




定义
Spring Batch是一个轻量级框架,用于在开发企业应用程序中批处理应用程序。
特点
灵活性 - Spring批处理应用程序非常灵活。只需更改XML文件即可更改应用程序中的处理顺序。
可维护性 - Spring批量应用程序易于维护。Spring Batch作业包括步骤,每个步骤都可以进行分离,测试和更新,而不影响其他步骤。
可伸缩性 - 使用分区技术,可以缩放Spring Batch应用程序。这些技术可以让你 -
并行执行作业的步骤。
并行执行单个线程。
可靠性 - 如果发生任何故障,可以通过拆除步骤来从停止的地方重新开始作业。
支持多种文件格式 - Spring Batch为XML,Flat文件,CSV,MYSQL,Hibernate,JDBC,Mongo,Neo4j等大量写入器和读取器提供支持。
多种启动作业的方式 - 可以使用Web应用程序,Java程序,命令行等来启动Spring Batch作业。
使用场景
典型的批处理程序通常从数据库,文件或队列中读取大量记录,以某种方式处理数据,然后以修改的形式写回数据。Spring Batch自动执行此基本批处理迭代,提供处理类似事务的功能,通常在脱机环境中处理,无需任何用户交互。批处理作业是大多数IT项目的一部分,Spring Batch是唯一提供强大的企业级解决方案的开源框架。
业务场景
定期提交批处理
并发批处理:并行处理作业
分阶段的企业消息驱动处理
大规模并行批处理
失败后手动或预定重启
依赖步骤的顺序处理(扩展到工作流驱动的批处理)
部分处理:跳过记录(例如回滚)
整批交易:适用于批量较小或现有存储过程/脚本的情况
架构图
分层结构
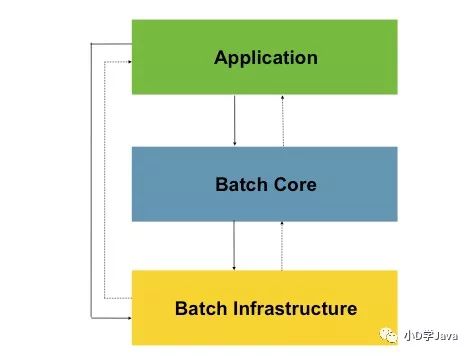
Application包含开发人员使用Spring Batch编写的所有批处理作业和自定义代码。
Batch Core包含启动和控制批处理作业所需的核心运行时类。它包括诸如一个
JobLauncher
,Job
和Step
实施方式。Batch Infrastructure
包含常见的读取器和编写器,以及诸多服务,如RetryTemplate
.
架构
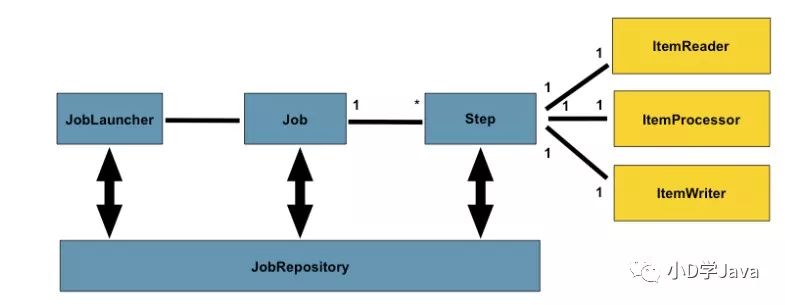
<!-- 一个对应上图的配置文件--><beans:beans xmlns="http://www.springframework.org/schema/batch"xmlns:beans="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/batchhttp://www.springframework.org/schema/batch/spring-batch-2.2.xsd"><!--定义一个job--><job id="ioSampleJob"><!--定义一个步骤--><step id="step1"><!--定义一个数据流--><tasklet><!--定义读写器以及每次批量读取的数据量--><chunk reader="itemReader" writer="itemWriter" commit-interval="2"/></tasklet></step></job></beans:beans>
Job
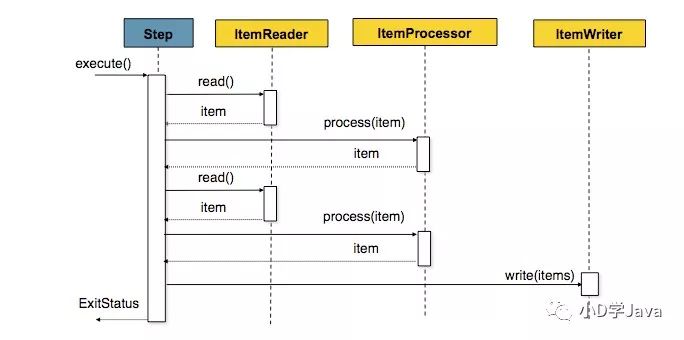
<!--jobRepository用于定期存储每批次的数据--><job id = “sampleJob” job-repository = “jobRepository” ><step id = “step1” ><!--PlatformTransactionManager提供事务处理--><tasklet transaction-manager = “transactionManager” ><chunk reader = “itemReader” writer = “itemWriter” commit-interval = “ 10“ /></ tasklet></ step></ job>常见的读写器
常见的读写器
| 读取器 | 目的 |
|---|---|
FlatFIleItemReader | 从文件中读取数据。 |
StaxEventItemReader | 从XML文件读取数据。 |
JDBCPagingItemReader | 从关系数据库中读取数据。 |
| 写入器 | 目的 |
|---|---|
FlatFIleItemWriter | 将数据写入文件。 |
StaxEventItemWriter | 将数据写入XML文件 |
JDBCPagingItemWriter | 将数据写入关系数据库数据库。 |
代码
启动
public abstract class AbstractReconFileHandler {@AutowiredPropertyHolder propertyHolder;@AutowiredJobLauncher jobLauncher;//子类回覆盖这个job@AutowiredJob reconJob;//启动job流程public ExitStatus handle(Date converDate, int reconType, boolean allowReconAgain) {JobParameters jobParams = new JobParameters(this.buildParameterMap(converDate,reconType));//启动jobJobExecution execution = null;try {execution = jobLauncher.run(reconJob, jobParams);return execution.getExitStatus();} catch (JobExecutionException e) {logger.error("reconJob failed.", e);return ExitStatus.FAILED;}}//某个子类的构建参数方法@Overrideprotected Map<String, JobParameter> buildParameterMap(Date converDate, int reconType) {//父类定义了通用的参数并返回MapMap<String, JobParameter> jobParameterMap = super.buildParameterMap(converDate, reconType);jobParameterMap.put(JobParamNames.BANK_FILE_NAME, new JobParameter(this.getRarBankFileName(converDate)));jobParameterMap.put("unrarBankFile", new JobParameter(this.getUnrarBankReconFileName(converDate)));jobParameterMap.put("clear_channel", new JobParameter(this.clearChannel));String autoParentPath = jobParameterMap.get(JobParamNames.AUTO_FTP_PATH).toString();String autoPath = autoParentPath + "/" + DateStyle.YYYYMMDD.coverDate2Str(converDate);jobParameterMap.put(JobParamNames.AUTO_FTP_PATH, new JobParameter(autoPath));//统计对账总数的键jobParameterMap.put(JobParamNames.PAY_ITEM_TOTAL_KEY, new JobParameter(ClassUtils.getShortName(PayItemWriter.class) + ".written"));jobParameterMap.put(JobParamNames.REFUND_ITEM_TOTAL_KEY, new JobParameter(ClassUtils.getShortName(RefundItemWriter.class) + ".written"));//最终需要备份的因为对账文件路径jobParameterMap.put(JobParamNames.PAY_BANK_FILE_PATH, new JobParameter(this.getLocalTargetPath() + File.separator + this.getBankPayReconFileName(converDate)));jobParameterMap.put(JobParamNames.REFUND_BANK_FILE_PATH, new JobParameter(this.getLocalTargetPath() + File.separator + this.getBankRefundReconFileName(converDate)));return jobParameterMap;}}
配置文件
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:batch="http://www.springframework.org/schema/batch" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/batchhttp://www.springframework.org/schema/batch/spring-batch-2.2.xsdhttp://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.2.xsd"><bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean" ></bean><bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher"><property name="jobRepository" ref="jobRepository" /></bean><bean id="decider" class="###.batch.common.decider.ReconDecider"></bean><bean id="defaultAutoReconDownloadTasklet" class="###.batch.common.tasklet.AutoDownloadTasklet" scope="step"></bean><bean id="defaultDownloadBankFileStepListener" class="###.batch.common.listener.DownloadStepListener" scope="step"></bean><!--start upopReconJob--><bean id="unionCompositeItemWriterSupportor" class="###.batch.unionPay.supportor.UnionCompositeItemWriterSupportor"></bean><bean id="upopCompositeItemWriterSupportor" class="###.batch.unionPay.supportor.UpopEbankCompositeItemWriterSupportor"></bean><bean id="unionItemProcessor" class="###.batch.unionPay.processor.UnionPayItemProcessor"></bean><bean id="unionPayFieldSetMapper" class="###.batch.unionPay.field.mapping.UnionPayFieldSetMapper"></bean><!--通用的文件读取reader--><bean id="unionPayItemReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"><!--指明文件位置,通过jobExecutionContext来声明--><property name="resource" value="file://#{jobExecutionContext[localBankFilePath]}"></property><property name="lineMapper"><!--指令默认的行处理类--><bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"><property name="lineTokenizer"><!--常见的lineTokenizer还有DelimitedLineTokenizer和RegexLineTokenizer当使用DelimitedLineTokenizer时需指定分隔符delimiter的值,如<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"><property name="delimiter" value="|"></property></bean>--><bean class="org.springframework.batch.item.file.transform.FixedLengthTokenizer"><!--读取的字段值--><property name="columns" value="107-113, 32-42, 25-31, 63-75, 324-364, 128-143"></property><!--读取的字段对应的值名字,感觉这个属性没啥用,属性转义在fieldSetMapper中设置值了--><property name="names" value="txnType, txnTime, sysTraceAuditNo, txnAmount, orderId, merchantNo"></property><!--是否需严格匹配上面指定的栏位,false的情况下不足回补齐--><property name="strict" value="false"></property></bean></property><!--指定读取数据处理的mapper--><property name="fieldSetMapper" ref="unionPayFieldSetMapper"></property></bean></property></bean><bean id="upopItemWriter" class="###.batch.unionPay.writer.UpopCompositeItemWriter" scope="step"></bean><bean id="unionPayDownloadStepListener" class="###.batch.unionPay.listener.UnionPayDownloadStepListener" scope="step"></bean><bean id="upopReconFileStepListener" class="###.batch.unionPay.listener.UpopReconFileStepListener" scope="step"></bean><bean id="uploadReconFileTasklet" scope="step" class="###.batch.common.tasklet.UploadReconFileTasklet" ></bean><bean id="defaultUploadReconFileStepListener" class="###.batch.common.listener.UploadStepListener" scope="step"></bean><bean id="reconJobListener" class="###.batch.common.listener.ReconJobExecutionListener"></bean><!--开始定义job--><batch:job id="unionReconJob" ><!--根据decider的返回决定job的流程方向--><!--decide whether menual or auto recon--><batch:decision id="unionDecision" decider="decider"><batch:next on="MENUAL" to="unionStep1_menual"></batch:next><batch:next on="AUTO" to="unionStep1_auto"></batch:next></batch:decision><!--流程一,选项A--><!--unionStep1_menual download bank file(menaul recon)--><batch:step id="unionStep1_menual"><batch:tasklet ref="defaultMenaulReconDownloadTasklet"></batch:tasklet><batch:end on="FAILED" exit-code="UPOP-RECON-FAILED"></batch:end><batch:next on="*" to="unionStep2"></batch:next><batch:listeners><batch:listener ref="defaultDownloadBankFileStepListener" after-step-method="afterStep" before-step-method="beforeStep"></batch:listener><batch:listener ref="unionPayDownloadStepListener" before-step-method="beforeStep" after-step-method="afterStep"></batch:listener></batch:listeners></batch:step><!--流程一,选项B--><!--unionStep1_auto download bank file(auto recon)--><batch:step id="unionStep1_auto"><!--执行流程,自定义的一个流程,此流程是一个ftp下载文件--><batch:tasklet ref="defaultAutoReconDownloadTasklet"></batch:tasklet><!--返回码等于FAILED时直接结束job--><batch:end on="FAILED" exit-code="UPOP-RECON-FAILED"></batch:end><!--其它返回码直接跳到步骤2--><batch:next on="*" to="unionStep2"></batch:next><!--监听器,提供了针对此step处理前后的拦截处理--><batch:listeners><batch:listener ref="defaultDownloadBankFileStepListener" after-step-method="afterStep" before-step-method="beforeStep"></batch:listener><batch:listener ref="unionPayDownloadStepListener" before-step-method="beforeStep" after-step-method="afterStep"></batch:listener></batch:listeners></batch:step><!--step2 process bank file--><batch:step id="unionStep2"><!--声明一个tasklet--><batch:tasklet><!--声明一个chunk,包含读取,转换,写入--><batch:chunk reader="unionPayItemReader" writer="upopItemWriter" processor="unionItemProcessor" commit-interval="100"></batch:chunk></batch:tasklet><!--返回码为Failed时结束并返回`CCB-RECON-FAILED`返回码--><batch:end on="FAILED" exit-code="CCB-RECON-FAILED"></batch:end><batch:next on="*" to="unionStep3"></batch:next><batch:listeners><batch:listener ref="defaultConverReconFileStepListener" after-step-method="afterStep" before-step-method="beforeStep"></batch:listener><batch:listener ref="upopReconFileStepListener" after-step-method="afterStep" before-step-method="beforeStep"></batch:listener></batch:listeners></batch:step><!--step3.upload recond file--><batch:step id="unionStep3"><!--上传文件到sftp的微进程--><batch:tasklet ref="uploadReconFileTasklet"></batch:tasklet><batch:listeners><!--执行记录操作更新的数据库操作--><batch:listener ref="defaultUploadReconFileStepListener" after-step-method="afterStep" before-step-method="beforeStep"></batch:listener></batch:listeners></batch:step><batch:listeners><batch:listener ref="reconJobListener" after-job-method="afterJob" before-job-method="beforeJob"></batch:listener></batch:listeners></batch:job><!--end UnionPayReconJob--></beans>
Decision配置
//根据入参决定走哪个分支的steppublic class ReconDecider implements JobExecutionDecider {public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {String reconType = jobExecution.getJobParameters().getString(JobParamNames.RECON_TYPE);if (ReconType.AUTO.getValue().equals(reconType)) {jobExecution.getExecutionContext().putString("reconType", ReconType.AUTO.getValue());return new FlowExecutionStatus(ReconType.AUTO.getName());}else {jobExecution.getExecutionContext().putString("reconType", ReconType.MENUAL.getValue());return new FlowExecutionStatus(ReconType.MENUAL.getName());}}}
简单只负责下载的Tasklet
public class AutoDownloadTasklet implements Tasklet {private static final Logger logger = LoggerFactory.getLogger(AutoDownloadTasklet.class);@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception{JobParameters jobParams = chunkContext.getStepContext().getStepExecution().getJobParameters();//根据JobParameters获取启动时传递的数据String ftpSrcHost = jobParams.getString(JobParamNames.AUTO_FTP_HOST);String ftpSrcUserName = jobParams.getString(JobParamNames.AUTO_FTP_USER_NAME);...try {//此tasklet只下载文件logger.info("DownloadAutoBankFile, autoFtpPath:{}, bankFileNameList:{}", autoFtpPath, bankFileNameList);List<String> localBankFilePaths = DownloadBankReconFile.downloadAutoBankFile(ftpInfo, autoFtpPath, localSourcePath, bankFileNameList);} catch (Exception e) {throw e;}return RepeatStatus.FINISHED;}}
Step的Listener示例
public class DownloadStepListener implements StepExecutionListener {@Overridepublic void beforeStep(StepExecution stepExecution) {//渠道编号String channelId = stepExecution.getJobExecution().getJobParameters().getString(JobParamNames.CHANNEL_ID);String convertDate = stepExecution.getJobExecution().getJobParameters().getString(JobParamNames.CONVER_DATE_STR);//把recordId放入到JobExecutionContextstepExecution.getJobExecution().getExecutionContext().putLong(JobParamNames.RECORD_ID, record.getId());//省略文件操作代码}@Overridepublic ExitStatus afterStep(StepExecution stepExecution) {//判断step的状态if (stepExecution.getExitStatus().getExitCode().equals(ExitStatus.FAILED.getExitCode())) {return ExitStatus.FAILED;}//从JobExecutionContext读取long recordId = stepExecution.getJobExecution().getExecutionContext().getLong(JobParamNames.RECORD_ID);//省略数据库更新recordreturn ExitStatus.COMPLETED;}}
Chunk中配置的FieldSetMapper
//将读取的数据映射为对象返回public class UnionPayFieldSetMapper implements FieldSetMapper<UnionPayReconItem> {@Overridepublic UnionPayReconItem mapFieldSet(FieldSet fieldSet) throws BindException {UnionPayReconItem item = new UnionPayReconItem();item.setTnxType(fieldSet.readString(0));...item.setMerchantNo(fieldSet.readString(5));return item;}}
Chunk中配置的Processor
//将Reader中的数据经过处理后转换为另一个对象public class UnionPayItemProcessor implements ItemProcessor<UnionPayReconItem, UpopRecondItem> {@Overridepublic UpopRecondItem process(UnionPayReconItem item) throws Exception {//校验交易流水号if (StringUtils.isEmpty(item.getOrderId())) {logger.warn("#UNION-PAY_DIRTY_DATA#订单号数据错误, orderId={}, {}", item.getOrderId(), item);return null;}//转换对象UpopRecondItem vpalRecondItem = new UpopRecondItem();vpalRecondItem.setUasNo(item.getOrderId());vpalRecondItem.setTransAmount(item.getTnxAmount());vpalRecondItem.setMerchantNo(item.getMerchantNo());return vpalRecondItem;}}
Chunk中配置的Writer
/*** 自定义一个综合的ItemWriter,其本质还是使用FlatFileItemWriter来写文件一般情况下直接定义一个类继承FlatFileItemWriter即可,在xml配置可以如下配置,<bean id="epccSingleBatchItemWriter" class="###.batch.epcc.writer.EPCCSingleBatchWriter" scope="step"><property name="resource" value="file://#{jobParameters[localTargetPath]}"></property><property name="lineSeparator" value=""></property><property name="encoding" value="utf-8"></property><property name="lineAggregator" ref="epccSingleBatchLineAggregator"></property></bean>*/public class UpopCompositeItemWriter extends CompositeItemWriter<UpopRecondItem> {private Map<String,ItemWriter<UpopRecondItem>> itemWriterMap;@Value("#{jobParameters['localSourcePath']}")private String localSourcePath;@Value("#{jobParameters['converDateStr']}")private String converDateStr;@Value("#{jobParameters['clear_channel']}")private String clearChannel;@Overridepublic void write(List<? extends UpopRecondItem> items) throws Exception {//这里的主要目的是有多个的Writer来写多个文件,这里根据渠道,支付类型(支付,退款)一共分为4个WriterMap<String,List<UpopRecondItem>> mapItem=new HashMap<>();...//写入数据for(Map.Entry<String,ItemWriter<UpopRecondItem> > entry : this.getItemWriterMap().entrySet()){String channelId=entry.getKey();ItemWriter<UpopRecondItem> writer=entry.getValue();List<UpopRecondItem> list = mapItem.get(channelId);if(CollectionUtils.isNotEmpty(list)){//使用writer.write(list);}}}//初始化后构造UpopItemWriter信息@Overridepublic void afterPropertiesSet() throws Exception {List<ItemWriter<? super UpopRecondItem>>writers=new ArrayList<>();Map<String,ItemWriter<UpopRecondItem>> itemWriterMap=new HashMap<>();String[] channels = this.getChanneId(clearChannel);for(int i=0;i<channels.length;i++){//支付UpopItemWriter writerPay = getUpopRecordItemFlatFileItemWriter(channels[i]+"_1");itemWriterMap.put(channels[i]+"_"+ ReconSysTxnType.PAYMENT.getValue(),writerPay);writers.add(writerPay);//退款UpopItemWriter writerRefund = getUpopRecordItemFlatFileItemWriter(channels[i]+"_2");itemWriterMap.put(channels[i]+"_"+ ReconSysTxnType.REFUND.getValue(),writerRefund);writers.add(writerRefund);}this.setDelegates(writers);this.setItemWriterMap(itemWriterMap);}private String[] getChanneId(String clearChannel) {return clearChannel.split(",");}private UpopItemWriter getUpopRecordItemFlatFileItemWriter(String channel) {UpopItemWriter writer=new UpopItemWriter(channel);writer.setEncoding("utf-8");Resource resource=new FileSystemResource(String.format("%s/%s_%s.txt",localSourcePath,channel,converDateStr));writer.setResource(resource);//声明一个将对象转为为文本的行聚合处理器writer.setLineAggregator(new UpopReconLineAggregator());writer.setLineSeparator("");return writer;}}
//UpopItemWriter继承FlatFileItemWriterpublic class UpopItemWriter extends FlatFileItemWriter<UpopRecondItem> {public UpopItemWriter(String name){this.setExecutionContextName(name);}}//行处理器public class UpopReconLineAggregator implements LineAggregator<UpopRecondItem> {@Overridepublic String aggregate(UpopRecondItem item) {if (item == null) {return "";}String newLine = System.getProperty("line.separator").toString();StringBuilder sb = new StringBuilder("");sb.append(item.getTransType()).append(Constant.SEPERATOR);sb.append(item.getUasNo()).append(Constant.SEPERATOR);sb.append(item.getUsaOriginNo()).append(newLine);return sb.toString();}}
Job的监听器
//执行Job前后的拦截操作public class ReconJobExecutionListener implements JobExecutionListener {@Overridepublic void beforeJob(JobExecution jobExecution) {logger.info("---- jobExecutionId:{}, BatchStatus:{} ---- ", jobExecution.getJobParameters().getString(JobParamNames.JOB_EXECUTION_ID), jobExecution.getStatus());}@Overridepublic void afterJob(JobExecution jobExecution) {logger.info("---- jobExecutionId:{}, BatchStatus:{} ---- ", jobExecution.getJobParameters().getString(JobParamNames.JOB_EXECUTION_ID), jobExecution.getStatus());}}
参考文档
官方文档(https://docs.spring.io/spring-batch/trunk/reference/htmlsingle/)
中文翻译版(https://www.bookstack.cn/read/SpringBatchReferenceCN/README.md)
