




Hbase:Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等 Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算 通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等 基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据
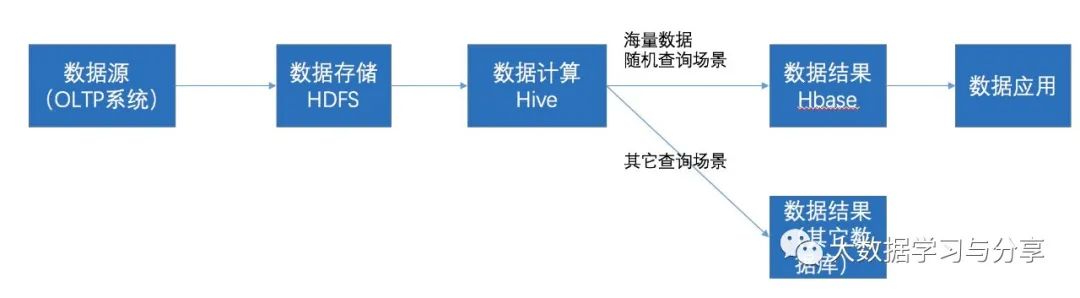
通过ETL工具将数据源抽取到HDFS存储 通过Hive清洗、处理和计算原始数据 HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase 数据应用从HBase查询数据
利用数据库的复制或镜像功能,同时在多台数据库上保存相同的数据,并且将读操作和写操作分开,写操作集中在一台主数据库上,读操作集中在多台从数据库上。复制过程的速度与系统中的从节点数量成反比。 关键的读取可能不正确,因为写可能没有来得及被向下传播; 大数据集可能会造成问题,因为主节点需要将数据复制到从节点;
通常来说,在满足ACID特性的数据库中进行扩展是非常难的。基于这个原因,对数据进行扩展,这个数据库本身就必须拥有简单的模型,将数据分割为N片,然后在单独的片中执行查询。数据分割的单元被称为“shard”。将N片数据分配个M个DBMS进行操作。DBMS并不会去管理数据片,这需由服务开发者自行完成。 不同的分片方法有:
优点与不足
Multi-Master replication:所有成员都响应客户端数据查询。多主复制系统负责将任意成员做出的数据更新传播给组内其他成员,并解决不同成员间并发修改可能带来的冲突。 INSERT only, not UPDATES/DELETES:数据进行版本化处理。 No JOINs, thereby reducing query time:Join的开销很大,而且频繁访问会使开销随着时间逐渐增加。非规范化(Denormalization)可以降低数据仓库的复杂性,以提高效率和改善性能。 In-memory databases:磁盘数据库
一致性(Consistency)(所有节点在同一时间具有相同的数据) 可用性
(Availability)(保证每个请求不管成功或者失败都有响应) 分区容忍性(Partition tolerance)(系统中任意信息的丢失或失败不会影响系统的继续运作)
Fast lookup using row key and optional timestamp. Range scan from region start to end. Full table scan
A lot of data sitting in HBase due to its usage in a real-time environment, but never used for analysis Give access to data in HBase usually only queried through MapReduce to people that don’t code (business analysts) When needing a more flexible storage solution, so that rows can be updated live by either a Hive job or an application and can be seen immediately to the other
推荐文章:
一文掌握HBase核心知识以及面试问题
文章转载自大数据学习与分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
