




Provider端接收到请求后,会统一使用线程池进行处理,本文会对Dubbo使用线程池的参数进行源码解析。
线程池在dubbo调用链中所处位置如下图:
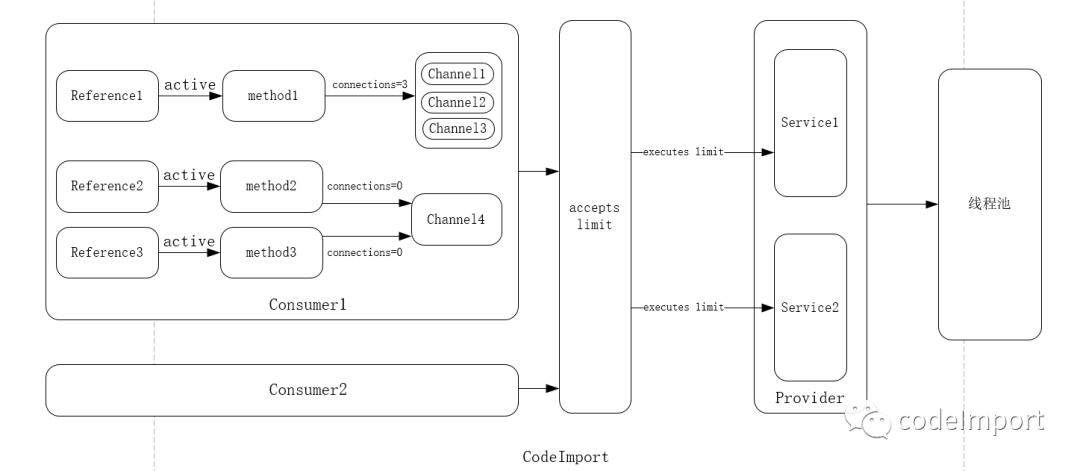
1.Dubbo可以使用哪些类型的线程池?
•fixed: 固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)•cached: 缓存线程池,空闲一分钟自动删除,需要时重建。•limited: 可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。
2.threadpool如何配置?
由于线程池是所有Service共享,所以需要配置在protocol上
dubbo.protocol.threadpool=fixed
dubbo.protocol.threads=100
dubbo.protocol.queues=100
3.threadpool源码分析
dubbo默认使用fixed类型的线程池,我就使用该类型的线程池进行分析,其他类型比较少用,但原理类似。
这里先说下如何自定义一个线程池,线程池的构造函数如下:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);}
•corePoolSize:初始化线程池线程数量•maximumPoolSize:线程池可以创建的最大线程数量•keepAliveTime:线程的最大过期时间,超过此时间,就将该线程关闭•unit:上面的时间单位•workQueue:缓存任务的队列•threadFactory:创建线程的工厂,可以在这里设置线程名•defaultHandler:如果任务数超过了线程池的最大可处理数后的执行策略
线程池执行任务的过程是:首先初始化corePoolSize数量的线程,当任务数超过了该值,会将任务放入workQueue中。如果队列满,则线程池会继续创建线程直到maximumPoolSize。如果任务数大于workQueue与maximumPoolSize的总数,则会执行defaultHandler
知道线程池的工作原理后,我们看下Dubbo是如何创建线程池的:
public class FixedThreadPool implements ThreadPool {public FixedThreadPool() {}public Executor getExecutor(URL url) {String name = url.getParameter("threadname", "Dubbo");int threads = url.getParameter("threads", 200);int queues = url.getParameter("queues", 0);return new ThreadPoolExecutor(threads, threads, 0L, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));}}
由FixedThreadPool的构造参数可知,默认情况下,Dubbo会创建200条线程,最大线程数也是200。如果queue小于0,则会使用无界的队列,也就是Dubbo可以接收不限数量的任务(有可能会导致OOM)。如果queue等于0,则会使用SynchronousQueue队列,该队列可以认为是一个没有容量的队列,也就是最大可以处理的任务数为200。如果queue大于0,则使用有界队列,就是最大可以处理的任务数为200+queue。
JDK自带的FixdThreadPool的有缺陷的,当任务数无限增长的时候会引发OOM,而Dubbo自定义的这个FixedThreadPool默认情况下规避了这个问题,因为默认情况下队列的容量是有限的,如果超过200就直接拒绝执行了。切记queue不要小于0,否则还是可能会OOM
4.如何估算线程数?
Dubbo的默认配置并不一定适合所有的业务场景,线程池的配置要根据具体的机器以及业务类型来决定。在电商业务类型下,任务大部分都是IO密集型的,而IO密集型的线程数可以根据如下公式计算得出:线程池线程数=CPU核数*(响应时间/(响应时间-调用第三方接口时间-访问数据库时间))。
比如一个获取商品详细的接口平均响应时间为50ms,调用库存接口用了10ms,调用优惠接口用了10ms,调用数据库用来20ms,该服务所在机器CPU核数为10,则可以估算出线程数为:threads=10*(50/50-10-10-20)=50。
5.如果超出了线程池最大可处理数会如何处理?
如果线上流量激增,任务数大于200,则会执行自定义的拒绝策略AbortPolicyWithReport,我们看下该类的源码是如何实现的:
public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor e) {String msg = String.format("Thread pool is EXHAUSTED!" +" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: "+ "%d)," +" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(),e.getLargestPoolSize(),e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),url.getProtocol(), url.getIp(), url.getPort());logger.warn(msg);dumpJStack();throw new RejectedExecutionException(msg);}}
从源码可以看到AbortPolicyWithReport继承自AbortPolicy,AbortPolicy的默认行为是如果任务超过线程池的最大处理能力则直接拒绝任务并抛出异常。而AbortPolicyWithReport除了抛出异常外,还打印了一条非常详细的日志,该日志包含了线程池的详细配置,并且在用户的家目录下面导出了一个Dubbo_JStack.log文件。
如果对这个策略不满意,我们也可以使用自定义其他策略,比如不是立刻拒绝该任务,而是等待一定时间后再执行该任务。
6.总结
线程数要根据机器跟具体业务合理估算;
队列数不要小于0;
如果对默认的拒绝策略不满意,可以根据业务写一个;
References
[1]
线程模型: http://dubbo.apache.org/zh-cn/docs/user/demos/thread-model.html[2]
线程池的三种队列区别: https://blog.csdn.net/qq_26881739/article/details/80983495
近期热文
