






分享嘉宾:何昱晨 小米 高级软件工程师
编辑整理:张德通
出品平台:DataFunTalk
导读:今天和大家分享一下Pegasus的设计实现和开源之路。分以下四个部分:
Pegasus基本介绍
Pegasus新特性
Pegasus生态
Pegasus社区建设
1. 背景
在目前的大数据生态中,我们已经有许多成熟的存储系统,例如 Redis、HBase,但这些存储系统往往不能解决所有的问题。比如说 Redis,它有很强的性能,但不支持强一致性,并且由于数据存储在内存中,成本较高;HBase 虽然支持强一致性,但读写路径过长,加上 Java 语言的 GC 问题,会造成较严重的长尾延迟。为了解决以上痛点,Pegasus 诞生了。
2. 系统架构
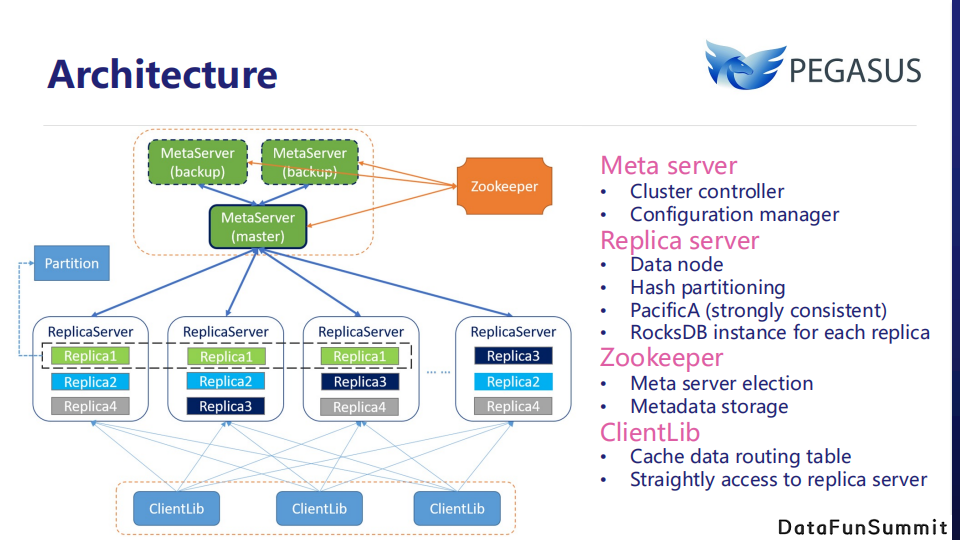
在Pegasus系统中,
Meta server是管理节点,负责元数据管理、配置变更,并参与一致性协议选主流程。
Replica server 是数据节点,用户数据将以哈希散列的方式分布在各个replica server,通过对应的 RocksDB 实例完成落盘。Pegasus 采用 PacificA 协议保证副本间数据的强一致性。
Zookeeper 用于管理节点的选主与集群元信息的存储。
Pegasus 客户端在第一次访问集群时会访问 meta server 获取路由表,然后直接与 replica server交互。
Pegasus采用hashkey、sortkey的二级索引Key-Value存储数据模型。hashkey作为一级索引用于hash分片,每个hashkey下可拥有多个sortkey,sortkey以字典序存储。相同hashkey的数据存储在同一分片中,这种数据模型设计可以使得我们针对同一hashkey下的数据支持原子批量读写。
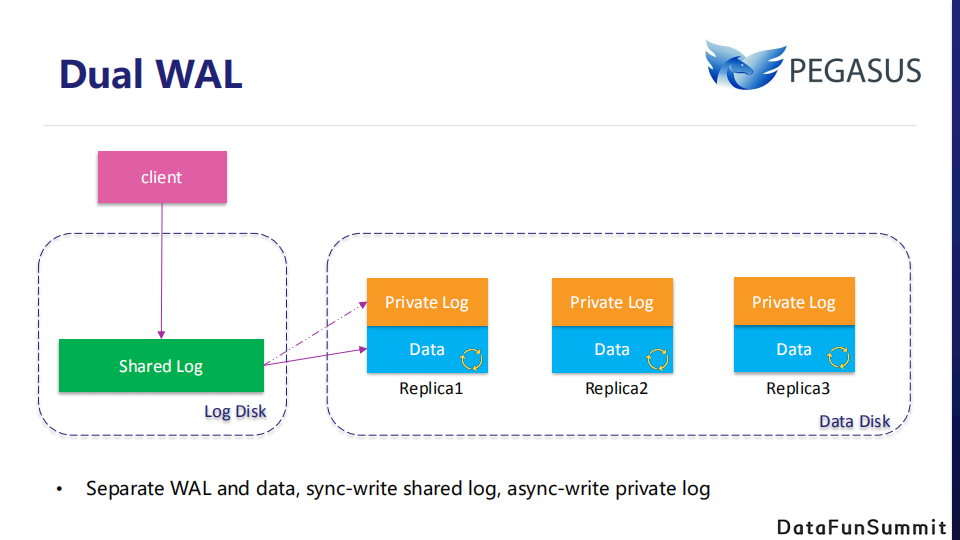
Pegasus采用了特殊的双WAL写入方案来保证低延迟写入。在传统的解决方案中,数据和WAL被部署在相同的磁盘,客户端写数据时,会先写到 WAL 中,再写入存储引擎,而数据盘的Compaction操作以及其他大量的随机读写,会增加 IO 负载,严重影响到 WAL 同步写的性能,进而影响写性能。
在实践中,部署Replica的机器往往有多块磁盘,Pegasus使用其中一个磁盘专门存储 WAL,以避免数据盘的高负载带来的写入抖动。但是,如果所有分片的WAL都存储在一起,则将花费大量时间进行负载均衡或故障恢复。所以,Pegasus选择了双WAL架构,写请求会先同步写入shared log作为WAL,再同步写入RocksDB实例,同时异步写入各个分片的private log以用于负载均衡和故障恢复。这种设计在实践中能有效减轻长尾延迟并避免负载均衡及故障恢复的低效率问题。
3. 性能测试
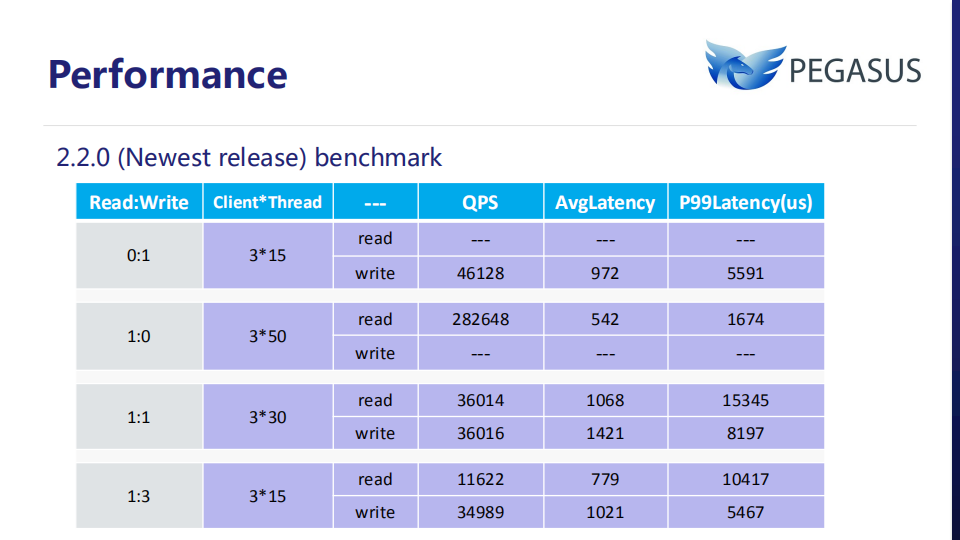
以上是最新发行版2.2.0在YCSB下的测试结果。
在基本的介绍之后,我们将介绍Pegasus的一些新特性。
1. 热备份
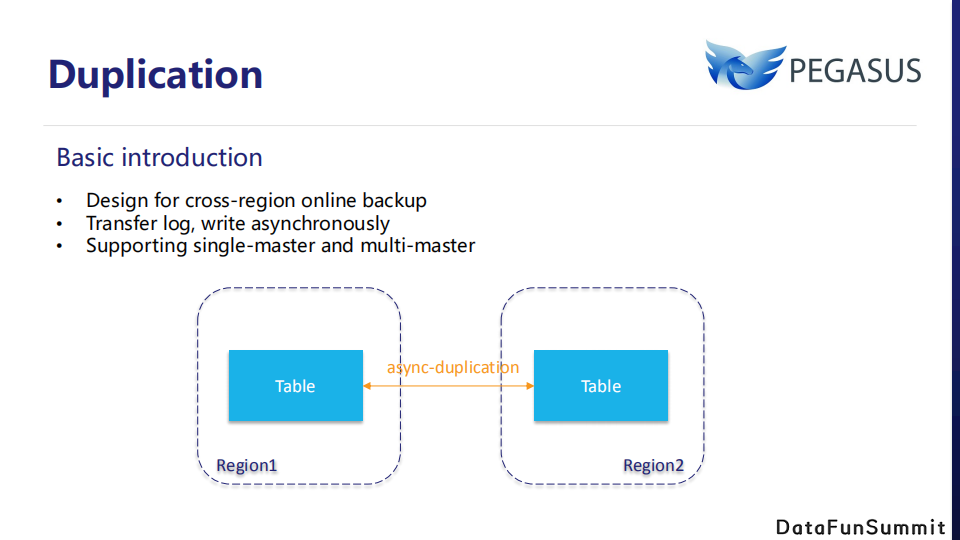
首先是热备份功能,它用于跨机房在线备份。其设计原理是:源集群通过重放写请求日志,把数据异步传输到远端目标集群。热备份支持单主和多主两种模式,基于这个功能我们有了更多拓展场景。
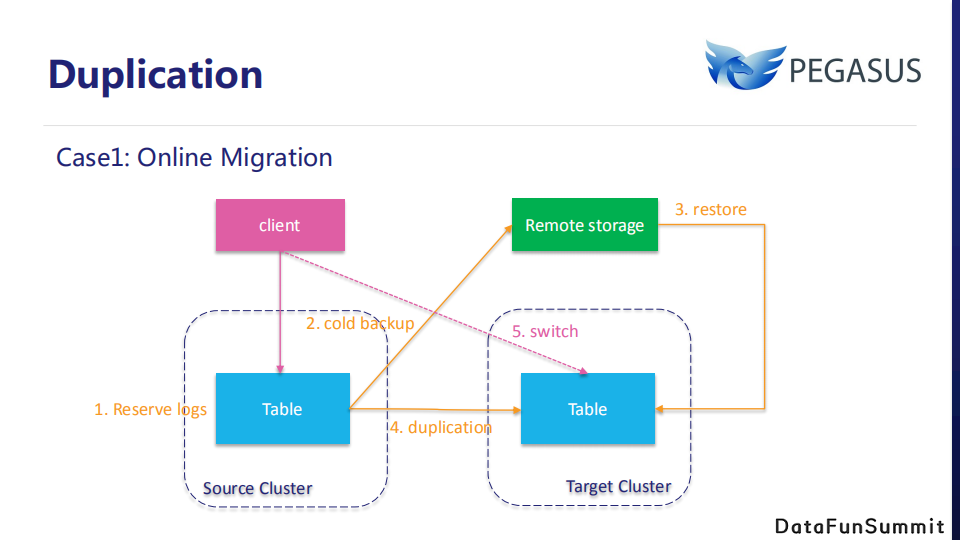
热备份的一个简单应用是在线迁移。当用户跨集群迁移数据,并希望在迁移过程中不停止客户端读写时,我们可以结合使用冷备份和热备份来解决。首先创建热备份以让源集群表保留其日志快照点,并通过冷备份将全量数据备份到 HDFS 等远程存储,然后目标集群从HDFS等远程存储恢复数据。当目标集群恢复该备份快照后,下一步就是从源到目标开始热备份,待目标区域与源区域保持相同的数据,随后客户端就可以切换到目标表。
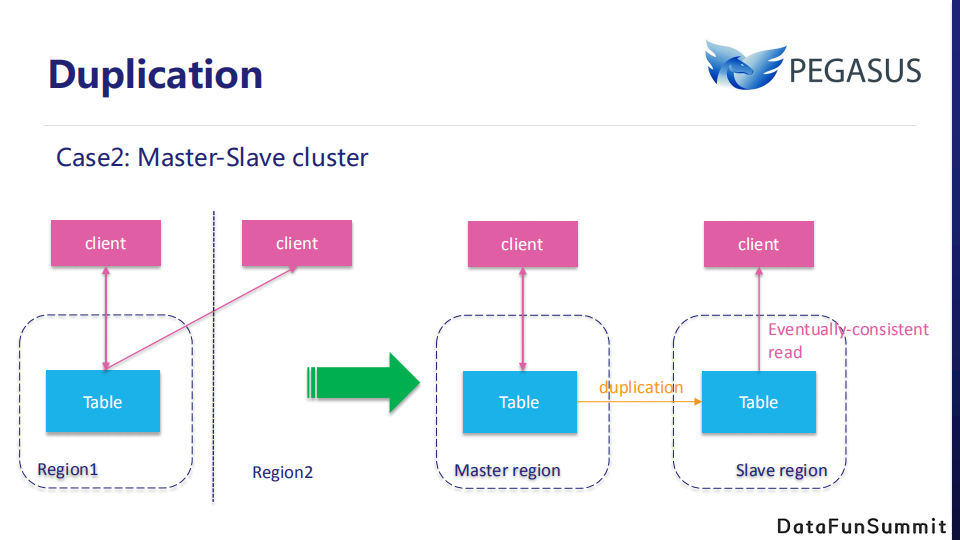
这是另一个经典的用户案例,双机房主从模式。在region1客户端读取数据和写入数据,在region2客户端只读取数据。为了避免跨区域读取,我们将部署一个主从集群。在主集群中,Client将写入和读取数据,然后通过热备份传输数据。部署在从集群域的客户端可以在本地读取数据,这种读取可以保证最终一致性。
未来,我们会做更多的事情来增强这个功能。比如,在实践中支持master-master模式,我们现在大多部署master-slave模式来实现多集群热备份。热备份还可以支持远程容灾,客户端通常从master机房读/写数据,如果master region出现严重错误或完全不可用,client可以自动切换到slave机房。此外,除了Pegasus集群之间的热备份之外,未来,我们可能还会提供CDC,将数据传输到其他系统,例如ES或 RabbitMQ。
2. Bulk Load
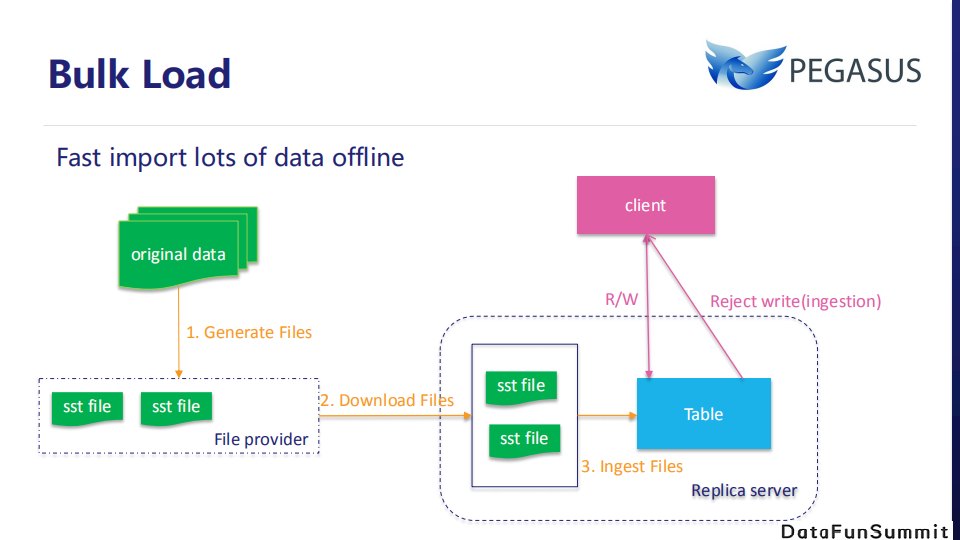
Bulk Load用于快速导入大量数据。由于其本质是数据文件的批量加载,相较于传统的逐条写入导入方式能够大幅提高数据灌入速度。首先,用户可以通过Pegasus-Spark将原始数据转换为Pegasus能够识别的SST文件,存储到远程文件系统。生成文件后Pegasus服务端将这些文件下载到Replica Server上,然后将它们快速加载到Pegasus表中。
3. Access Control
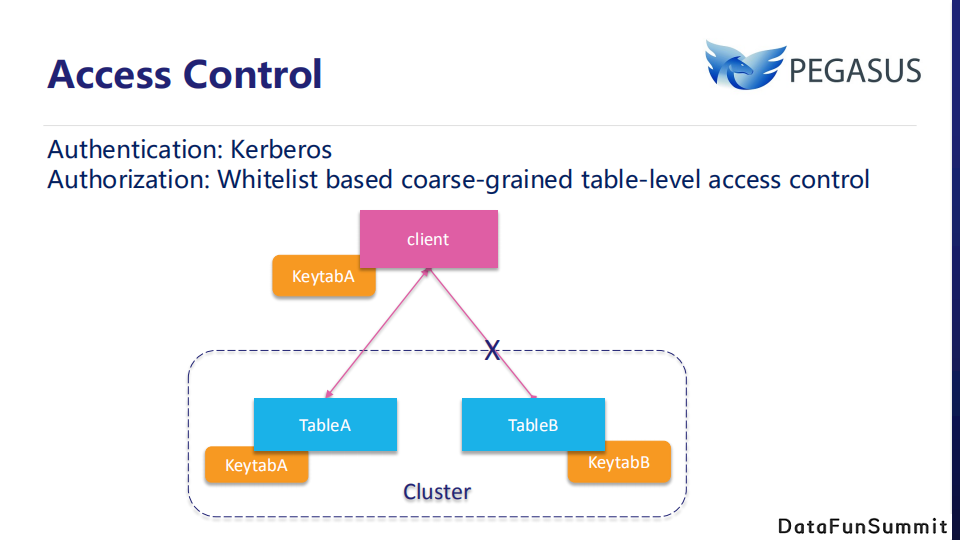
与Hadoop系统一样,我们使用Kerberos进行身份验证。当集群打开访问控制时,客户端使用 keytab 文件完成鉴权。Pegasus现在使用基于表级访问控制的白名单,在图示的这个例子中,客户端只能访问表A,不能访问表B。
4. Partition Split
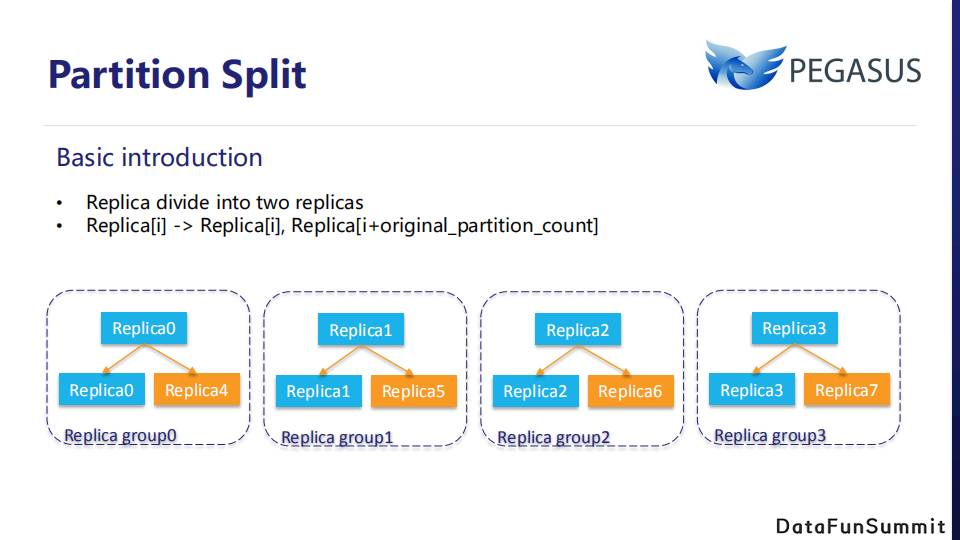
最后,我们来介绍一下分区分裂Partition Split。Pegasus使用hash分区,很难实现分区的任意拆分,我们的解决方案仅支持分区倍增。如图所示,如果表的原始分区数为4,则新分区数为8。分区0将拆分为分区0和分区4,分区1将拆分为分区1和分区5。为方便起见,我们称旧分区为父分区,新分区为子分区。
分裂开始时,第一阶段是从父分区异步复制数据给子分区,直到他们拥有相同的数据。在这个阶段客户端只知道父分区,所有请求都将发送给父分区。当子分区同步完父分区的所有数据后,主父分区将在MetaServer上注册子分区,暂时拒绝客户端读写。注册成功后,分区分裂完成,父分区和子分区成为独立分区,重复的数据将被RocksDB的Compaction机制进行垃圾回收。Partition Split功能的所有代码已经合并在主分支中,这个特性将在下一个版本中得到支持。
接下来我们介绍一下Pegasus周边生态。
众所周知,系统的核心部分提供了最主要的功能特性,为了更好的发挥和强化Pegasus的能力,我们同时开发和提供了丰富的周边生态工具。
1. Pegasus-Spark
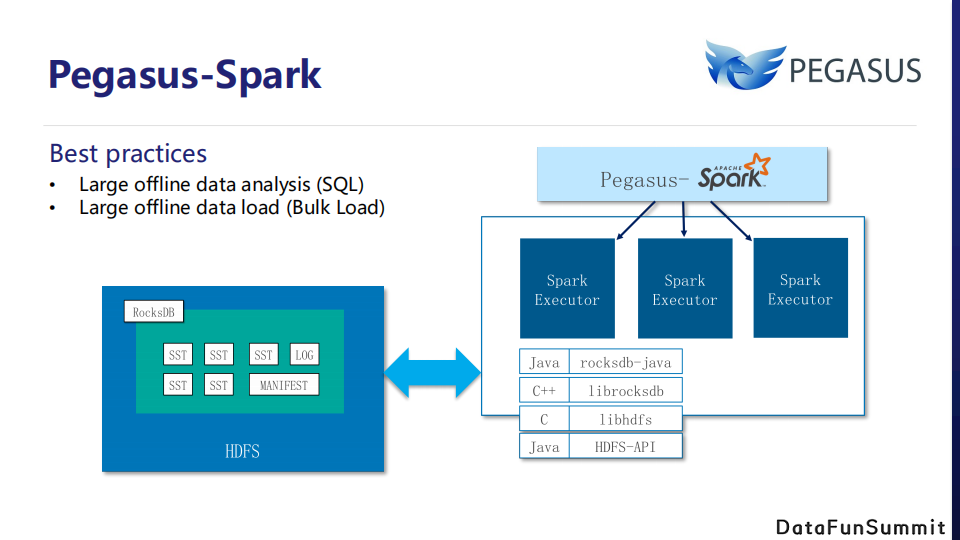
首先要介绍的就是Pegasus-Spark,它提供简单易用的连接Spark的功能,利用Spark强大的分布式处理能力,能够快速构建一个Spark任务。Pegasus-Spark是利用RocksJava + JNI开发的一个HDFS环境下的SST文件读写Connector。其中,两个最重要的场景就是离线分析能力和离线加载数据的能力。
离线数据分析,目的是提供数据的统计分析能力。用户首先需要利用数据导出工具在HDFS上生成离线快照,随后使用Pegasus-Spark连接该快照数据。用户既可以直接使用SparkSQL构建分析任务,也可以生成Parquet文件导入到Hive进行更加方便快捷的统计分析。
离线数据加载,目的是为了Pegasus的Bulk Load功能而开发的。如前面描述的那样,Bulk Load的离线加载需要从远程文件系统直接下载转换好的SST数据文件,然而SST数据文件的生成需要严格的规则保证:首先,待生成的数据必须是去重的;然后,它的分区个数必须和目标表的分片数目一致;最后,也是最重要的,所有的分区内数据必须是有序的。而去重-分区-排序恰好是Spark擅长的能力,因此基于Spark,我们可以很快的构建一个数据转换任务生成SST文件并被Bulk Load所使用。
2. Meta Proxy
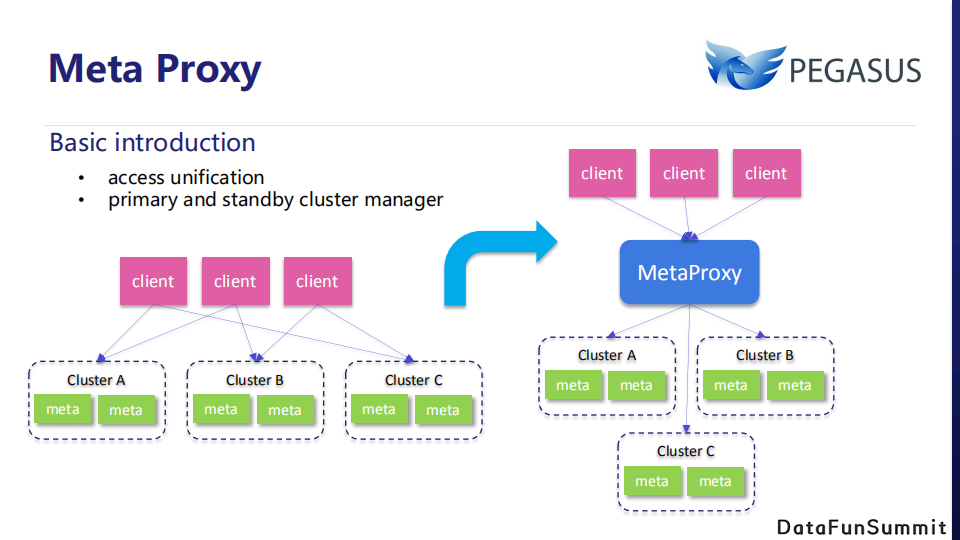
Meta Proxy,它本质上是Pegasus Meta Server的连接代理。Meta Proxy主要目标是屏蔽不同业务对不同集群的感知,以提供一个统一的接入入口。这样做可以带来很多好处:首先,不同的客户端不用再维护不同的集群的地址了;然后,由于屏蔽了MetaServer的地址,MetaServer节点的任何变更将变得透明而不再需要通知客户端。
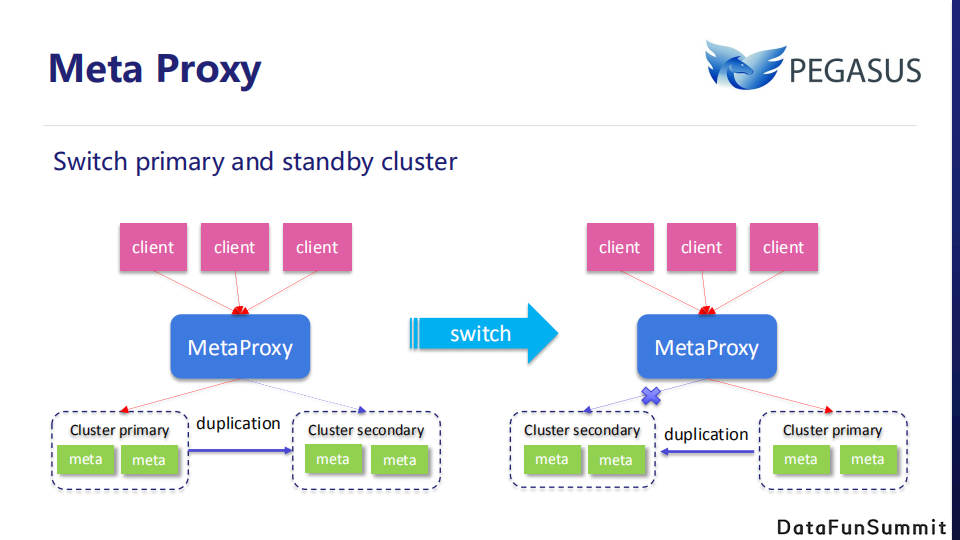
这些特性带来的一个显著优点就是:对于使用热备开启主备集群的用户,当主集群出现故障宕机后,Meta Proxy可以透明的切换主备集群,以增强系统的容灾能力。
3. 磁盘数据迁移工具
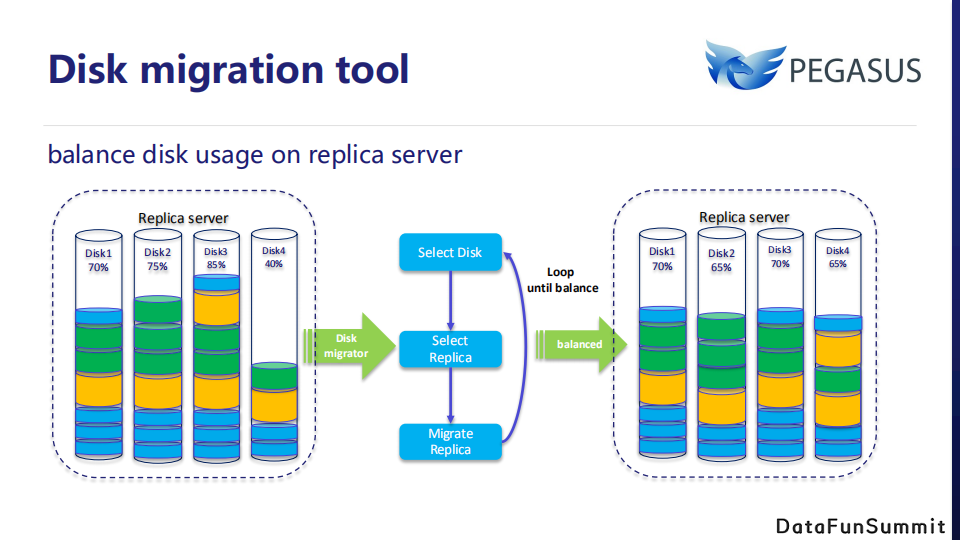
我们最后要推荐给大家的是磁盘数据迁移工具。随着数据不断的写入,对于使用多磁盘卷的部署架构来说,磁盘的使用不均极易导致分布式存储的容量瓶颈。在以前,我们往往因为单盘的使用量告警而不得不添加新的节点,这不仅增加了成本,而且由于节点间的分片迁移并不考虑磁盘容量,所以有时候收效甚微。
磁盘数据迁移工具提供了在线的磁盘均衡能力,它首先选择使用量最大的两个磁盘,然后选中符合要求的待迁移分片,随后执行分片迁移。在这个过程,服务端的分片需要经过拷贝->关闭->注册新路径->数据同步等一系列分片变更流程,好在这个过程对用户是透明的,用户基本不会感受到它带来的影响。

Pegasus最初在2015年立项和调研,并在一年后发布了第一个内部版本。2017年,我们开源了稳定版本1.7.0,并在随后的2020年加入Apache基金会成为孵化器项目。同年9月,我们发布了更为稳定和完善的2.0.0版本,基本涵盖了此次演讲的绝大部分特性。
社区的活跃性是我们关注的一个重点,为促进开源爱好者加入并共建Pegasus社区,我们建议贡献者可以从工具集开发入手,包括 client、shell等一系列增强工具。
Pegasus2.3.0发布时包含150多个commit,其中包含了Partition Split、用户自定义Compaction、集群负载均衡、一次性冷备份等功能。欢迎大家到Github上关注我们的Issue。未来对Pegasus还会增加周期性批量导入、热备份相关功能优化、热点分片检测、读吞吐限流、全链路追踪Tracing、Admin Service统一服务等功能。后续Pegasus还会继续优化架构,支持双副本、单副本架构。Pegasus的更长远规划上会尝试结合新存储引擎和新硬件。
Pegasus的开源社区方面的计划优化Benchmark,和更多其他K-V存储系统做对比,数据说话、发现不足。提供更多技术文档和文章,更多举办线上WorkShop活动和线下Meetup活动,增强和开发者的沟通。
如何参与Pegasus开源社区?在GitHub上提issue,没有issue就创建一个issue。GitHub:https://github.com/apache/incubator-pegasus。
也可以关注官方微信公众号Apache Pegasus和Pegasus官网https://pegasus.apache.org,获取更多技术内幕与用户支持。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

电子书下载

《大数据典藏版合集》电子书目录如上,感兴趣的小伙伴,欢迎识别二维码,添加小助手微信,回复『大数据典藏版合集』,即可下载。

关于我们:
🧐分享、点赞、在看,给个3连击呗!👇
