




1
1.1 TcaplusDB简介
TcaplusDB是腾讯自研,面向游戏的分布式 NoSQL ,也是腾讯云上首个自研数据库,分布在韩国、日本、台湾、越南、北美、南美等地域。其中,存储层是TcaplusDB最核心的模块,这个部分是如何做到故障自动探测与恢复的呢?本文章将对这部分进行介绍。
1.2 TcaplusDB接入案例

1.3 TcaplusDB系统架构
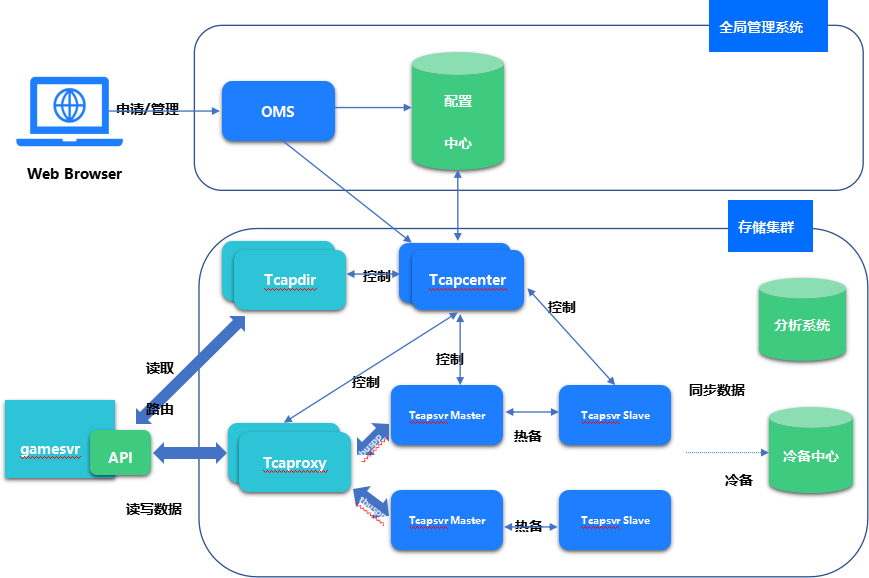
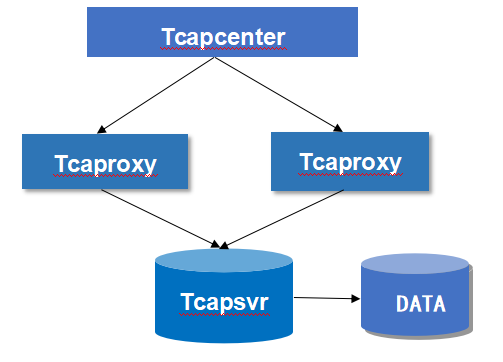
其中,Tcapcenter是系统的中控进程,一主一备,主提供服务。Tcapdir是目录服务器,API访问数据前先跟Tcapdir鉴权,鉴权通过拉取要访问的表所在业务的接入进程列表,Tcaproxy是接入进程,每个业务独立部署访问,业务下的Tcaproxy无状态,可动态扩缩容,Api对拉回来的接入进程构造一致性hash环,根据请求记录的key,计算hash,hash值取模选择某个Tcaproxy,发送请求到这个Tcaproxy。
TcaplusDB的表是以Sharding的方式分布在一到个存储节点上的,Tcaproxy内存中维护了表shard的分布信息,能根据key计算出这条记录落在哪个shard上,shard落在哪个Tcapsvr Master上,将请求转发给Tcapsvr Master完成数据读写。
Tcapsvr是存储进程,以一主一备的方式部署,每个业务的存储进程独立部署。Tcapdb是缓写进程,可以将制定表的增量数据同步到第三方系统用作分析。
本文章介绍存储层Tcapsvr的服务探测与故障恢复机制。
2
Tcapcenter会维护Tcapsvr的心跳信息。除了心跳,还会从两个维度独立去检测Tcapsvr服务状态,分别是“基于存储进程读写失败率的故障探测”和“基于ServiceProbe的服务故障探测”。
其中,“基于存储进程读写失败率的故障探测”是基于统计数据读写失败率的服务检测,只有有数据读写的Tcapsvr才能通过这种方式发现故障,“基于ServiceProbe的服务故障探测”是Tcapcenter主动发起的服务探测,对于没有数据读写的Tcapsvr也能探测是否故障。两个策略相互独立,彼此互补,任何一个满足满足,即判定为故障。
下面分别介绍心跳探测、基于存储进程读写失败率的故障探测、基于ServiceProbe的服务故障探测的具体逻辑。
2.1 心跳探测
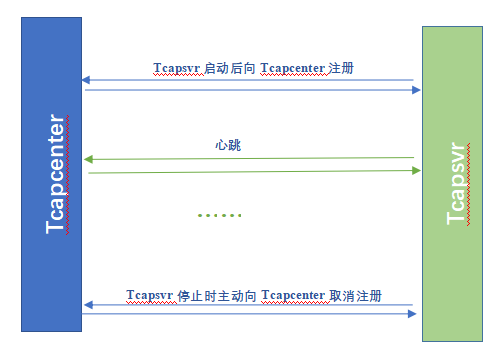
Tcapcenter记录了所有Tcapsvr进程实例最新一次心跳上报的时间。Tcapsvr默认状态为SERVICE_STOP,Tcapsvr启动时,主动向Tcapcenter注册,初始状态为SERVICE_NORMAL,Tcapsvr正常停止时,主动向Tcapcenter取消注册,状态被置为SERVICE_STOP,Tcapsvr每N秒(可配置,默认是5秒)向Tcapcenter发送一次心跳,Tcapcenter记录最近一次心跳时间。
2.2 基于存储进程读写失败率的故障探测
Tcaproxy以N秒(可配置)为周期,针对每个Tcapsvr独立的统计以下指标,并通过心跳上报给Tcapcenter。Tcapsvr Master会处理读写请求,开启了读分流的Tcapsvr Slave会处理读请求。线上实际开启对分流的Tcapsvr Slave不多,该机制主要是对Tcapsvr Master有意义,具体的:
1) ReadReqSuccNumPerCycle(每周期成功发给Tcapsvr的读请求数)
2) WriteReqSuccNumPerCycle(每周期成功发给Tcapsvr的写请求数)
3) ReadRespErrNumPerCycle(每周期收到的Tcapsvr返回读失败的响应数)
4) WriteRespErrNumPerCycle(每周期收到的Tcapsvr返回写失败的响应数)
所有的Tcaproxy每周期将以上指标报给Tcapcenter后,Tcapcenter会汇总处理所有Tcaproxy对每个Tcapsvr的指标,计算读写错误率,具体计算方式如下:
读错误率:所有Tcaproxy上报的同一个Tcapsvr的sum(ReadRespErrNumPerCycle)/sum(ReadReqSuccNumPerCycle)
写错误率:所有Tcaproxy上报的同一个Tcapsvr的sum(WriteRespErrNumPerCycle)/sum(WriteReqSuccNumPerCycle)
连续N个周期(可配置,默认3),读错误率或者写错误率大于P%(可配置,默认80%)时,认为Tcapsvr服务异常。
2.3 基于ServiceProbe的服务故障探测
由中控进程(Tcapcenter)模拟客户端,来发起对某个存储进程(Tcapsvr)的服务探测,随机选择至少N个(可配置,默认2个)接入进程(Tcaproxy)对Tcapsvr服务状态进行探测,具体流程如下:
1)Tcapcenter周期性随机挑选至少N个Tcaproxy发起ServiceProbeReq
2)被选中的Tcaproxy向Tcapsvr转发ServiceProbeReq请求
3)Tcapsvr收到该请求后,向所有工作线程转发消息,工作线程触发一次数据记录读操作并结果反馈给探测包发起者
4)Tcaproxy收到回包或等待超时后向Tcapcenter回包
5)Tcapcenter处理探测消息
6)有任何一个Tcaproxy返回探测成功, 则认为该Tcapsvr正常
7)Tcaproxy没回包,认为探测结果不确定,不会判定为故障。Tcapsvr超时的话Tcaproxy会明确给Tcapcenter回包告知Tcapsvr超时,认为探测失败
8)探测全部失败的,会立即再次发送探测请求, 仍然全部失败,认为该Tcapsvr异常
9)连续两轮(两次为一轮,两轮就是四次)探测都判定为服务异常将发起故障自动切换(StartFailoverTransaction)
根据探测结果扭转Tcapsvr的服务状态:
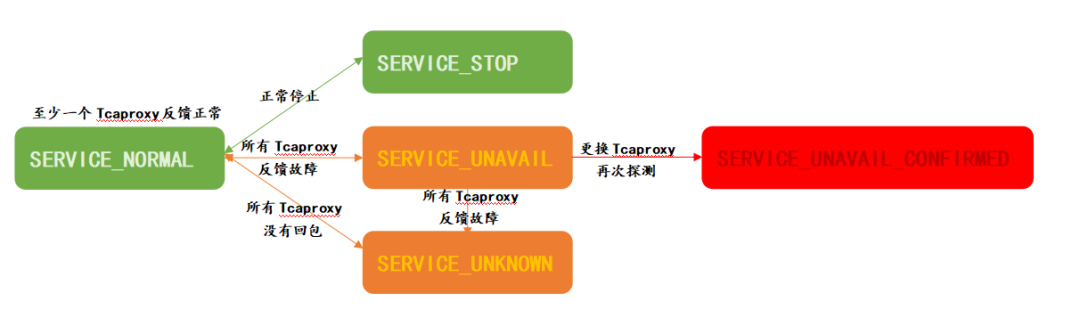
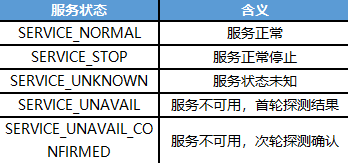
如果Tcapsvr最近一次的ServiceProbe探测结果为SERVICE_UNAVAIL_CONFIRMED即认为该存储进程故障,则判定为故障。
3
对于主备架构的数据库,如果是Master发生了故障,先来看看业界的一些数据库是如何做主从切换的,以Redis和MySQL为例:


接下来看看TcaplusDB是如何做的。
“基于存储进程读写失败率的故障探测”或者“基于ServiceProbe的服务故障探测”判定Tcapsvr Mastetr故障了,这个时候要立即发起故障恢复。这时候先去检查Tcapsvr Master与Tcapcenter心跳是否正常,正常的话说明Tcapcenter跟Tcapsvr Master还能通讯,走亚健康主备切换。如果Tcapsvr Master与Tcapcenter心跳也不正常了,说明Tcapcenter与Tcapsvr Master已经无法通讯了,走Failover强制主备切换。
亚健康主备切换和Failover强制主备切换的差别在于:前者认为Tcapsvr Master还是可以通讯的,希望尽量做到无损切换(主备切换过程中尽可能的不丢失数据),后者认为Tcapsvr Master彻底故障无法通讯了,放弃无损,跳过需要跟Tcapsvr Master交互的逻辑,尽量完成切换,让Tcapsvr Slave顶上立即提供服务。两种切换的流程如下:
Failover强制主备切换:
亚健康主备切换:

下面重点对亚健康主备切换的方案进行阐述。
亚健康主备切换希望做到无损服务,不拒绝服务、不丢失数据、请求不乱序,整体策略是尽力而为。关键方案是采用缓存和染色机制,在接入进程Tcaproxy实现缓存,主备切换期间缓存住要发往老的Tcapsvr Master的读写请求,切换结束后(Tcapsvr Master/Slave完成角色变更、Tcaproxy完成路由更新)再来处理这些缓存的请求,Tcaproxy将缓存中的请求发往新的Tcapsvr Master。所有发往原Tcapsvr Master的消息都缓存在同一个队列,按时间有序。
缓存期间会去检查超时,超时或者队列满时会强制处理掉队列头部的一个或者多个请求(丢弃这些请求,然后给Client回错误或者超时响应)。理论上缓存大小设置合理、切换时间足够快、切换后处理缓存消息足够及时就能做到完全无损。
3.1 缓存设计
1. 预分配一块最大的缓存;
2. 按需从预分配的缓存中申请存储空间;
3. 申请的存储空间是连续的;
4. 采用队列实现。之所以采用队列方式,是因为缓存的请求必须要按序处理,即先缓存的请求先处理,后缓存的请求后处理;
示例:
首先,预分配一块10MB的缓存,如图1所示:

图1
然后,申请一块大小为2KB的存储空间,如图2所示:

图2
接着,继续申请存储空间,直到可用空间为0.5KB,如图3所示:

图3
然后,申请1KB的存储空间,则由于可用空间不足,而分配失败。
接着,释放1.5KB的存储空间,如图4所示:

图4
最后,再次申请1KB的存储空间,由于连续可用空间满足要求,分配成功,如图5所示:

图5
5. 缓存结构定义如下:

3.2 主备切换
亚健康主备切换分为以下4个步骤:
Prepare:主备切换前的条件检查,确保所有接入进程(Tcaproxy)的缓存可用。考虑批量主备切换缓存冲突避让和重试, Tcapcenter要维护好每个Tcaproxy 的缓存状态。
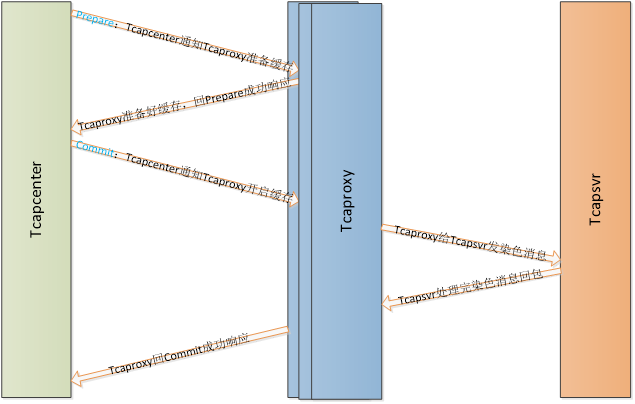
Action 1:Tcapcenter通知Tcaproxy开启相关路由号段的缓存。这里参考“两阶段提交”的思路,先发请求给所有Tcaproxy准备好缓存,等收到全部Tcaproxy的成功响应,再通知所有Tcaproxy开启缓存,真正开始缓存消息;
1. 检查缓存是否可用,可用的话准备好缓存,不可用的话填好ErrMsg,给Tcapcenter回失败响应;
2. 在Tcaproxy增加路由号段是否需要缓存消息的标志位,Tcaproxy收到请求,对相关号段的缓存标志置位,再给Tcapcenter回成功响应。
3. Tcapcenter只有收到了所有Tcaproxy的成功响应才继续事务,如果部分Tcaproxy回了失败的响应,视失败原因选择重试或者继续:
a. 缓存互斥。缓存正在被其他的切换或者搬迁事务使用,选择间断性重试,做好次数和时间控制;
b. 其它错误。失败的这些Tcaproxy放弃使用缓存,退化为无缓存切换;
4. Tcaproxy处理Client请求时,如果请求号段的路由状态为Normal,本号段开启了缓存,且缓存可用,则缓存消息,否则维持原逻辑;(这里缓存系统加个超时N,从创建缓存开始,N毫秒还没有切换路由,就开始强制处理缓存消息释放缓存,防止Tcapcenter异常一直不通知Tcaproxy关闭缓存,造成消息超时。这个超时N做成Tcapcenter的配置项,Tcapcenter通知tcaproxy开启缓存时告诉tcaproxy这个超时时间)
Action 2:Master切换为Slave。
Action 3:Slave切换为Master。
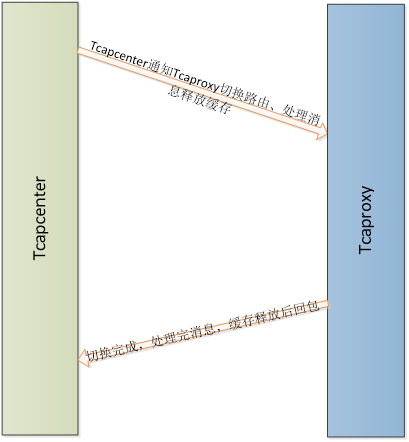
Action 4:Tcapcenter通知Tcaproxy切换路由,处理完缓存消息,完成切换。
1. Tcaproxy切换路由,并重置相关路由号段的缓存标志;
2. Tcaproxy处理完缓存队列的消息(注意:虽然关闭了缓存模式,为了保证消息的时序性,在缓存队列的消息没有处理完之前,后面来的请求还是要继续缓存,这里要做好判断),然后释放缓存。这里要做好速度控制,保证在有限的时间内可以处理完缓存消息,而不是越积越多,也不要对Tcaproxy性能造成负面影响;
3. Tcaproxy给Tcapcenter回包。
4
如果是Slave发生了故障,业界的数据库一般通过如下两种方式重建备机,分别以Redis和MySQL为例:

TcaplusDB也是基于备份数据做全自动Slave重建。下面对全自动Slave重建方案进行阐述。
4.1 整体流程
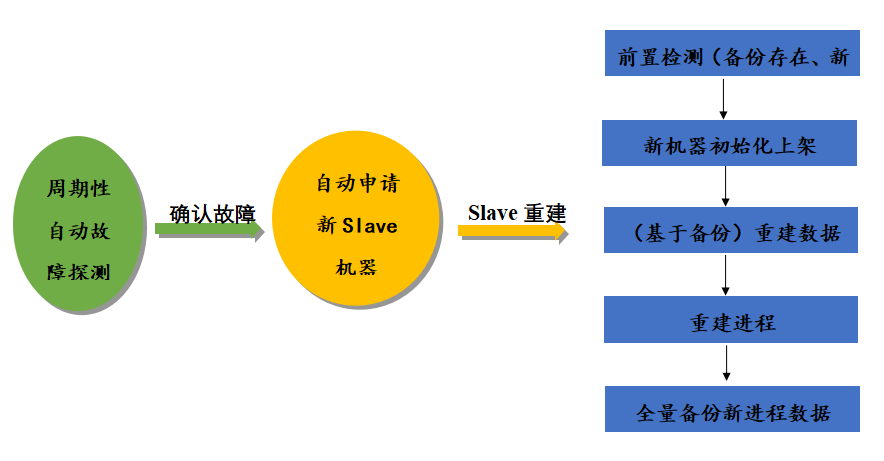
Tcapcenter会周期行通过ServiceProbe主动探测所有Tcapsvr的服务状态,如果探测到某个Slave故障,会触发全自动Slave重建。首先申请机器,初始化上架到TcaplusDB集群,再调度Slave重建。接下来对几个关键步骤进行介绍。
4.2 自动申请机器
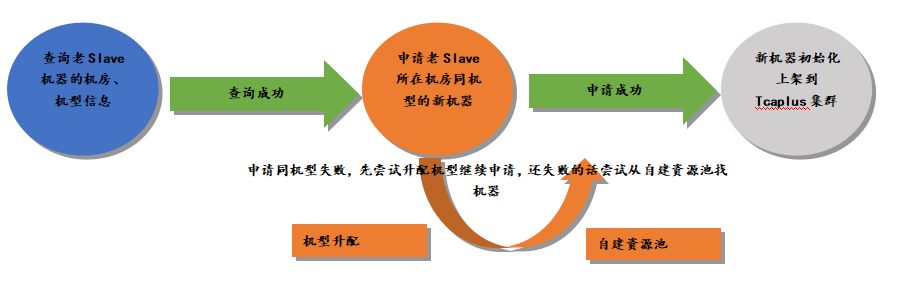
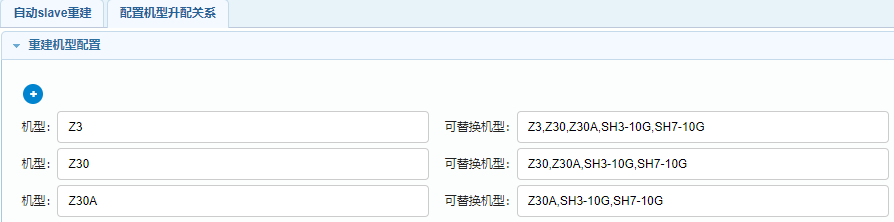
自动申请机器会申请老Tcapsvr Slave机器所在机房同机型的机器,如果申请失败,会升配机型,去申请同机房跟老机型配置相当或者更好的机型,还是申请不到会去TcaplusDB资源池中找符合条件的机器,TcaplusDB自建资源池常备3-5台不同机房不同机型的机器。自动申请机器是关键路径,设计机型升配和TcaplusDB自建资源池主要是为了提高申请机器的成功率,确保这个关键环节顺利通过。
对于老的Tcapsvr Slave如果只是进程挂了,机器没问题,可以跳过申请机器、初始化上架机器这个环节,直接在本机进行重建。
4.3 重建数据
申请到新机器并初始化上架到TcaplusDB集群后,接下来做数据重建,具体的:
1. 查询下载解压冷备:
获取最新的冷备和冷备时间点之后的Binlog列表
下载、解压并行提速,整个过程失败可重入;
2. 恢复数据:
Redo Binlog恢复数据到最近时间点;
Redo Binlog速度可以达到20w条/s;
Redo Binlog过程可重入;

对于本机Slave重建,可以直接使用本地的备份数据,跳过查询下载冷备的步骤。
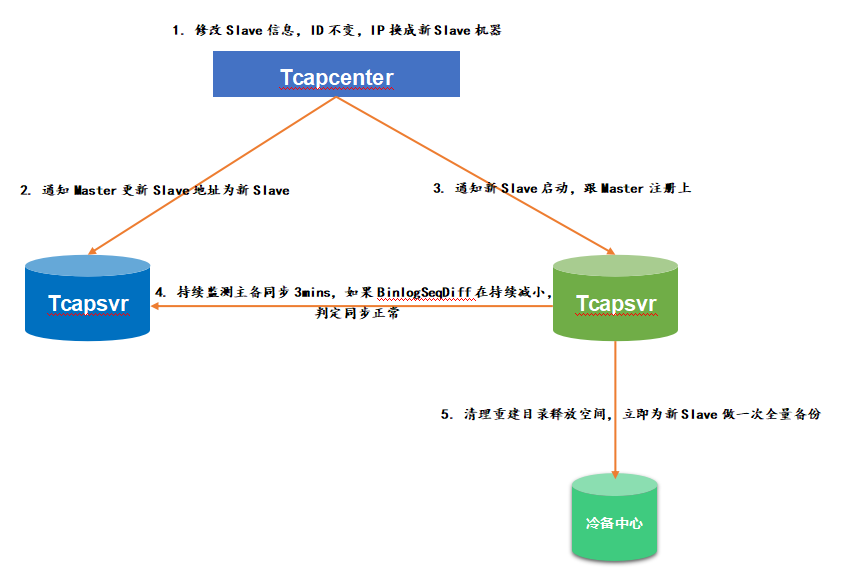
4.4 重建进程
数据重建完之后(对于某些特别的业务,只关心增量数据的,可以跳过整个重建数据环节,直接进入到重建进程),最后来重建进程,流程如下:
5
最后介绍一些其他的故障场景及对应的恢复策略:
1. 主备进程都挂了,但机器完好
对主备进程进行Restore(遍历引擎文件,整理恢复故障时健康的数据),Restore完启动进程提供服务。关于Restore后续会有专门的文章进行介绍。
2. 主备机器都挂了
先走全自动Slave重建恢复备机,再通过强制Failover主备切换让Slave变成Master提供服务,再通过全自动Slave重建重建出一个Slave,跟当前的Master注册上进行数据同步。
3. 备机挂了,且没有冷备
走设备搬迁,将这对主备成对的搬迁到一对新机器上,设备搬迁实际就是TcaplusDB数据搬迁,TcaplusDB数据搬迁后续也会有专门的文章进行介绍,敬请关注。
4. 机房掉电
TcaplusDB在部署主备时会确保主备部署在不同机房,一个机房掉电故障,这个机房的Master会故障切换为Slave,其他机房的Slave顶上提供服务。对于掉电的Slave,可以选择立即做全自动Slave重建到其他机房,也可以选择等待机房恢复,直接本机Slave重建或者Restore恢复进程。

HAPPY NEW YEAR
扫码关注
获取更多资讯
腾讯游戏
TcaplusDB
