




本文根据腾讯数据平台部李勇的《腾讯大数据平台与应用推荐架构》和蒋洁的《深度揭秘腾讯大数据平台》整理而成,主要是按照个人的关注重点对两篇文章内容进行整合和裁剪,同时添加了个人的部分理解,文末附有两篇文章的链接——哈特。
一、腾讯大数据平台整体规划
腾讯大数据平台现在主要从离线和实时两个方向支撑海量数据接入和处理,核心模块有:TDW、TRC、TDBank、TPR和Gaia。

简单来说,TDW用来做批量的离线计算,TRC负责做流式的实时计算,TPR负责精准推荐,TDBank则作为统一的数据采集入口,而底层的Gaia则负责整个集群的资源调度和管理。
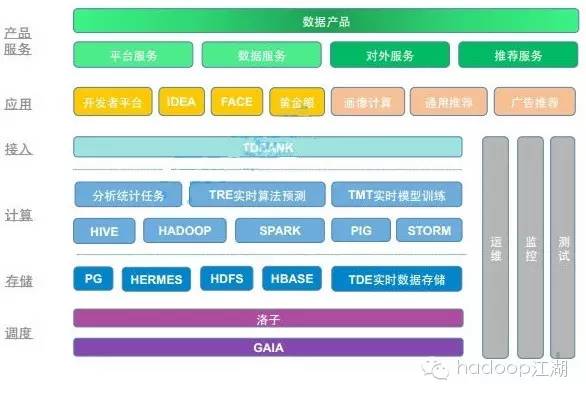
腾讯大数据平台整体规划
二、腾讯大数据平台技术架构
目前流行的资源系统的开源项目主要有Yarn、Corona以及Mesos,而腾讯最终选择了Yarn。
业务支持上,它可以兼容TDW原来的MR、hive等任务,对于Storm、Spark等,Yarn也可以有较好支持;从Yarn自身看,虽然它出现最晚,目前也最不成熟,但是它的可扩展性的架构优势以及良好的兼容性,Container的资源管理方式等,都代表了未来资源管理系统的趋势;最后从社区的活跃度以及生态圈看,不但有MR On Yarn、Storm On Yarn,Hive On Yarn,Hbase On Yarn,而比较新兴的samza、spark等,也都在“On Yarn”。Corona和Mesos主要是facebook和twitter在使用,并且他们也同时使用Hadoop集群,这两个开源项目社区都远远不如Hadoop社区活跃,影响力也差很多。基于这些现实原因,腾讯最终选择了目前并不是很完善的Yarn。
然而,如前所述,Yarn还非常不完善。尤其是在大规模集群的场景下,而腾讯的集群规模更大,作业并发度更高,业务场景更多,把开源Yarn直接拿过来使用,显然是不够的。要知道,Hadoop升级到1.0用了差不多7,8年的时间,而且经过了无数大公司包括Yahoo,Facebook,BAT这样的公司不停的更新、修补才稳定下来。Hadoop2才出现不到一年,根本没有经过长期稳定的测试和运行,看最近Hadoop从2.3升级到2.4只用了一个半月,就修复了 400多个bug。
因此,腾讯开发了自研的调度器sfair,提升Yarn的调度能力以及集群的可扩展性,同时,在资源管理方面,优化了Yarn的内存资源管理,增加了网络带宽等维度的管理可以说,腾讯的集群资源管理和调度系统又不仅仅是Yarn。
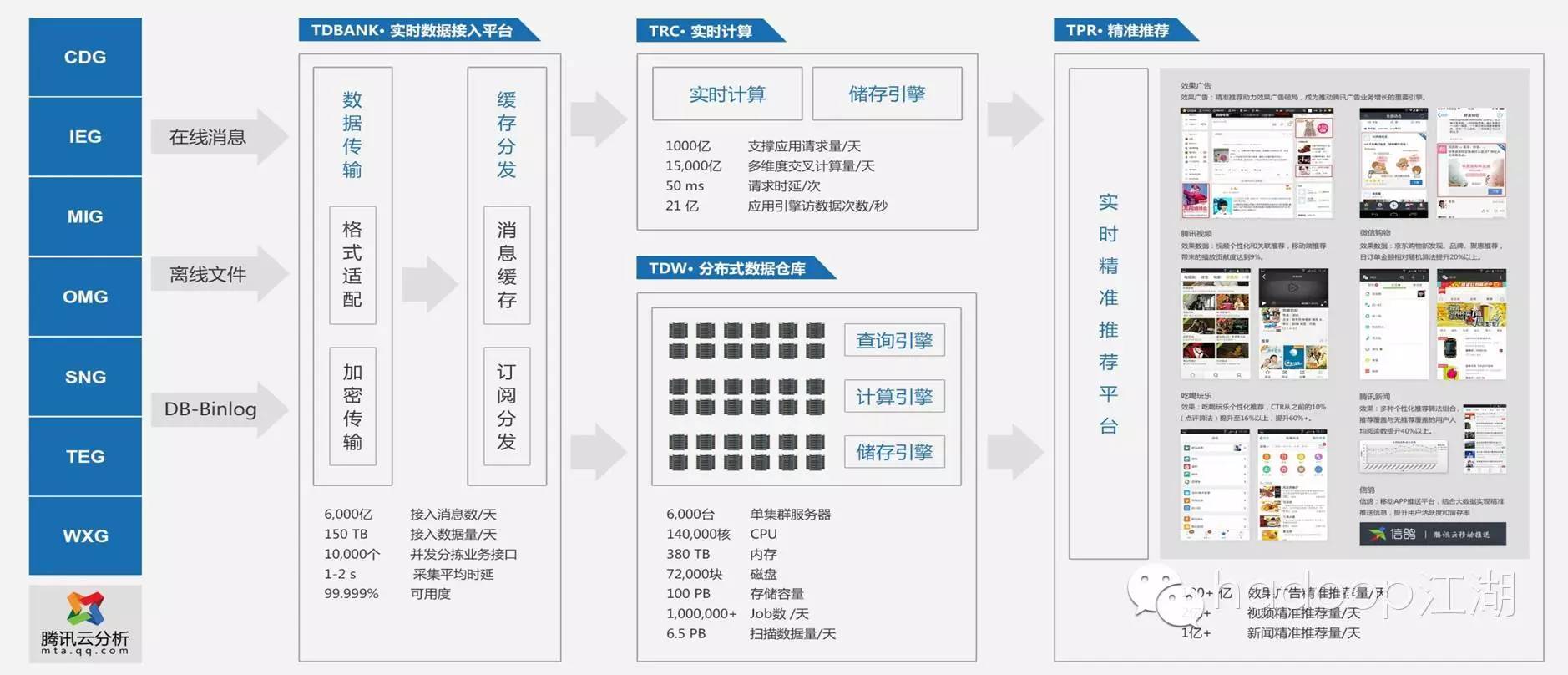
腾讯大数据平台技术架构
1、TDW
TDW是腾讯自研分布式数据仓库,基于开源的hadoop+hive架构做了大量优化,包括兼容商业数据库语法和hadoop单点消除及可扩展性提升等,是腾讯最大的离线处理平台,目前接入的数据量已达到百P级别,并伴随业务的发展和新业务的出现不断快速增长。
TDW的核心技术:HDFS、MapReduce、Hive。
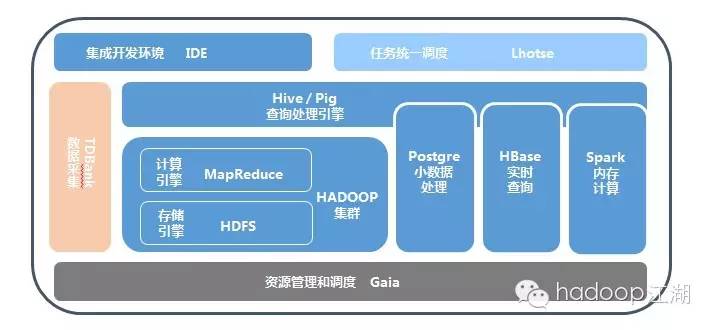
TDW技术架构
2、TRC
TRC是腾讯基于storm研发的实时计算平台,腾讯将社区的storm用java重新改写以提升稳定性和效率,为了解决资源利用率和集群规模的问题,重构了底层调度模块,实现了任务级别的权限管理、资源分配、资源隔离,并且使它运行在统一资源管理平台GAIA上,进一步提升集群效率和扩展能力;同时为TRC开发了SQL和Pig用户接口;目前TRC每天提供几万亿次实时计算能力,在以效果广告为代表的趋势预测、交叉分析、实时统计等领域的应用上取得了非常好的效果。
TRC的核心技术有三点:
1、Java for Storm:纯java语言实现,更好的可维护性;功能扩充:解决nimbus单点、度量(Metrics)、安全/权限增加、动态升级。
2、Storm on Gaia:任务间资源隔离,灵活的权限控制策略,更优异的容灾能力,自动扩缩容。
3、PigLatin/SQL on Storm:过程化类SQL编程接口,降低实时计算业务技术门槛,提升业务开发效率。
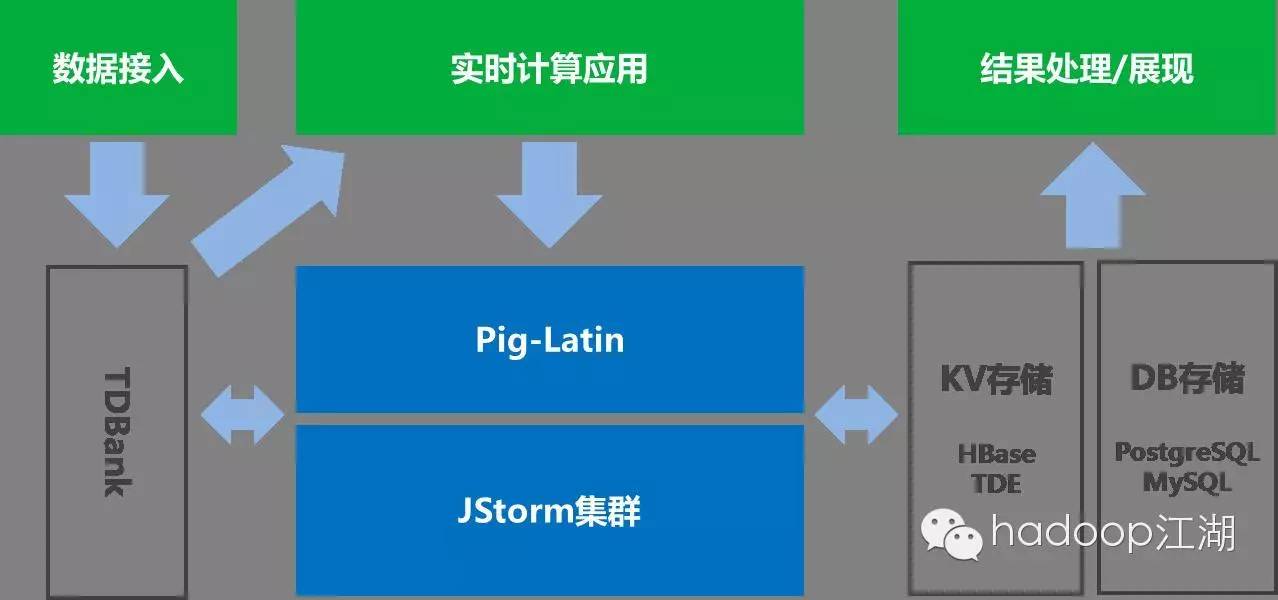
TRC技术架构
3、TDBank
TDBank是腾讯在数据接入方面研发的实时数据接入和分发系统,TDBank从业务数据源端实时采集数据,进行预处理和分布式消息缓存后,按照消息订阅的方式,分发给后端的离线和在线处理系统。
TDBank构建数据源和数据处理系统间的桥梁,将数据处理系统同数据源解耦,为离线计算TDW和在线计算TRC平台提供数据支持。通过不断的改进,将以前Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将以前一天才能处理的消息量缩短到2秒钟!
在这里,腾讯主要对TDbank做了异构数据源适配,跨城公网传输,数据高一致性保证,分布式消息队列等;目前TDBank每天收集的数据量接近10000亿条,这些数据主要输送给TDW和TRC,分别作离线分析和实时计算,可以说,成功支撑海量实时和离线处理的前提。
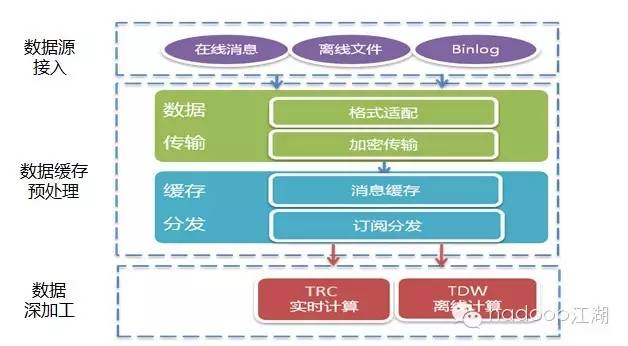
TDbank业务逻辑
从架构上来看,TBank可以划分为前端采集、消息接入、消息存储和消息分拣等模块。前端模块主要针对各种数据形式(普通文件,DB增量/全量,Socket消息,共享内存等)提供实时采集组件,提供了主动且实时的数据获取方式。中间模块则是具备日接入量万亿级的基于“发布——订阅”模型的分布式消息中间件,它起到了很好的缓存和缓冲作用,避免了因后端系统繁忙或故障从而导致的处理阻塞或消息丢失。针对不同的应用场景,TDBank提供数据主动订阅模式,以及不同的数据分发支持(分发到TDW数据仓库,文件,DB,HBase,Socket等)。整个数据通路透明化,只需简单配置,即可实现一点接入,整个大数据平台可用。
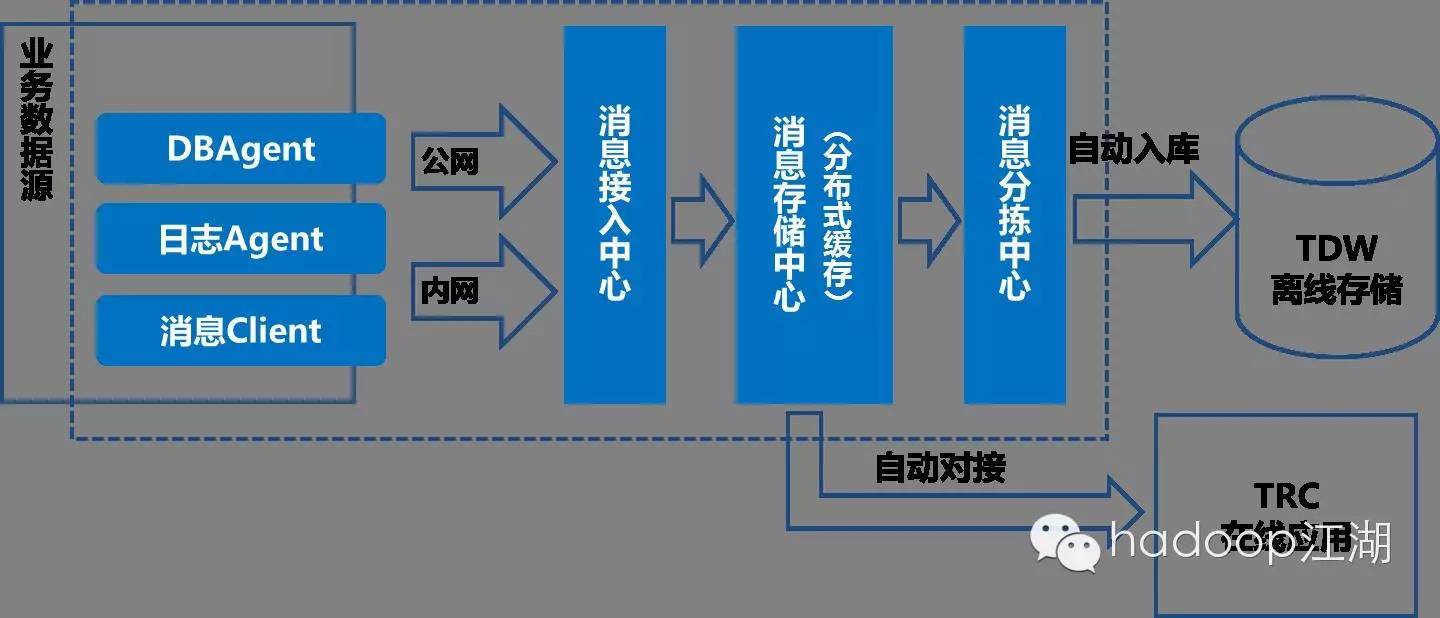
TDbank架构
4、Gaia
Gaia是腾讯 基于Yarn的通用资源调度平台,提供高并发任务调度和资源管理,实现集群资源共享、可伸缩性和可靠性,不仅可以为MR等离线业务提供服务,还可以支持实时计算,甚至在线service业务。
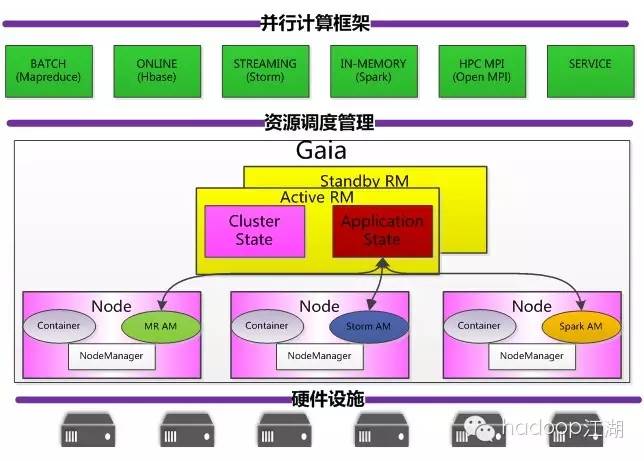
1)YARN的基本思想:
将JobTracker的两大主要职能:资源管理、作业的调度/监控拆分为两个独立的进程:一个全局的ResourceManager和与每个application对应的ApplicationMaster(AM)。 ResourceManager和每个节点上的NodeManager(NM)组成了全新的通用操作系统,以分布式的方式管理应用程序。
ResourceManager拥有为系统中所有应用的资源分配的决定权。对应于每个application的ApplicationMaster是框架相关的,负责与ResourceManager协商资源,以及与NodeManager协同工作来执行和监控各个任务。
ResourceManager有一个可插拔的调度器组件——scheduler,负责为运行中的各种应用分配资源,分配时会受到容量,队列及其他因素的制约。Scheduler是一个纯粹的调度器,不负责application的监控和状态跟踪,也不保证在application失败或者硬件失败的情况下对task的重启。 Scheduler基于application的资源需求来执行其调度功能,使用了叫做资源 container的抽象概念,其中包括了多种资源维度,如内存,CPU,磁盘,以及网络。
NodeManager是与每台机器对应的slave进程,负责启动application的container,监控它们的资源使用情况(CPU,内存,磁盘和网络),并且报告给ResourceManager。
每个 application的ApplicationMaster负责与Scheduler协商合适的container,跟踪application的状态,以及监控它们的进度。从系统的角度讲,ApplicationMaster也是以一个普通container的身份运行。
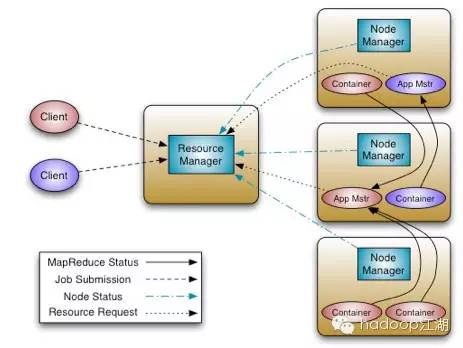
Yarn架构
2)Gaia对Yarn的扩展,自研高性能调度器sfair:
Yarn调度器主要分为三个阶段:
1)选择一个队列:递归的对子队列进行排序,找到第一个可以assign的队列,从而找到叶子队列;
2)选择一个app:对本队列的所有app进行排序,然后遍历这些app,找到可以assign的那个app;
3)执行matchmaking。
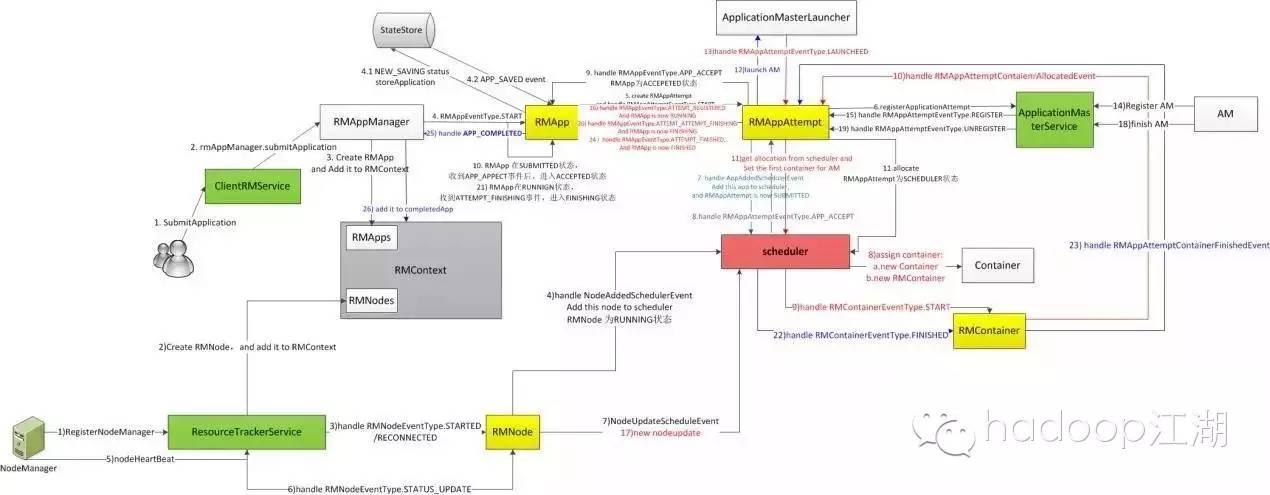
scheduler
Gaia今年内的目标是,支持单cluster 8800节点的规模,而Yarn原生的调度器显然不满足要求,为此,腾讯开发了自研的调度器sfair(scalable fair scheduler),主要着力于提升可扩展性。在开发sfair调度器的过程中,通过减少sort次数、优化comparator、控制多线程的同步,以及仔细的profiling,找到关键路径。目前已经上线,并且大幅度的提升了调度吞吐,支持毫秒级的下发。同时,优化了作业优先级和抢占的策略,使调度更加公平。
三、挑战
对于腾讯来说最大的挑战更多的是在技术层面,必须快速跟上,还要力争引领技术的更新和换代,以应对互联网业务的飞速变化,还有对于大数据日渐深入的应用带来的更高要求,因此,对于从事大数据的研发人员来说,不要局限于自身现有的能力,而是让自我的知识面更广,在不断尝试中选择最优的技术从而提供更好的服务,同时在拥抱开源的过程中参与开源,从而跟上技术更新步伐。
参考文章链接:
http://www.36dsj.com/archives/17941
http://www.csdn.net/article/2014-08-29/2821448

