弹性表的一个语句,现在基于列名而不是列顺序。您希望比任何基于Hadoop的解决方案更快地使用Parquet和Orc这样的文件格式,也许您只是恰巧有一些Spark文件,但是根本没有Hadoop集群。您希望在不将任何数据导入数据库的情况下完成所有这些工作,通过使用外部表允许您在动态扫描数据的同时执行这些操作,如果您再次加载它时会更快。这些统统没有添加硬件、没有添加软件、没有自定义代码,都是开箱即用。

非常灵活的体系架构适用于任何项目

从Oracle或SQL Server准备数据集市以加速他们的数据仓库,现在他们正在做他们从未想过的事情。一个物理服务器到一个带有数据和S3的云服务集合,它们能够以任何方式加载数据。他们想要从隔夜加载到新的实时流媒体,他们准备好了想要从数据库转换到实时流,但是他们想要从完全扁平化到标准化扁平化再到数据库支持的第六范式,所有这一切都归功于它们具有的灵活性。
以上就是这篇文章的所有内容,感谢您从百忙之中抽出您的宝贵时间阅读,如果您有好的意见或建议,欢迎在评论区留言,我将逐一回复,再次感谢!另外,我的下一篇文章将要介绍Vertica数据库脱颖而出的15个特性中的最后5个,敬请期待!!!
