




一、实验步骤说明
二、准备工作(两台机器都要操作)
三、DBRD配置(两台机器都要操作)
四、两台DRBD主机上添加硬盘
五、在两台机器上分别创建DRBD设备并激活r0资源
六、初始设备同步
6.1 选择初始同步源
6.2 启动初始化全量同步
八、挂在文件系统/data,主节点操作
九、DRBD提升和降级资源测试(手动故障主备切换)
十、NFS的安装(主从都要安装)
十一、keepalived安装(主从都要安装配置)
十二、NFS客户端挂载测试
十三、整个架构的高可用环境故障自动切换测试
十四、总结
一、实验步骤说明
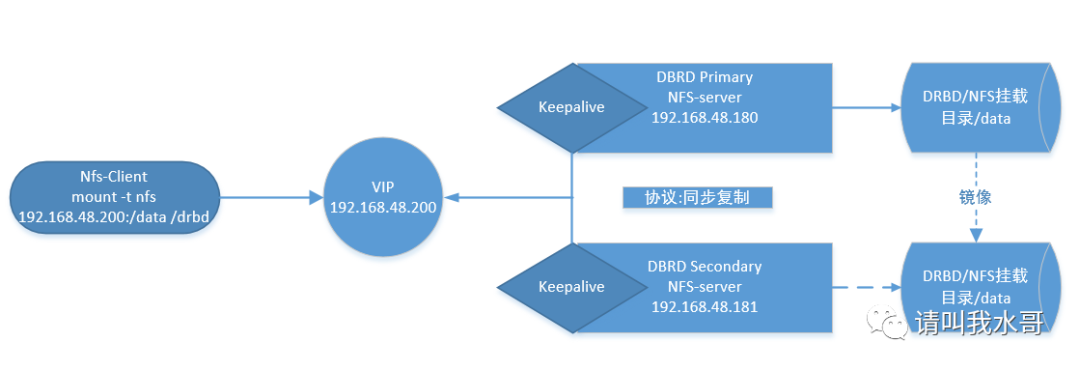
在两台机器上安装keepalived,VIP为192.168.48.200
DRBD的挂载目录/data作为NFS的挂载目录。远程客户机使用vip地址挂载NFS
当Primary主机发生宕机或NFS挂了的故障时,Secondary主机提权升级为DRBD的主节点,并且VIP资源也会转移过来。
当Primary主机的故障恢复时,会再次变为DRBD的主节点,并重新夺回VIP资源。从而实现故障转移
实验拓扑图:
二、准备工作(两台机器都要操作)
安装最新版本的drbd90版
Primary和Secondary两台主机的DRBD环境部署
Primary主机(192.168.48.180)默认作为DRBD的主节点,DRBD挂载目录是/data
Secondary主机(192.168.48.181)是DRBD的备份节点
1)服务器信息(centos7.4)192.168.48.180 主服务器 主机名:Primary192.168.48.181 备服务器 主机名:Secondary2)两台机器的防火墙要相互允许访问。最好是关闭selinux和iptables防火墙(两台机器同样操作)[root@Primary ~]# setenforce 0 //临时性关闭;永久关闭的话,需要修改/etc/sysconfig/selinux的SELINUX为disabled[root@Primary ~]#systemctl stop firewalld && systemctl stop iptables3)设置hosts文件(两台机器同样操作)[root@Primary drbd-8.4.3]# vim /etc/hosts192.168.1.151 Primary192.168.1.152 Secondary4)两台机器同步时间[root@Primary ~]# yum install -y ntpdate[root@Primary ~]# ntpdate ntp1.aliyun.com5)DRBD的安装配置(两台机器上同样操作)当前centOS7.4版本内核:[root@secondary ~]# uname -r3.10.0-693.el7.x86_64这里采用yum方式安装(也可以选择清华大学或者阿里云的源)# rpm -ivh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm# yum -y install drbd90-utils kmod-drbd90 #注意centos7.4安装会更新内核到3.10.0-1127.18.2.el7才支持。需要重启系统,从新内核进入=========================================================================================================================================Package 架构 版本 源 大小=========================================================================================================================================正在安装:drbd90-utils x86_64 9.12.2-1.el7.elrepo elrepo 720 kkernel x86_64 3.10.0-1127.18.2.el7 updates 50 Mkmod-drbd90 x86_64 9.0.22-2.el7_8.elrepo elrepo 284 k为依赖而更新:linux-firmware noarch 20191203-76.gite8a0f4c.el7 base 81 M##由于新版本涉及了内核的更新,所以需要重启系统,使用新内核启动[root@primary ~]# uname -r3.10.0-1127.18.2.el7.x86_646)加载模块:[root@primary ~]# modprobe drbd[root@primary ~]# lsmod |grep drbddrbd 573100 0libcrc32c 12644 4 xfs,drbd,nf_nat,nf_conntrack
三、DBRD配置(两台机器都要操作)
1)确认配置文件[root@primary ~]# cat /etc/drbd.conf# You can find an example in /usr/share/doc/drbd.../drbd.conf.exampleinclude "drbd.d/global_common.conf"; #global和common配置路径include "drbd.d/*.res"; #资源文件配置路径2)编辑全局配置文件及资源配置文件[root@primary ~]# cat /etc/drbd.d/global_common.conf |egrep -v "^.*#|^$"global {usage-count yes;}common {protocol C; //采用完全同步复制模式handlers {}startup {wfc-timeout 240;degr-wfc-timeout 240;outdated-wfc-timeout 240;}options {}disk {on-io-error detach;}net {cram-hmac-alg md5;shared-secret "testdrbd";}}[root@primary ~]# cat /etc/drbd.d/r0.resresource r0 {on Primary {device /dev/drbd0; //这是Primary机器上的DRBD虚拟块设备,事先不要格式化disk /dev/sdb1;address 192.168.48.180:7789; //官网示例文件规定的进行网络连接端口,也可自定义meta-disk internal;}on Primary {device /dev/drbd0;disk /dev/sdb1;address 192.168.48.181:7789;meta-disk internal;}}##拷贝到备用机上[root@primary ~]# cd /etc/drbd.d/[root@primary drbd.d]# scp r0.res global_common.conf root@192.168.48.181:/etc/drbd.droot@192.168.48.181's password:r0.res 100% 222 219.6KB/s 00:00global_common.conf 100% 2743 1.6MB/s 00:00
四、两台DRBD主机上添加硬盘
[root@Primary ~]# fdisk -l......[root@Primary ~]# fdisk /dev/sdb依次输入"n->p->1->1->回车->w" //分区创建后,再次使用"fdisk /dev/vdd",输入p,即可查看到创建的分区,比如/dev/vdd1在Secondary机器上添加一块10G的硬盘作为DRBD,分区为/dev/vde1,不做格式化,并在本地系统创建/data目录,不做挂载操作。[root@Secondary ~]# fdisk -l......[root@Secondary ~]# fdisk /dev/sdb依次输入"n->p->1->1->回车->w"
五、在两台机器上分别创建DRBD设备并激活r0资源
1)创建drdb磁盘设备[root@primary ~]# mknod /dev/drbd0 b 147 0[root@primary ~]# ll /dev/drbd0brw-r--r-- 1 root root 147, 0 Aug 8 10:15 /dev/drbd0 exists2)创建drdb设备的元数据[root@Primary ~]# drbdadm create-md r0--== Thank you for participating in the global usage survey ==--The server's response is:you are the 13439th user to install this versioninitializing activity loginitializing bitmap (320 KB) to all zeroWriting meta data...New drbd meta data block successfully created.success3)再次输入该命令进行激活r0资源。这里也可以直接使用drbdadm up r0激活资源,官方推荐配置[root@primary drbd.d]# drbdadm create-md r0open(/dev/sdb1) failed: Device or resource busyExclusive open failed. Do it anyways?[need to type 'yes' to confirm] yes //输入yes# Output might be stale, since minor 0 is attachedDevice '0' is configured!Command 'drbdmeta 0 v09 /dev/sdb1 internal create-md 1' terminated with exit code 204)启动drbd服务(注意:需要主从共同启动方能生效)[root@primary drbd.d]# systemctl start drbd[root@primary drbd.d]# systemctl status drbd● drbd.service - DRBD -- please disable. Unless you are NOT using a cluster manager.Loaded: loaded (/usr/lib/systemd/system/drbd.service; disabled; vendor preset: disabled)Active: active (exited) since Sat 2020-08-08 10:43:08 EDT; 5s agoProcess: 1726 ExecStart=/lib/drbd/drbd start (code=exited, status=0/SUCCESS)Main PID: 1726 (code=exited, status=0/SUCCESS)Aug 08 10:42:23 primary systemd[1]: Starting DRBD -- please disable. Unless you are NOT using a cluster manager....Aug 08 10:42:23 primary drbd[1726]: Starting DRBD resources: /lib/drbd/drbd: line 148: /var/lib/linstor/loop_device_mapping: N...irectoryAug 08 10:42:23 primary drbd[1726]: [Aug 08 10:42:23 primary drbd[1726]: ]Aug 08 10:43:08 primary drbd[1726]: WARN: stdin/stdout is not a TTY; using /dev/consoleAug 08 10:43:08 primary drbd[1726]: .Aug 08 10:43:08 primary systemd[1]: Started DRBD -- please disable. Unless you are NOT using a cluster manager..Hint: Some lines were ellipsized, use -l to show in full.[root@primary drbd.d]# ps -ef |grep drbdroot 1267 2 0 09:52 ? 00:00:00 [drbd-reissue]root 1684 2 0 10:39 ? 00:00:00 [drbd_w_r0]root 1686 2 0 10:39 ? 00:00:00 [drbd0_submit]root 1698 2 0 10:39 ? 00:00:00 [drbd_s_r0]root 1704 2 0 10:39 ? 00:00:00 [drbd_r_r0]root 1740 2 0 10:43 ? 00:00:00 [drbd_a_r0]root 1741 2 0 10:43 ? 00:00:00 [drbd_as_r0]查看状态(两台机器上都执行查看)[root@primary drbd.d]# cat /proc/drbdversion: 9.0.22-2 (api:2/proto:86-116)GIT-hash: 719792f2cc1360c65c848ffdb66090959e27fde5 build by mockbuild@, 2020-04-05 03:16:50Transports (api:16): tcp (9.0.22-2)6) 检查磁盘状态,此时应该都是 Inconsistent/Inconsistent[root@primary drbd.d]# drbdadm statusr0 role:Secondarydisk:InconsistentSecondary role:Secondarypeer-disk:Inconsistent到目前为止,DRBD已经成功地分配了磁盘和网络资源,并准备就绪。然而它还不知道应该使用哪个节点作为初始设备同步的源
六、初始设备同步
要使DRBD完全运行,还需要两个步骤:
6.1 选择初始同步源
如果处理的是新初始化的空磁盘,则此选择完全是任意的。但是,如果您的某个节点已经有需要保留的有价值的数据,则选择该节点作为同步源至关重要。如果在错误的方向上执行初始设备同步,则会丢失该数据。这点要非常小心。
6.2 启动初始化全量同步
此步骤只能在一个节点上执行,只能在初始资源配置上执行,并且只能在您选择作为同步源的节点上执行。要执行此步骤,请输入以下命令:
[root@primary drbd.d]# drbdadm primary --force r0发出发出此命令后,将启动初始化全量同步。您将能够通过 drbdadm status 监视其进度。根据设备的大小,可能需要一些时间。此命令后,将启动初始化全量同步。您将能够通过 drbdadm status 监视其进度。根据设备的大小,可能需要一些时间。[root@primary drbd.d]# drbdadm statusr0 role:Primarydisk:UpToDateSecondary role:Secondaryreplication:SyncSource peer-disk:Inconsistent done:36.82 //这里有初始化全量同步过程......[root@primary drbd.d]# drbdadm statusr0 role:Primarydisk:UpToDateSecondary role:Secondaryreplication:SyncSource peer-disk:Inconsistent done:40.02[root@primary drbd.d]# drbdadm statusr0 role:Primarydisk:UpToDateSecondary role:Secondarypeer-disk:UpToDate //显示UpToDate/UpToDate 表示主从配置成功
现在,您的DRBD设备已经完全运行,甚至在初始化同步完成之前(尽管性能略有降低)。如果从空磁盘开始,现在可能已经在设备上创建了一个文件系统,将其用作原始块设备,挂载它,并对可访问的块设备执行任何其他操作。
八、挂在文件系统/data,主节点操作
1)先格式化/dev/drbd0[root@primary drbd.d]# mkfs.xfs /dev/drbd0meta-data=/dev/drbd0 isize=512 agcount=4, agsize=655274 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0data = bsize=4096 blocks=2621095, imaxpct=25= sunit=0 swidth=0 blksnaming =version 2 bsize=4096 ascii-ci=0 ftype=1log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1realtime =none extsz=4096 blocks=0, rtextents=02)创建挂载目录,然后执行DRBD挂载[root@Primary ~]# mkdir /data[root@Primary ~]# mount /dev/drbd0 /data[root@primary drbd.d]# df -hTFilesystem Type Size Used Avail Use% Mounted on/dev/mapper/centos-root xfs 39G 3.0G 36G 8% /devtmpfs devtmpfs 475M 0 475M 0% /devtmpfs tmpfs 487M 0 487M 0% /dev/shmtmpfs tmpfs 487M 6.7M 480M 2% /runtmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup/dev/sda1 xfs 1014M 155M 860M 16% /boot/dev/mapper/centos-home xfs 19G 33M 19G 1% /hometmpfs tmpfs 98M 0 98M 0% /run/user/0/dev/drbd0 xfs 10G 33M 10G 1% /data特别注意:Secondary节点上不允许对DRBD设备进行任何操作,包括只读,所有的读写操作只能在Primary节点上进行。只有当Primary节点挂掉时,Secondary节点才能提升为Primary节点3)备用节点创建挂在目录就可以了[root@secondary ~]# mkdir /data
九、DRBD提升和降级资源测试(手动故障主备切换)
在single-primary mode 主从模式(DRBD的默认设置)中,任何资源在任何给定时间只能在一个节点上处于主要角色,而connection state是连接的。因此,在一个节点上发出 drbdadm primary<resource> ,而该指定的资源是在另一个节点上的primary角色, 将导致错误。
配置为允许dual-primary mode双主模式的资源可以切换到两个节点上的主要角色;这是虚拟机在线迁移所必需的。
1. DBRD的提升和降级资源测试使用以下命令之一手动将aresource’s role从次要角色切换到主要角色(提升)或反之亦然(降级):##创建测试文件[root@primary drbd.d]# cd /data/[root@primary data]# touch file{1..5}[root@primary data]# lsfile1 file2 file3 file4 file5##切换测试[root@primary /]# drbdadm secondary r0 //切换资源到从节点,主节点降级r0: State change failed: (-12) Device is held open by someone //提示资源被占用,所以要先卸载磁盘,在进去降级操作additional info from kernel:/dev/drbd0 opened by mount (pid 1924) at 2020-08-08 15:18:58.781Command 'drbdsetup secondary r0' terminated with exit code 11[root@primary /]# umount /data/[root@primary /]# drbdadm secondary r0##从节点检查[root@secondary data]# drbdadm primary r0 //备用节点提权测试[root@secondary /]# mount /dev/drbd0 /data/[root@secondary /]# cd /data/[root@secondary data]# lsfile1 file2 file3 file4 file5 //可以看到数据已经同步##从节点测试是否能够写入数据[root@secondary data]# touch slave-{1..3}[root@secondary data]# lsfile1 file2 file3 file4 file5 slave-1 slave-2 slave-3 //可以写入,说明切换测试正常##查看此时drbd集群状态[root@primary ~]# drbdadm statusr0 role:Secondary //此时主变成备用节点disk:UpToDateSecondary role:Primary //此时从变成主节点peer-disk:UpToDate
十、NFS的安装(主从都要安装)
在Primary和Secondary两台主机上安装NFS(可以参考:http://www.cnblogs.com/kevingrace/p/6084604.html)[root@Primary ~]# yum install rpcbind nfs-utils[root@Primary ~]# vim /etc/exports/data 192.168.48.0/24(rw,sync,no_root_squash)[root@primary ~]# systemctl start rpcbind.service[root@primary ~]# systemctl enable rpcbind.service[root@primary ~]# systemctl start nfs-server.service[root@primary ~]# systemctl enable nfs-server.service
十一、keepalived安装(主从都要安装配置)
## yum安装keepalived[root@primary data]# yum install keepalived##Primary主机的keepalived.conf配置[root@primary keepalived]# cp keepalived.conf keepalived.conf.bak[root@Primary ~]# vim /etc/keepalived/keepalived.conf! Configuration File for keepalivedglobal_defs {notification_email {root@localhost}notification_email_from keepalived@localhostsmtp_server 127.0.0.1smtp_connect_timeout 30router_id DRBD_HA_MASTER}vrrp_script chk_nfs {script "/etc/keepalived/check_nfs.sh"interval 5}vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 51priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}track_script {chk_nfs}notify_stop /etc/keepalived/notify_stop.shnotify_master /etc/keepalived/notify_master.shvirtual_ipaddress {192.168.48.200}}##启动keepalived服务[root@primary keepalived]# systemctl start keepalived.service[root@primary keepalived]# systemctl enable keepalived.serviceCreated symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.[root@primary keepalived]# ps -ef |grep keepalivedroot 2666 1 0 11:58 ? 00:00:00 /usr/sbin/keepalived -Droot 2667 2666 0 11:58 ? 00:00:00 /usr/sbin/keepalived -Droot 2668 2666 0 11:58 ? 00:00:00 /usr/sbin/keepalived -Droot 2695 1235 0 11:58 pts/0 00:00:00 grep --color=auto keepalived##查看VIP[root@primary keepalived]# ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000link/ether 00:0c:29:30:b5:bd brd ff:ff:ff:ff:ff:ffinet 192.168.48.180/24 brd 192.168.48.255 scope global ens33valid_lft forever preferred_lft foreverinet 192.168.48.200/32 scope global ens33 //vip地址valid_lft forever preferred_lft foreverinet6 fe80::bb8e:bf99:3f66:42cc/64 scope linkvalid_lft forever preferred_lft forever##Secondary主机的keepalived.conf配置[root@primary keepalived]# scp keepalived.conf root@192.168.48.181:/etc/keepalived/keepalived.conf //拷贝主节点的配置文件root@192.168.48.181's password:keepalived.conf 100% 694 836.6KB/s 00:00[root@Secondary ~]# vim /etc/keepalived/keepalived.conf //调整配置文件! Configuration File for keepalivedglobal_defs {notification_email {root@localhost}notification_email_from keepalived@localhostsmtp_server 127.0.0.1smtp_connect_timeout 30router_id DRBD_HA_BACKUP}vrrp_instance VI_1 {state BACKUPinterface ens33virtual_router_id 51priority 90advert_int 1authentication {auth_type PASSauth_pass 1111}notify_master /etc/keepalived/notify_master.sh //当此机器为keepalived的master角色时执行这个脚本notify_backup /etc/keepalived/notify_backup.sh //当此机器为keepalived的backup角色时执行这个脚本virtual_ipaddress {192.168.48.200}}启动keepalived服务[root@secondary ~]# systemctl start keepalived.service[root@secondary ~]# systemctl enable keepalived.serviceCreated symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.[root@secondary ~]# ps -ef |grep keepalivedroot 13520 1 0 00:03 ? 00:00:00 /usr/sbin/keepalived -Droot 13521 13520 0 00:03 ? 00:00:00 /usr/sbin/keepalived -Droot 13522 13520 0 00:03 ? 00:00:00 /usr/sbin/keepalived -Droot 13548 12284 0 00:03 pts/0 00:00:00 grep --color=auto keepalived##四个脚本配置---------------1)此脚本只在Primary机器上配置[root@Primary ~]# vim /etc/keepalived/check_nfs.sh#!/bin/bash##检查nfs服务可用性:进程和是否能挂载systemctl status nfs-server &> /dev/nullif [ $? -ne 0 ];then //-ne测试两个整数是否不等,不等为真,相等为假。##如果服务不正常,重启服务systemctl restart nfs-serversystemctl status nfs-server &>/dev/nullif [ $? -ne 0 ];then##若重启后还不正常。卸载drbd0,并降级为备用节点umount /dev/drbd0drbdadm secondary r0##关闭keepalived服务systemctl stop keepalivedfifi[root@Primary ~]# chmod 755 /etc/keepalived/check_nfs.sh2)此脚本只在Primary机器上配置[root@Primary ~]# mkdir /etc/keepalived/logs[root@primary keepalived]# cat notify_stop.sh#!/bin/bashtime=`date "+%F %H:%M:%S"`echo -e "$time ------notify_stop------\n" >> /etc/keepalived/logs/notify_stop.logsystemctl stop nfs-server &>> /etc/keepalived/logs/notify_stop.logumount /data &>> /etc/keepalived/logs/notify_stop.logdrbdadm secondary r0 &>> /etc/keepalived/logs/notify_stop.logecho -e "\n" >> /etc/keepalived/logs/notify_stop.log[root@Primary ~]# chmod 755 /etc/keepalived/notify_stop.sh3)此脚本在两台机器上都要配置[root@primary keepalived]# cat notify_master.sh#!/bin/bashtime=`date "+%F %H:%M:%S"`echo -e "$time ------notify_master------\n" >> /etc/keepalived/logs/notify_master.logdrbdadm primary r0 &>> /etc/keepalived/logs/notify_master.logmount /dev/drbd0 /data &>> /etc/keepalived/logs/notify_master.logsystemctl restart nfs-server &>> /etc/keepalived/logs/notify_master.logecho -e "\n" >> /etc/keepalived/logs/notify_master.log[root@Primary ~]# chmod 755 /etc/keepalived/notify_master.sh4)此脚本只在Secondary机器上配置[root@Secondary ~]# mkdir /etc/keepalived/logs[root@secondary keepalived]# cat notify_backup.sh#!/bin/bashtime=`date "+%F %H:%M:%S"`echo -e "$time ------notify_stop------\n" >> /etc/keepalived/logs/notify_backup.logsystemctl stop nfs-server &>> /etc/keepalived/logs/notify_backup.logumount /data &>> /etc/keepalived/logs/notify_backup.logdrbdadm secondary r0 &>> /etc/keepalived/logs/notify_backup.logecho -e "\n" >> /etc/keepalived/logs/notify_backup.log[root@Secondary ~]# chmod 755 /etc/keepalived/notify_backup.sh-----------------------------------------------------------------------------------------------------------
十二、NFS客户端挂载测试
在远程客户机上挂载NFS客户端只需要安装rpcbind程序,并确认服务正常[root@nfsclient ~]# yum -y install rpcbind nfs-utils[root@nfsclient ~]# systemctl start rpcbind && systemctl enable rpcbind挂载NFS[root@nfsclient ~]# mount -t nfs 192.168.48.200:/data /drbd如下查看,发现已经成功挂载了NFS[root@nfsclient ~]# df -hT文件系统 类型 容量 已用 可用 已用% 挂载点/dev/mapper/centos-root xfs 36G 6.8G 29G 20% /devtmpfs devtmpfs 897M 0 897M 0% /devtmpfs tmpfs 912M 0 912M 0% /dev/shmtmpfs tmpfs 912M 9.0M 903M 1% /runtmpfs tmpfs 912M 0 912M 0% /sys/fs/cgroup/dev/sda1 xfs 1014M 180M 835M 18% /boottmpfs tmpfs 183M 32K 183M 1% /run/user/0192.168.48.200:/data nfs4 10G 33M 10G 1% /drbd //挂载的目录[root@nfsclient ~]# cd /drbd/[root@nfsclient drbd]# lsfile1 file2 file3 file4 file5 slave-1 slave-2 slave-3
十三、整个架构的高可用环境故障自动切换测试
13.1 先关闭Primary主机上的keepalived服务。就会发现VIP资源已经转移到Secondary主机上了。同时,Primary主机的nfs也会主动关闭,同时Secondary会升级为DRBD的主节点
## 停止主节点的keepalived服务,vip资源已经漂移[root@primary keepalived]# systemctl stop keepalived.service[root@primary keepalived]# ip addr |grep ens332: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000inet 192.168.48.180/24 brd 192.168.48.255 scope global ens33##查看备节点,是否接管了vip[root@secondary keepalived]# ip addr |grep ens332: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000inet 192.168.48.181/24 brd 192.168.48.255 scope global ens33inet 192.168.48.200/32 scope global ens33## 查看系统日志,vip漂移信息[root@primary keepalived]# tailf /var/log/messages //主节点日志切换记录Aug 8 12:34:50 primary Keepalived_vrrp[2668]: Sending gratuitous ARP on ens33 for 192.168.48.200Aug 8 12:45:53 primary chronyd[714]: Selected source 119.28.206.193Aug 8 12:45:58 primary Keepalived[2666]: StoppingAug 8 12:45:58 primary systemd: Stopping LVS and VRRP High Availability Monitor...Aug 8 12:45:58 primary Keepalived_vrrp[2668]: VRRP_Instance(VI_1) sent 0 priorityAug 8 12:45:58 primary Keepalived_vrrp[2668]: VRRP_Instance(VI_1) removing protocol VIPs.Aug 8 12:45:58 primary Keepalived_healthcheckers[2667]: StoppedAug 8 12:45:59 primary Keepalived_vrrp[2668]: StoppedAug 8 12:45:59 primary Keepalived[2666]: Stopped Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2Aug 8 12:45:59 primary systemd: Stopped LVS and VRRP High Availability Monitor.[root@primary keepalived]# tailf /var/log/messages //备节点日志切换记录Aug 9 00:34:45 secondary Keepalived_vrrp[13522]: VRRP_Instance(VI_1) Entering BACKUP STATEAug 9 00:45:59 secondary Keepalived_vrrp[13522]: VRRP_Instance(VI_1) Transition to MASTER STATEAug 9 00:46:00 secondary Keepalived_vrrp[13522]: VRRP_Instance(VI_1) Entering MASTER STATEAug 9 00:46:00 secondary Keepalived_vrrp[13522]: VRRP_Instance(VI_1) setting protocol VIPs.Aug 9 00:46:00 secondary Keepalived_vrrp[13522]: Sending gratuitous ARP on ens33 for 192.168.48.200Aug 9 00:46:00 secondary Keepalived_vrrp[13522]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens33 for 192.168.48.200##会触发notify_stop脚本,停止nfs,卸载/data,drbd降级操作,依次检查是否正确?[root@primary keepalived]# ps -ef |grep nfs //已经没有nfs进程root 3557 1235 0 13:03 pts/0 00:00:00 grep --color=auto nfs[root@primary keepalived]# df -hT |grep /data |wc -l //data目录已经卸载0[root@primary keepalived]# drbdadm statusr0 role:Secondary //此时主节点已经切换成备节点了disk:UpToDateSecondary role:Primary //此时备节点已经切换成主节点了peer-disk:UpToDate##备用节点检查[root@secondary keepalived]# df -hT|grep /data/dev/drbd0 xfs 10G 33M 10G 1% /data[root@secondary keepalived]# cd /data/[root@secondary data]# lsfile1 file2 file3 file4 file5 slave-1 slave-2 slave-3##客户端检查[root@nfsclient drbd]# lsfile1 file2 file3 file4 file5 slave-1 slave-2 slave-3[root@secondary data]# rm -rf slave-* //现在主节点删除数据测试,客户端是否同步[root@nfsclient drbd]# lsfile1 file2 file3 file4 file5 //slave文件已经没有了。说明同步成功
当Primary机器的keepalived服务恢复启动后,VIP资源又会强制夺回来(可以查看/var/log/message系统日志)
并且Primary还会再次变为DRBD的主节点
13.2 关闭Primary主机的nfs服务。根据监控脚本,会主动去启动nfs,只要当启动失败时,才会强制由DRBD的主节点降为备份节点,并关闭keepalived。
从而跟上面流程一样实现故障转移
[root@primary keepalived]# systemctl stop nfs-server //停止nfs服务[root@primary keepalived]# ps -ef |grep nfs-serverroot 4367 1235 0 13:22 pts/0 00:00:00 grep --color=auto nfs-server[root@primary keepalived]# ps -ef |grep nfs //keepalived会检测到nfs_chk脚本,会自动启动nfs服务root 4328 2 0 13:22 ? 00:00:00 [nfsd4_callbacks]root 4332 2 0 13:22 ? 00:00:00 [nfsd]root 4333 2 0 13:22 ? 00:00:00 [nfsd]root 4334 2 0 13:22 ? 00:00:00 [nfsd]root 4335 2 0 13:22 ? 00:00:00 [nfsd]root 4336 2 0 13:22 ? 00:00:00 [nfsd]root 4337 2 0 13:22 ? 00:00:00 [nfsd]root 4338 2 0 13:22 ? 00:00:00 [nfsd]root 4339 2 0 13:22 ? 00:00:00 [nfsd]root 4369 1235 0 13:22 pts/0 00:00:00 grep --color=auto nfs[root@primary keepalived]# drbdadm status //DRBD主节点并不会强制降级,除非nfs无法启动r0 role:Primarydisk:UpToDateSecondary role:Secondarypeer-disk:UpToDate
十四、总结
在上面的主从故障切换过程中,对于客户端来说,挂载NFS不影响使用,只是会有一点的延迟。这也验证了drbd提供的数据一致性功能(包括文件的打开和修改状态等),在客户端看来,整个切换过程就是"一次nfs重启"(主nfs停,备nfs启)。
