




目录
目录一、Kubernetes的调度1.1 RC,Deployment:全自动调度1.2 NodeSelector:定向调度1.2 NodeAffinity:节点亲和性调度(NodeSelector的升级版)1.3 PodAffinity:Pod的亲和性调度1.4 podAntiAffinity:pod的反亲和性1.5 Daemonset:每个节点来一份1.6 手动调度Pod1.7 Job:批处理调度1.8 Taints:避免Pod调度到特定的Node上1.9 Tolerations:允许Pod调度到有特定taints的Node上1.10 Node设置Cordon:设置警戒线,不可调度1.11 Node设置Drain二、调度的结果分析
一、Kubernetes的调度
scheduling:调度,就是为pod找到一个合适的Node
Pod中影响调度的主要属性字段:
资源调度依据pod.spec.containers.requests.memory|cpu
执行调度的调度器:pod.containers.spec.containers.schedulerName
调度的结果:pod.containers.spec.nodeName
高级调度策略:pod.containers.spec.nodeSelector|affinity|tolerations
Pod调度主要包括:调度的对象(待调度的Pod列表,可用的Node列表);调度算法(主机过滤,主机打分)
1.1 RC,Deployment:全自动调度
RC和Deployment的主要功能都是创建一个容器的多个副本,以及持续监控副本的数量,再集群内始终维持用户指定的副本数量。除了使用系统内置默认调度算法选择合适的Node进行调度外,还可以用NodeSelector或NodeAffinity来指定满足条件的Node进行调度
1.2 NodeSelector:定向调度
由于全自动调度,无法判断Pod被调度到那个节点。实际情况中,也可能需要将Pod指定到某些Node上,可以通过Node的标签Label和Pod的nodeSelector属性相匹配来完成此要求。
#首先给目标Node打上一个标签
[root@master ~]# kubectl label nodes node1 cs=chenshui
node/node1 labeled
#查看标签,可以看到node1上面以及打好了之前定义的标签
[root@master ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master.cs.com Ready master 5d1h v1.13.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=master.cs.com,node-role.kubernetes.io/master=
node1 Ready <none> 5d v1.13.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,cs=chenshui,disktypexx=ssd,kubernetes.io/hostname=node1
node2 Ready <none> 5d v1.13.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=node2
#第二种方法:修改资源定义来添加标签
[root@master ~]# kubectl edit nodes node1
......
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
cs: chenshui
disktypexx: ssd
kubernetes.io/hostname: node1
......
#然后,再Pod的定义中加上NodeSelector的设置。
[root@master ~]# kubectl run nginx --image=nginx --replicas=3 --dry-run -o yaml >nginx-deploy.yaml #生成一个nginx的3个副本,类型采用deployment
[root@master ~]# cat nginx-deploy.yaml #编辑添加nodeSelector
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
replicas: 3
selector:
matchLabels:
run: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
run: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
nodeSelector:
cs: chenshui
status: {}
[root@master ~]# kubectl apply -f nginx-deploy.yaml #应用yaml配置文件
deployment.apps/nginx created
#查看运行结果,看果然3个副本都再node1上面运行了。
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7cf9f46695-hqnnc 1/1 Running 0 31s 10.244.1.74 node1 <none> <none>
nginx-7cf9f46695-x62m2 1/1 Running 0 31s 10.244.1.75 node1 <none> <none>
nginx-7cf9f46695-xzwgk 1/1 Running 0 31s 10.244.1.73 node1 <none> <none>
[root@master ~]#
总结:
其实可以再不同的node上面定义不同的标签,再部署应用的时候根据应用需求来进行指定node范围的调度
如果多个node定义了相同的标签,则scheduler会根据调度算法再这组node中挑选可用的Node进行调度
如果集群中不包含这个标签的Node,则Pod无法进行调度。
1.2 NodeAffinity:节点亲和性调度(NodeSelector的升级版)
是替换NodeSelector的下一代调度策略。
可以使用操作符来进行灵活的调度:In(或),NotIN(不属于),Exists(存在一个条件),DoesNotExist(不存在),Gt(大于),Lt(小于)
亲和性调度策略:
#硬性过滤(必须安排到节点),支持指定多条件之间的逻辑或运算,排除不具备指定Label的Node
RequiredDuringSchedulingRequiredDuringExecution:类似NodeSelector,但再Node不满足条件时,系统将从该Node上移除之前调度上的Pod
RequiredDuringSchedulingIgnoredDuringExecution:与上面作用类似,区别再Node不满足条件时,系统不一定从该Node上移除之前调度上的Pod。
#官方定义
explain pod.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
如果不满足此字段指定的关联要求,则在调度时间,pod不会被调度到节点上。如果此字段指定的关联需求在某个时候将不再满足在pod执行期间(例如,由于更新),系统可能尝试,也可能不尝试最终将pod从节点上驱逐出去。最优先。
#软性评分(指定偏好调度程序,强制执行,但不保证),支持设置条件权重值。不具备指定label的node打低分,降低node被选中的几率
PreferredDuringSchedulingIgnoreDuringExecution:指定再满足调度条件的Node中,哪些Node应更优先的进行调度。同时再Node不满足条件时,系统不一定从该Node上移除之前调度上的Node
#官方定义
explain pod.spec.affinity.nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution
调度程序将倾向于将pod调度到满足由该字段指定的关联表达式,但它可以选择违反了其中一个或多个表达式。最受欢迎的节点是权值之和最大的节点,即每个满足所有条件的节点的权值之和调度需求(资源请求、调度期间的需求),通过遍历元素,如果节点匹配,则向和添加“权重”相应的matchExpressions;和最大的节点为最优先。
官网示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
#此yaml规则表示:只能将pod放在一个标签的节点上,该节点的健是kubernetes.io/e2e-az-name,值是e2e-az1或e2e-az2。此外,再满足该条件的节点中,具有健为another-node-label-key,值another-node-label-value应该优先考虑。
总结:
1.nodeSelector和nodeAffinity都指定了,则两个都必须满足才能调度
2.如果指定了多个nodeSelectorTerms与nodeAffinity类型,如果其中之一个nodeSelectorTerm满足,则可以将pod调度到节点
3.如果指定了多个matchExpressions与nodeSelectorTerms,只有当matchExpressions满足,则可以将pod调度到节点
4.wight字段再1-100之间。对于满足所有调度要求的每个节点,调度程序通过迭代该字段的元素,再节点匹配响应matchExprestions的情况下向和中添加权限来计算,然后将该分数与该节点的其他优先级函数的分数相结合,总分高的节点优先选择。
1.3 PodAffinity:Pod的亲和性调度
实现目标:让某些Pod分布在同一组Node上
与nodeAffinity的区别:
1.定义再pod.spec中,亲和与反亲和具有对称性
2.labelSelector的匹配对象是Pod
3.对node分组,依据label-key=topoloygKey,每个label-value取值为一组
4.硬性过滤规则,条件间只有逻辑与运算。
硬性过滤:排除不具备指定pod的node组
RequiredDuringSchedulingIgnoredDuringExecution
软性评分:不具备指定Pod的node组打低分,降低该组node被选中的几率
preferredDuringSchedulingIgnoredDuringExecution
与上面nodeAffinity的例子唯一区别就是字段变为:
pod.spec.affinity.podaffinity.preferredDuringSchedulingIgnoredDuringExecution
pod.spec.affinity.podaffinity.RequiredDuringSchedulingIgnoredDuringExecution
1.4 podAntiAffinity:pod的反亲和性
实现目标:避免某些Pod分布在同一组Node上
与Podanffinity的差异:
1.匹配过程相同,最终处理的调度结果时取反
2.AodAffinity中可调度节点,在PodAntiAffinity中为不可调度
3.AodAffinity中高分节点,在podAntiAffinity中为低分
1.5 Daemonset:每个节点来一份
实现目标,每个node上部署一个相同的pod(管理在集群中每个Node上仅运行的一份Pod副本实例)
这种用法特定场景下使用:通常用来部署集群中的agent,如网络插件
1.每个node上运行一个GlusterFS存储或者ceph存储的daemon进程
2.每个node上运行一个日志采集程序,例如fluentd或者logstach
3.每个node上运行一个健康程序,采集该node的运行性能数据。例如prometheus node exporter、collectd,new relic agent,或者Ganglia gmond等
用法与RC,deployment用法类似,除了使用系统内置调度算法,还可以在pod中定义使用nodeselector或者NodeAffinity来指定满足条件的node范围进行调度。(等价于deployment里面定义的反亲和性定义)
1.6 手动调度Pod
实现目标:调度器不工作时,临时救急;封装实现自定义调度器
创建时直接在pod.spec.containers.nodeName中定义节点名
1.7 Job:批处理调度
通过job来定义并启动一个批处理任务,批处理任务通常并行启动多个计算进程去处理一批工作项,处理完成后,整个批处理任务结束。
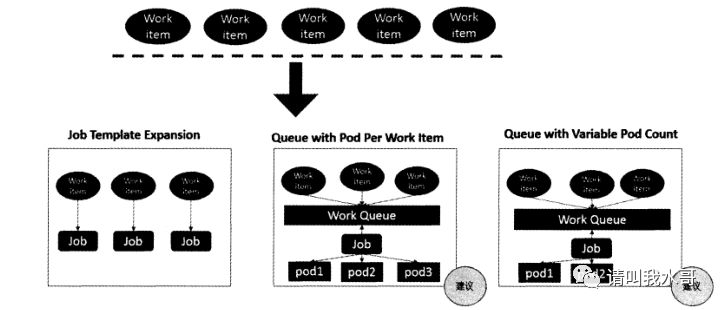
Job Template Expansion模式:一个Job对象对应一个待处理的work item,有几个work item就产生几个独立的Job。通常适合work item数量少,每个work item要处理比较大的场景。比如100GB文件作为一个work item,总共10个文件需要处理
批处理的模式
Queue with Pod Per Work Item模式:采用一个任务队列存放work item,一个Job对象作为消费者去完成这些work item,这种模式下,Job会启动N个Pod,每个Pod对应一个work item
Queue with Variable Pod Count模式:也是采用一个任务队列存放work item,一个Job对象作为消费者去完成这些work item。不同的是Job启动的Pod数量是可变的。
还有一种single Job wirh static work assignment模式,也是一个Job产生多个Pod模式。它采用程序静态方式分配任务项。而不是采用队列模式进行动态分配。
考虑到并行问题,job分为三种类型
1.Non-parallel Jobs:通常一个Job只启动一个Pod,则除非Pod异常,才会重启该Pod,一旦Pod正常结束,Job将结束
2.Parallel Jobs With a fixed comopletion count:并行job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常借宿的Pod数量达到此参数设定的值后,Job结束。次问,Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job来处理work Item
3.Parallel Jobs with a work queue:任务队列方式的并行Job需要一个独立的Queue,work item都在一个Queue中存放,不能设置Job的.spec.completions参数。job有以下特性:
每个pod都能独立判断和绝当是否还有任务需要处理
如果某个Pod正常结束,则Job不会再启动新的Pod
如果一个Pod成功结束,则此时应该不存在其他Pod还在干活的情况,它们应该都处于即将结束、退出的状态
如果所有Pod都结束了,且至少一个Pod成功结束,则整个Job算是成功结束
1.8 Taints:避免Pod调度到特定的Node上
用法:预留特殊节点作特殊用途
带effect的特殊label,对Pod有排斥性
1.硬性排斥NoSchedule
2.软性排斥PreferNoSchedule
系统创建的taint附带时间戳
effect为NoExecute
便于触发对Pod的超时驱逐
字段:Node.spec.taints.effect|key|timeAdded|value
#给node添加taint
[root@master ~]# kubectl taint node node1 foo=bar:NoSchedule
#删除taint
[root@master ~]# kubectl taint node node1 foo:NoSchedule-
1.9 Tolerations:允许Pod调度到有特定taints的Node上
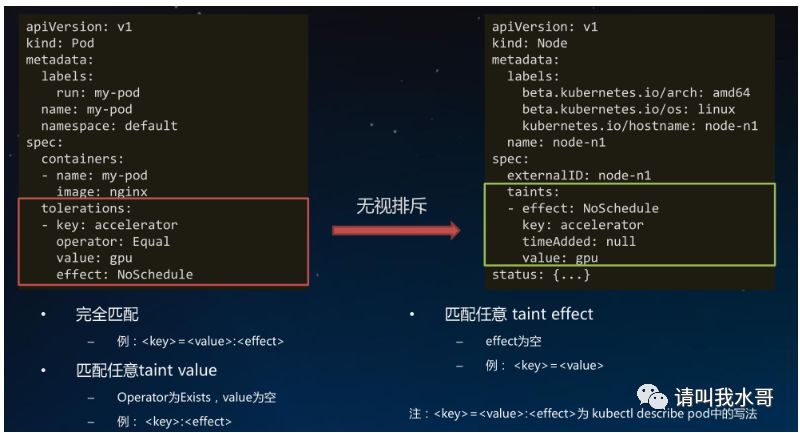
1.10 Node设置Cordon:设置警戒线,不可调度
主要用于节点维护。如果一个Node被标记为conrdon,新创建的pod不会调度到此node上。已经调度上去的还在允许,需要被删除让其重新生成。
#设置警戒线cordon。可以看到node2调度被关闭
[root@master ~]# kubectl cordon node2
node/node2 cordoned
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master.cs.com Ready master 5d4h v1.13.3
node1 Ready <none> 5d4h v1.13.3
node2 Ready,SchedulingDisabled <none> 5d4h v1.13.3
#删除
[root@master ~]# kubectl uncordon node2
node/node2 uncordoned
1.11 Node设置Drain
类似vsphere的维护模式。如果一个node被设置drain,则此节点不在被调度pod,且此节点上已经运行的pod会驱逐到其他节点
所以可以看出这个节点包括:cordon设置警戒线和evicted驱逐策略。
#可以看到如果不加--ignore-daemonsets,会报错不允许迁移含有DaemonSet类型的pod,如果加上这个参数忽略。可以看到这些pod已经迁移到其他节点
[root@master ~]# kubectl drain node1 --ignore-daemonsets
node/node1 cordoned
WARNING: Ignoring DaemonSet-managed pods: kube-flannel-ds-amd64-v5vlb, kube-proxy-wp5zq
pod/frontend-7b77f55448-mblx4 evicted
pod/frontend-rc47d evicted
pod/frontend-9rznn evicted
pod/redis-slave-6t2k7 evicted
pod/redis-slave-bjcd6 evicted
node/node1
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
frontend-4pjdm 1/1 Running 1 14h 10.244.2.52 node2 <none> <none>
frontend-7b77f55448-424lz 1/1 Running 0 2m18s 10.244.2.54 node2 <none> <none>
frontend-gqnmp 1/1 Running 0 2m18s 10.244.2.57 node2 <none> <none>
frontend-jmbng 1/1 Running 0 2m18s 10.244.2.56 node2 <none> <none>
redis-master-lm486 1/1 Running 2 32h 10.244.2.53 node2 <none> <none>
redis-slave-2wshg 1/1 Running 0 2m18s 10.244.2.55 node2 <none> <none>
redis-slave-hs9sj 1/1 Running 0 2m18s 10.244.2.58 node2 <none> <none>
#删除。因为它用到cordon。所以删除也是使用这个删除
[root@master ~]# kubectl uncordon node1
node/node1 uncordoned
二、调度的结果分析
查看调度结果
[root@master ~]# kubectl get node1 -o wide
查看调度失败的原因
[root@master ~]# kubectl describe pod frontend-gqnmp
