




1. astore整体框架
astore整体框架如图所示。作为行存储子格式之一,astore需要实现自己的堆表存取(访存)管理接口、堆表页面结构、堆表元组结构、元组多版本机制,以及空闲空间管理和回收机制。
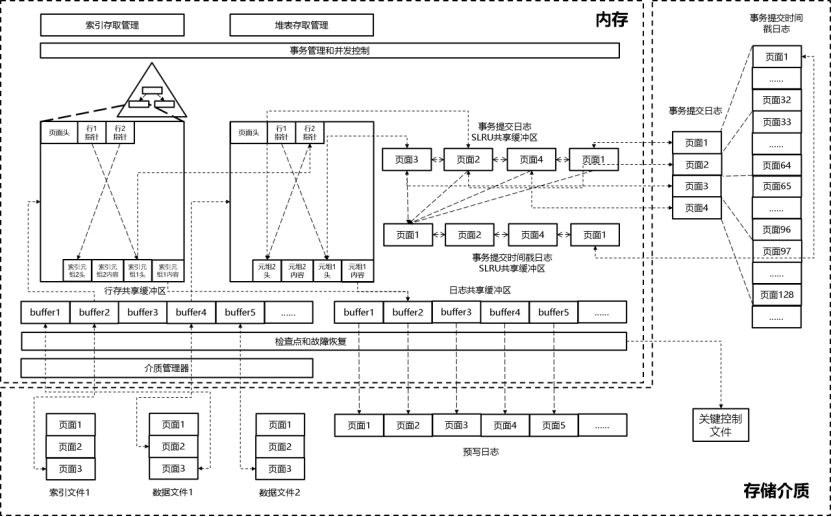
astore整体框架示意图
2. astore堆表页面元组结构
本节介绍astore堆表的页面和元组结构。
所谓堆表,是指元组无序存储,数据按照“先来后到”的方式存储在页面中的空闲位置。作为对比,在索引表中,元组根据索引键键值的排序,在页面内部有序存储,且各个页面之间在逻辑上也是有序存储的。堆表存储数据主体,索引表仅存储索引键键值以及对应的、完整元组的物理位置(即完整元组在堆表中的页面号和页内偏移)。
1) astore堆表元组结构
astore堆表元组结构的定义部分代码如下:
typedef struct HeapTupleFields {
ShortTransactionId t_xmin; /* 插入元组事务的事务号 */
ShortTransactionId t_xmax; /* 删除元组事务的事务号 */
union {
CommandId t_cid; /* 插入或删除命令在事务中的命令号 */
ShortTransactionId t_xvac;
} t_field3;
} HeapTupleFields;
typedef struct HeapTupleHeaderData {
union {
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 当前元组或更新后元组的行号 */
uint16 t_infomask2; /* 字段个数和标记位 */
uint16 t_infomask; /* 标记位 */
uint8 t_hoff; /* 包括NULL字段位图、对齐填充在内的元组头部大小 */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* NULL字段位图 */
/* 实际元组数据再该元组头部结构体之后,距离元组头部处偏移t_hoff字节 */
} HeapTupleHeaderData;
该结构体只是元组头部的定义,元组内容跟在该结构体后面,距离元组头部起始处的偏移由“t_hoff”成员保存。上面元组头部结构体部分成员信息,同时也构成了该元组的系统字段(字段序号小于0的那些字段)。对各个结构体成员的含义说明如下。
(1) t_xmin,插入元组的事务号(32位)。对应系统字段序号是MinTransactionIdAttributeNumber(-3)。
(2) t_xmax,删除元组的事务号(32位)。如果元组还没有被删除,那么为零。对应系统字段序号MaxTransactionIdAttributeNumber(-5)。
(3) t_cid,插入或删除元组的命令号。对应系统字段序号MinCommandIdAttributeNumber(-4)和MaxCommandIdAttributeNumber(-6)。
(4) t_ctid,当前元组的页面和页面内元组指针下标。如果该元组被更新,为更新后元组的页面号和页面内元组指针下标。
(5) t_infomask2,元组属性掩码,包含元组中字段个数、HOT(heap only tuple,堆内元组)更新标记、HOT元组标记等。
(6) t_infomask,元组另一个属性掩码,包含是否有空字段标记、是否有变长字段标记、是否有外部TOAST(the oversized-attribute storage technique,过长字段存储技术)标记、是否有OID字段标记、是否有压缩标记、插入事务是否提交/回滚标记、删除事务是否提交/回滚标记、是否被更新标记等。如果OID标记存在,那么元组OID从“t_hoff”偏移位置之前4个字节获得,对应系统字段序号ObjectIdAttributeNumber(-2)。
(7) t_hoff,元组数据距离元组头部结构体起始位置的偏移。
(8) t_bits,所有字段的NULL值bitmap。每个字段对应t_bits中的一个bit位,因此是变长数组。
上述元组结构体在内存中使用时嵌入在一个更大的元组数据结构体中,该结构体的定义代码如下。除了保存元组内容的t_data成员之外,其他的成员保存了该元组的一些其他系统信息,这些信息构成了该元组剩余的一些系统字段内容:
typedef struct HeapTupleData {
uint32 t_len; /* 包括元组头部和数据在内的元组总大小 */
ItemPointerData t_self; /* 元组行号 */
Oid t_tableOid; /* 元组所属表的OID */
TransactionId t_xid_base;
TransactionId t_multi_base;
HeapTupleHeader t_data; /* 指向元组头部 */
} HeapTupleData;
该结构体主要成员的含义如下。
(1) t_len,元组长度。
(2) t_self,元组所在页面号和页面内元组指针下标,对应系统字段序号SelfItemPointerAttributeNumber(-1)。
(3) t_tableOid,该元组所属表的OID,对应系统字段序号TableOidAttributeNumber(-7)。
介绍了astore堆表元组结构,下面介绍常用的astore堆表元组操作接口。如表所示。
表 常用的元组操作接口
操作接口名 | 操作含义 | 对应的行存储统一访存接口 |
heap_form_tuple | 使用传入的、各个元组字段的values数组和nulls数组,生成一条完整的元组。一般用于插入操作 | tableam_tops_form_tuple |
heap_deform_tuple | 使用传入的完整元组以及各个字段的类型定义,解构各个字段的值,生成values数组和nulls数组。一般用于更新前的准备工作 | tableam_tops_deform_tuple |
heap_modify_tuple | 先调用heap_deform_tuple解构传入的原始元组,然后将解构得到的values和nulls数组中需要更新的字段替换为新的值,最后再调用heap_form_tuple生成修改后的完整元组。一般用于更新操作 | tableam_tops_modify_tuple |
heap_freetuple | 释放一条元组对应的内存空间 | tableam_tops_free_tuple |
heap_copytuple | 复制一条完整的元组,包括元组头和元组内容 | tableam_tops_copy_tuple |
heap_form_cmprs_tuple | 类似heap_form_tuple,生成一条压缩后的元组 | tableam_tops_form_cmprs_tuple |
heap_deform_cmprs_tuple | 类似heap_deform_tuple,解构一条压缩后的元组 | tableam_tops_deform_cmprs_tuple |
heap_getattr | 获取一条元组中指定的用户或系统字段值 | tableam_tslot_getattr |
heap_getsysattr | 获取一条元组中指定的系统字段值 | tableam_tops_getsysattr |
在上述操作接口中,heap_getattr操作接口是最常用的操作接口之一,执行流程如图所示。
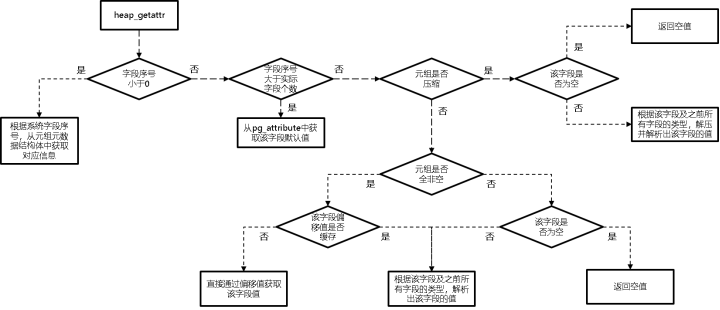
heap_getattr操作接口从元组中获取单个字段值的流程图
heap_getattr操作接口在代码上做了多处优化:
(1) 判断待访问的字段序号是否大于元组头部保存的元组实际字段个数;如果大于,则通过访问pg_attribute系统表得到。该优化来自快速追加表字段特性。该特性允许用户在不需要重写一张表所有行的情况下,在一张表的最后增加一个或多个带默认值约束的字段。
(2) 如果该元组的字段全部非空并且待查询字段之前所有的字段都是定长的,那么在上一个heap_getattr查询该字段的操作过程中,会缓存该字段在元组中的字节偏移;之后再次查询时,当满足元组字段全部非空的情况下会使用上述缓存的偏移位置直接读取字段内容。
(3) 读取元组头部的NULL值bitmap,如果该字段对应的bitmap中的比特位非0,则直接返回NULL值。
2) astore堆表页面结构
由于整体行存储格式默认的介质管理器是磁盘文件系统,因此采用了和文件系统类似的段页式设计,最小I/O单元为一个页面,这样可以在大多数场景下获得比较好的I/O性能和较低的I/O开销。一个astore堆表页面默认大小为8kB,其结构如图所示。

astore堆表页面结构示意图
在一个astore堆表页面中,页面头部分对应HeapPageHeaderData结构体。其中,pd_multi_base以及之前的部分对应定长成员,存储了整个页面的重要元信息;pd_multi_base之后的部分对应元组指针变长数组,其每个数组成员存储了页面中从后往前的、每个元组的起始偏移和元组长度。如图4-4所示,真正的元组内容从页面尾部开始插入,向页面头部扩展;相应的,记录每条元组的元组指针从页面头定长成员之后插入,往页面尾部扩展;整个页面中间形成一个空洞,供后续插入的元组和元组指针使用。
对于一个astore堆表的一条具体元组,有一个全局唯一的逻辑地址,即元组头部的t_ctid,其由元组所在的页面号和页面内元组指针数组下标组成;该逻辑地址对应的物理地址,则由ctid和对应的元组指针成员共同给出。通过页面、对应元组指针数组成员、页面内偏移和元组长度的访问顺序,就可以完整获取到一条元组的完整内容。t_ctid结构体和元组指针结构体的定义代码如下。
/* t_ctid结构体*/
typedef struct ItemPointerData {
BlockIdData ip_blkid; /* 页号 */
OffsetNumber ip_posid; /* 页面偏移,即对应的页内元组指针下标 */
} ItemPointerData;
/* 页面内元组指针结构体 */
typedef struct ItemIdData {
unsigned lp_off : 15, /* 元组起始位置(距离页头) */
lp_flags : 2, /* 元组指针状态 */
lp_len : 15; /* 元组长度 */
} ItemIdData;
如上两级的元组访问设计,主要有两个优点。
(1) 在索引结构中(参见“4.2.5 行存储索引机制”小节),只需要保存元组的t_ctid值即可,无须精确到具体字节偏移,从而降低了索引元组的大小(节约两个字节),提升索引查找效率;
(2) 将页面内元组的地址查找关系自封闭在页面内部的元组指针数组中,和外部索引解耦,从而在某些场景下可以让页面级空闲空间整理对外部索引数据没有影响,降低空闲空间回收的开销和设计复杂度。具体实现机制在“5. astore空间管理和回收”小节中介绍。
astore堆表页面头具体结构体定义代码如下:
typedef struct {
PageXLogRecPtr pd_lsn; /* 页面最新一次修改的日志lsn */
uint16 pd_checksum; /* 页面CRC */
uint16 pd_flags; /* 标志位 */
LocationIndex pd_lower; /* 空闲位置开始出(距离页头) */
LocationIndex pd_upper; /* 空闲位置结尾处(距离页头) */
LocationIndex pd_special; /* 特殊位置起始处(距离页头) */
uint16 pd_pagesize_version;
ShortTransactionId pd_prune_xid;
TransactionId pd_xid_base;
TransactionId pd_multi_base;
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER];
} HeapPageHeaderData;
其中各个成员的含义如下。
(1) pd_lsn:该页面最后一次修改操作的预写日志结束位置的下一个字节,用于检查点推进和保持恢复操作的幂等性(幂等指对接口的多次调用所产生的结果和调用一次是一致的)。
(2) pd_checksum:页面的CRC校验值。
(3) pd_flags:页面标记位,用于保存各类页面相关的辅助信息,如页面是否有空闲的元组指针、页面是否已满、页面元组是否都可见、页面是否被压缩、页面是否是批量导入的、页面是否加密、页面采用的CRC校验算法等。
(4) pd_lower:页面中间空洞的起始位置,即当前已使用的元组指针数组的尾部。
(5) pd_upper:页面中间空洞的结束位置,即下一个可以插入元组的起始位置。
(6) pd_special:页面尾部特殊区域的起始位置。该特殊位置位于第一条元组记录和页面结尾之间,用于存储一些变长的页面级元信息,如采用的压缩算法信息、索引的辅助信息等。
(7) pd_pagesize_version:页面的大小和版本号。
(8) pd_prune_xid:页面清理辅助事务号(32位),通常为该页面内现存最老的删除或更新操作的事务号,用于判断是否要触发页面级空闲空间整理。实际使用的64位prune事务号由“pd_prune_xid”字段和“pd_xid_base”字段相加得到。
(9) pd_xid_base:该页面内所有元组的基准事务号(64位)。该页面所有元组实际生效的64位xmin/xmax事务号由“pd_xid_base”(64位)和元组头部的“t_xmin/t_xmax”字段(32位)相加得到。
(10) pd_multi_base:类似“pd_xid_base”字段,当对元组加锁时,会将持锁的事务号写入元组中,该64位事务号由“pd_multi_base”字段(64位)和元组头部的“t_xmax”字段(32位)相加得到。
(11) pd_linp:元组指针变长数组。
对于astore堆表页面的主要管理接口如下表所示。鉴于astore采用的元组多版本设计实现方式,删除操作并不会直接从页面中删除指定的元组,页面管理也没有提供这样的接口。对于被删除的、过于陈旧的元组,通过页面空闲空间整理流程完成。
表 页面管理接口函数
函数名 | 操作含义 |
PageAddItem | 在页面中插入一条新的元组 |
PageRepairFragmentation | 页面空闲空间整理 |
在astore堆表页面中,采用64位页面“pd_xid_base”字段和32位元组“t_xmin/t_xmax”字段组合设计方式的原因如下。
早期openGauss版本采用32位事务号,所以对于OLTP类系统事务号消耗速度很快。当消耗的事务号超过最大事务号一半左右时,整个系统会强制对所有元组进行防止事务号回卷的整理工作。这个过程将阻塞所有写查询,系统不可用。
为了解决这个问题,openGauss将事务号升级到64位。为了平滑兼容之前32位事务号的元组头部结构,没有改变元组的结构和长度,而是在32位事务号页面头部结构体的基础上,扩展增加了标识整个页面所有元组事务号范围的64位基准事务号“pd_xid_base”和“pd_multi_base”两个字段。同一个页面中所有元组实际的64位“xmin/xmax”字段,一定在“pd_xid_base”字段和“pd_xid_base+2322”之间。
可以通过astore堆表页面头部“pd_pagesize_version”字段中页面版本号来区分32位事务号页面和64位事务号页面:
(1) 版本号等于4,为32位事务号页面。
(2) 版本号等于5,为64位非堆表页面(如索引页面)。这类页面的页头无须保存64位事务号信息,因此和32位事务号页面采用相同的结构。这类页面中可能涉及的64位事务号信息,保存在页面尾部的“”pd_special”字段区域中。
(3) 版本号等于6,即为64位astore堆表页面。
对于从32位事务号系统升级上来的astore堆表页面,在部分页面访问场景中(如RelationGetBufferForTuple/heap_delete/heap_update/heap_lock_tuple),首先会判断访问的页面是否是4号版本。若是4号版本,则调用heap_page_upgrade尝试进行页面版本升级。当页面空闲空间足够放下扩展的两个成员(共16个字节)时,调用PageLocalUpgrade函数将页面格式升级到64位,且升级后的pd_xid_base字段和pd_multi_base字段一定为0;如果剩余空间不够,系统会给出报错或告警,并提示用户执行VACUUM FULL命令来手动升级页面。
对于需要修改元组事务号的操作(如heap_insert/heap_multi_insert/heap_delete/heap_update/heap_lock_tuple),需要判断新写入的64位事务号是否满足在页面的“pd_xid_base”和“pd_xid_base+232”之间。如果满足,则通过检查;否则,需要调整页面的“pd_xid_base”字段或“pd_multi_base”字段的值以满足上述条件。如果新写入的事务号和页面上现有任意一个元组的“xmin/xmax”事务号差距已经超过232,系统还会尝试对现有元组进行“freeze”(冻结)操作。如果“freeze”操作之后,上述事务号差距还是超过232,该查询会报错退出。
32位事务号astore堆表页面头结构代码如下所示,各成员含义可参考64位事务号页面头结构:
typedef struct {
PageXLogRecPtr pd_lsn;
uint16 pd_checksum;
uint16 pd_flags;
LocationIndex pd_lower;
LocationIndex pd_upper;
LocationIndex pd_special;
uint16 pd_pagesize_version;
ShortTransactionId pd_prune_xid;
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER];
} PageHeaderData;
3. astore元组多版本机制
openGauss行存储表支持多版本元组机制,即为同一条记录保留多个历史版本的物理元组以解决对同一条记录的读、写并发冲突(读事务和写事务工作在不同版本的物理元组上)。
astore存储格式为追加写优化设计,其多版本元组产生和存储方式如下图所示。当一个更新操作将v0版本元组更新为v1版本元组之后,如果v0版本元组所在页面仍然有空闲空间,则直接在该页面内插入更新后的v1版本元组,并将v0版本的元组指针指向v1版本的元组指针。在这个过程中,新版本元组以追加写的方式和被更新的老版本元组混合存放,这样可以减少更新操作的I/O开销。然而,需要指出的是,由于新、老版本元组是混合存放的,因此在清理老版本元组时需要的清理开销会比较大。因此,astore存储格式比较适合频繁插入、少量更新的业务场景。
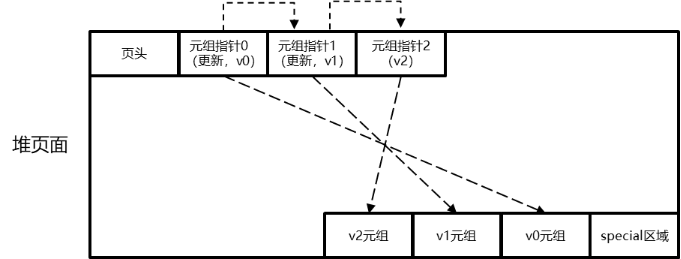
astore多版本元组产生和存储方式示意图
下面结合下图,介绍openGauss中行存储格式多版本元组的运行机制:
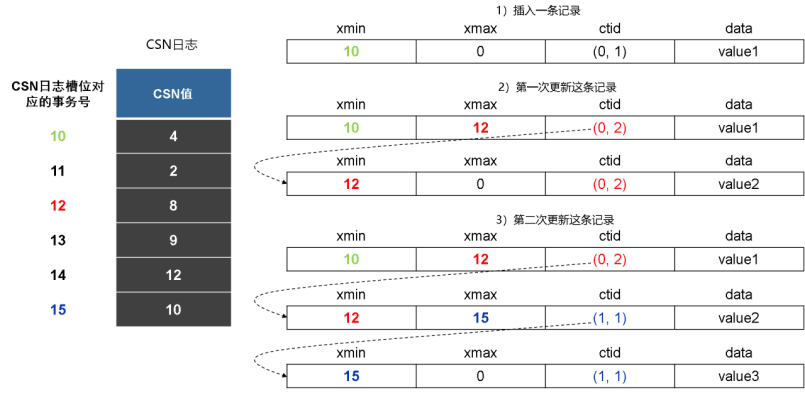
行存储格式多版本元组运行机制示意图
(1) 首先事务号为10的事务插入一条值为value1的新记录。对应的页面修改为:在0号物理页面的第一个元组指针指向位置,插入一条“xmin”字段为10、“xmax”字段为0、“ctid”字段为(0,1)、“data”字段为value1的物理元组。该事务提交,将CSN从3推进到4,并且在CSN日志中对应事务号10的槽位处记下该CSN的值。
(2) 然后事务号为12的事务将上面这条记录的值从value1修改为value2。对应的页面修改为:在0号物理页面的第二个元组指针指向位置,插入另一条“xmin”字段为12、“xmax”字段为0、“ctid”字段为(0,2)、“data”为value2的物理元组。同时保留上面第一条插入的物理元组,但是将其“xmax”字段从0修改为12,将其“ctid”字段修改为(0,2),即新版本元组的物理位置。该事务提交,将CSN从7推进到8,并且在CSN日志中对应事务号12的槽位处记下该CSN的值。
(3) 最后事务号为15的事务将上面这条记录的值从value2又修改为value3,对应的页面修改为:(假设0号页面已满)在1号物理页面的第一个元组指针指向位置,插入一条“xmin”字段为15、“xmax”字段为0、“ctid”字段为(1,1)、“data”字段为value3的物理元组;同时,保留上面第1、第2条插入的物理元组,但是将第2条物理元组的“xmax”字段从0修改为15,将其“ctid”字段修改为(1,1),即最新版本元组的物理位置。该事务提交,将CSN从9推进到10,并且在CSN日志中对应事务号15的槽位处记下该CSN的值。
(4) 对于并发的读事务,其在查询执行开始时,会获取当前的全局CSN值作为查询的快照CSN。对于上面同一条记录的3个版本的物理元组来说,该读查询操作只能看到同时满足如下两个条件的这个物理元组版本。
元组“xmin”字段对应的CSN值小于等于读查询的快照CSN。
‚ 元组“xmax”字段为0,或者元组“xmax”字段对应的CSN值大于读查询的快照CSN。
比如,若并发读查询的快照CSN为8,那么这条查询将看到value2这条物理元组;若并发读查询的快照CSN为11,那么这条查询将看到value3这条物理元组。
对于不同的行存储子格式,上述多版本元组的格式和存储方式可能有所不同,但是可见性判断和并发控制方式都是如图4-6中所示的。通过上面介绍的元组可见性判断流程,可以发现:并发的读事务会根据自己的查询快照在同一个记录的多个历史版本元组中选择合适的那个来返回。并且即使是在可重复读的事务隔离级别下,只要使用相同的快照总可以筛选出相同的那个历史版本元组。在整个过程中读事务不阻塞任何对该记录的并发写操作(更新和删除)。
更详细的元组可见性判断流程将在后面中详细介绍。
最后,对于astore行存储格式,更新一条记录的详细执行流程如图所示,该图可以帮助读者更形象地理解多版本元组的产生流程,以及写、写并发下的处理逻辑。
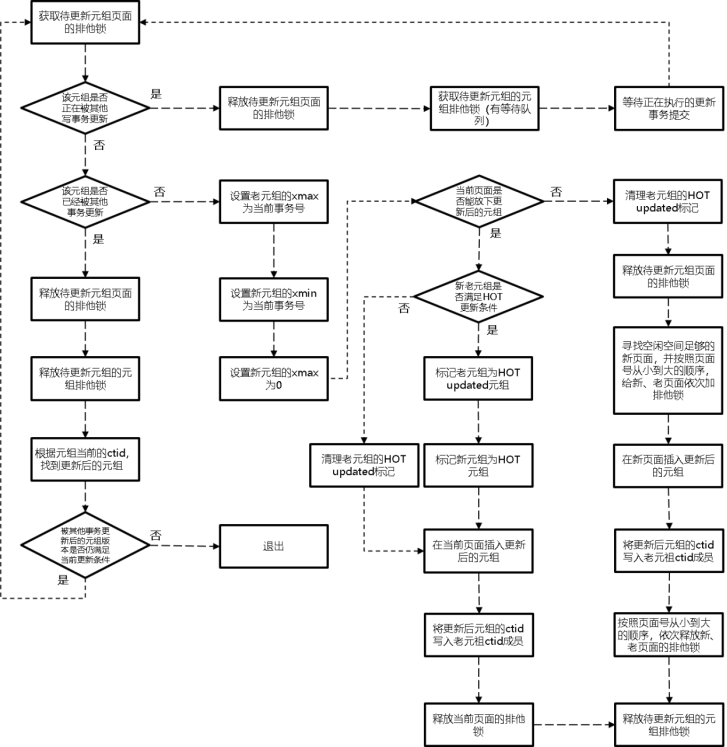
更新astore记录的执行流程示意图
4. astore访存管理
openGauss中的astore堆表访存接口如表所示。
表 astore堆表访存接口
接口名称 | 接口含义 | 对应的行存储统一访存接口 |
heap_open | 打开一个表,得到表的相关元信息 | 无 |
heap_close | 关闭一个表,释放该表的加锁或引用 | 无 |
heap_beginscan | 初始化堆表(顺序)扫描操作 | tableam_scan_begin |
heap_endscan | 结束并释放堆表(顺序)扫描操作 | tableam_scan_end |
heap_rescan | 重新开始堆表(顺序)扫描操作 | tableam_scan_rescan |
heap_getnext | (顺序)获取下一条元组 | tableam_scan_getnexttuple |
heap_markpos | 记录当前扫描位置 | tableam_scan_markpos |
heap_restrpos | 重置扫描位置 | tableam_scan_restrpos |
heapgettup_pagemode | heap_getnext内部实现,单页校验模式 | 无 |
heapgettup | heap_getnext内部实现,单条校验模式 | 无 |
heapgetpage | (顺序)获取并扫描下一个堆表页面 | tableam_scan_getpage |
heap_init_parallel_seqscan | 初始化并行堆表(顺序)扫描操作 | tableam_scan_init_parallel_seqscan |
heap_insert | 在堆表中插入一条元组 | tableam_tuple_insert |
heap_multi_insert | 在堆表中批量插入多条元组 | tableam_tuple_multi_insert |
heap_delete | 在堆表中删除一条元组 | tableam_tuple_delete |
heap_update | 在堆表中更新一条元组 | tableam_tuple_update |
heap_lock_tuple | 在堆表中对一条元组加锁 | tableam_tuple_lock |
heap_inplace_update | 在堆表中(就地)更新一条元组 | 无 |
以astore堆表顺序扫描为例,执行流程如下。
(1) 调用heap_open接口打开待扫描的堆表,获取表的相关元信息,如表的行存储子格式为astore格式等。该步通常要获取AccessShare一级表锁,防止并发的DDL操作。
(2) 调用tableam_scan_begin接口,从g_tableam_routines数组中找到astore的初始化扫描接口,即heap_beginscan接口,完成初始化顺序扫描操作相关的结构体。
(3) 循环调用tableam_scan_getnexttuple接口,从g_tableam_routines数组中找到astore的扫描元组接口,即heap_getnext接口,顺序获取一条astore元组,直到完成全部扫描。顺序扫描时,每次先获取下一个页面,然后依次返回该页面上的每一条元组。这里提供了两种元组可见性的判断时机:
heapgettup_pagemode。在第一次加载下一个页面时,加上页面共享锁,完成对页面上所有元组的可见性判断,然后将可见的元组位置保存起来,释放页面共享锁。后面每次直接从保存的可见性元组列表中返回下一条可见的元组,无须再对页面加共享,使用快照的查询,默认都使用该批量模式,因为元组的可见性在同一个快照中不会再发生变化。
‚ heapgetpage。除了第一次加载下一个页面时需要批量校验元组可见性之外,在后面每一次返回该页面下一条元组时,都要重新对页面加共享锁,判断下一条元组的可见性。该模式的查询性能较批量模式要稍低,适用于对系统表的顺序扫描(系统表的可见性不参照查询快照,而是以实时的事务提交状态为准)。
(4) 调用tableam_scan_end接口,从g_tableam_routines数组中找到astore的扫描结束接口,即heap_endscan接口,结束顺序扫描操作,释放对应的扫描结构体。
(5) 调用heap_close接口,释放对表加的锁或引用计数。
5. astore空间管理和回收
openGauss中采用最大堆二叉树结构来记录和管理astore堆表页面的空闲空间,该最大堆二叉树结构按照页面粒度进行与存储介质的读写操作,并单独储存于专门的空闲空间位图文件中(free space map,简称FSM)。该FSM文件的结构如图所示。
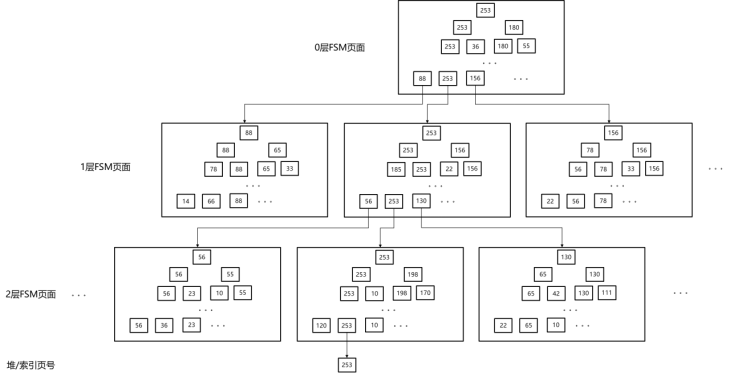
astore FSM文件结构示意图
所有页面分为叶子节点页面和内部节点页面两种。两种页面的页面内部结构完全相同,区别在于:对于叶子节点页面,其页面中记录的二叉树的叶子节点对应堆/索引表页面的空闲空间程度;对于内部节点页面,其页面中记录的二叉树的叶子节点对应下层FSM页面的最大空闲空间程度。
使用FSM页面中的1个字节(即256档)来记录一个堆/索引页面的空闲空间程度。在FSM页面中不会记录任何堆/索引页面的页号信息,也不会记录任何根、子FSM节点页面的页号信息,这些信息主要通过以下的规则来计算得到:
(1) 在一个FSM页面内部,二叉树节点按照从上到下、从左到右逐层排布,即:第一个字节为根节点的空闲程度,第二个字节为第一层内部节点最左边节点的空闲程度,依次类推。
(2) 所有FSM页面在物理存储上采用深度优先顺序,即某个FSM页面之前所有的物理页面包括:该FSM页面所在子树的所有上层节点,加上该FSM页面所有左侧子树。
(3)所有FSM叶子节点页面中的二叉树的叶子节点,对应堆/索引表页面的空闲空间程度,且根据从左到右的顺序,分别对应第1个、第2个、….、第n个堆/索引表物理页面。
(4)除了(3)中这些FSM节点之外,其他FSM父节点保存子节点(子树)中空闲空间的最大值。
根据上述算法,可以高效地查询出具有足够空闲空间的堆/索引页面的页面号,并将待插入的数据插入其中。
FSM模块主要的对外接口和含义如表所示。
表 FSM模块主要的对外接口
接口名称 | 接口含义 |
GetPageWithFreeSpace | 获取空闲程度大于入参的堆/索引页面号 |
RecordAndGetPageWithFreeSpace | 更新当前(不满足条件的)堆/索引页面的空闲空间程度,寻找新的空闲程度大于入参的堆/索引页面号 |
RecordPageWithFreeSpace | 更新单个堆/索引页面的空闲空间程度 |
UpdateFreeSpaceMap | 更新多个(批量插入的)堆/索引页面的空闲空间程度 |
FreeSpaceMapTruncateRel | 删除所有储存大于某个堆/索引页面号空闲信息的FSM页面 |
FreeSpaceMapVacuum | 修正所有FSM内部节点的空闲空间信息 |
此外,为了保证FSM信息的维护操作不会带来明显的开销,因此FSM的所有修改都是不记录日志的。同时,对于某个堆/索引页面对应的FSM信息,只在页面初始化和页面空闲空间整理(见本节后面介绍)两种场景下才会主动更新,除此之外,只有当新插入的数据发现该页面实际空间不足时才会被动更新该页面对应的FSM信息(也包括由于宕机导致的FSM页面损坏)。
空闲空间的管理难点在于空闲空间的回收。在openGauss中,对于astore存储格式,有3种回收空闲空间的方式,如图所示。
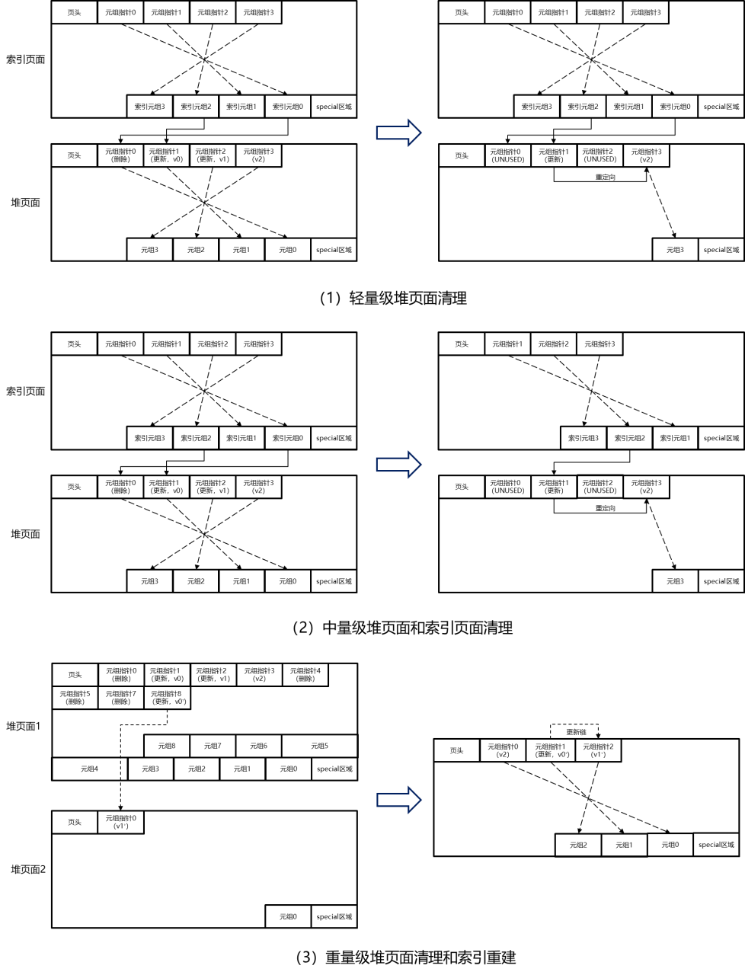
astore空闲空间回收机制示意图
1. 轻量级堆页面清理
当查询扫描到某个astore堆表页面时,会顺带尝试清理该页面上已经被删除的、足够老的元组(足够老是指在元组对于所有并发查询均为已经删除状态,具体参见事务处理章节)。由于只是顺带清理该页面内容,因此只能删除元组内容本身,元组指针还需要保留,以免在索引侧造成空引用或空指针。一个比较特殊的情况是HOT场景。HOT场景是指对于该表上所有的索引更新前后的索引键值均没有发生变化,因此对于更新后的元组只需要插入堆表元组而不需要新插入索引元组。对于同一个页面内一条HOT链上的多个元组,如果它们都足够老了,那么在清理时可以额外删除所有中间的元组指针,只保留第一个版本的元组指针,并将其重定向到第一个不用被清理的元组版本的元组指针。
轻量级堆页面清理的接口是heap_page_prune_opt函数,关键的数据结构是PruneState结构体,定义代码如下:
typedef struct {
TransactionId new_prune_xid;
TransactionId latestRemovedXid;
int nredirected; /* 待重定向的元组个数 */
int ndead; /* 待标记死亡的元组个数 */
int nunused; /* 待回收的元组个数 */
OffsetNumber redirected[MaxHeapTuplesPerPage * 2];
OffsetNumber nowdead[MaxHeapTuplesPerPage];
OffsetNumber nowunused[MaxHeapTuplesPerPage];
bool marked[MaxHeapTuplesPerPage + 1];
} PruneState;
其中,“new_prune_xid”字段用于记录页面上此次没有被清理的、但是已经被删除的元组的xmax,用于决定下次何时再次清理该页面;“latestRemovedXid”字段用于记录该页面上被清理的元组的最大的xmax,用于判断热备上回放页面整理时是否需要等待只读查询;nredirected、ndead、nunused、redirected、nowdead和nowunused分别记录该页面上待重定向的、待标记死亡的、待回收的元组。
2. 中量级堆页面和索引页面清理
openGauss提供VACUUM语句来让用户主动执行对某个astore表(或某个库中所有的astore表)及其上的索引进行中量级清理。中量级清理过程中,不阻塞相关表的查询和DML操作。由于在astore表中,新、老版本元组是混合存储的,因此,与顺带执行的轻量级清理相比,astore表的中量级清理需要进行全表顺序(或索引)扫描,才能识别出所有待清理的老版本元组。对于扫描出来的确认要清理的元组,会首先清理索引中的元组,然后再清理堆表中的元组,从而可以避免出现索引空指针的问题。
中量级清理的对外接口是lazy_vacuum_rel函数,内部逐层调用lazy_scan_rel、lazy_scan_heap和heap_page_prune(同轻量级清理)来扫描和暂存几类待清理的元组。当待清理的元组积攒到一定数量之后(受maintenance_work_mem内存上限控制),先后调用lazy_vacuum_index接口和lazy_vacuum_heap接口来分别清理索引文件和堆表文件。其中,与堆表页面将元组指针置为UNUSED不同,索引页面直接删除被清理的元组指针,并进行页面重整。
中量级清理的关键数据结构是LVRelStats结构体,定义代码如下:
typedef struct LVRelStats {
bool hasindex; /* 表上是否有索引 */
/* 统计信息 */
BlockNumber old_rel_pages; /* 之前的页面个数统计 */
BlockNumber rel_pages; /* 当前的页面个数统计 */
BlockNumber scanned_pages; /* 已经扫描的页面个数 */
double scanned_tuples; /* 已经扫描的元组个数 */
double old_rel_tuples; /* 之前的元组个数统计 */
double new_rel_tuples; /* 当前的元组个数统计 */
BlockNumber pages_removed;
double tuples_deleted;
BlockNumber nonempty_pages; /* 最后一个非空页面的页面号加1 */
/* 待清理的元组的行号信息(已排序) */
int num_dead_tuples; /* 当前待清理的元组个数 */
int max_dead_tuples; /* 单次最多可记录的待清理元组个数 */
ItemPointer dead_tuples; /* 待清理元组行号数组 */
int num_index_scans;
TransactionId latestRemovedXid;
bool lock_waiter_detected;
BlockNumber* new_idx_pages;
double* new_idx_tuples;
bool* idx_estimated;
Oid currVacuumPartOid;
} LVRelStats;
其中hasindex表示该表是否有索引表,num_dead_tuples表示目前已经积攒的要清理的元组,dead_tuples是保存这些元组位置的TID数组,max_dead_tuples是根据maintenance_work_mem计算出来的单次允许积攒的最大待清理元组个数。
需要指出的是,如果在元组更新时就把老版本元组集中存储,那么清理时就无须全表扫描,只需要清理集中存储的老版本元组页面即可,这样可以有效降低清理过程带来的I/O开销,使得整体存储引擎的I/O开销和性能更平稳,这也是后续openGauss版本将支持的ustore行存储格式的设计出发点。
3. 重量级堆页面和索引页面清理
无论是轻量级清理,或是中量级清理,都只能局部清理astore页面中的死亡元组,无法真正实现对这些空闲空间的释放(被清理出的空间,仍然只能被该表使用)。因此,openGauss还提供了VACUUM FULL语句来让用户主动执行对某个astore表(或某个库中所有astore表)及其上的索引进行重量级清理。重量级清理将一个表中所有仍未死亡(但是可能已经被删除)的元组重新紧密插入到新的堆表文件中并在此基础上重新创建所有索引,从而实现对空闲空间的彻底回收。在重量级清理的主体流程中只允许用户执行只读查询操作,在重量级清理的提交流程中只读查询操作也会被阻塞。
为了尽可能提高重新创建的索引性能,如果用户堆表上有索引,那么上述全表扫描会采用索引扫描。
重量级清理的对外接口是cluster_rel函数,内部逐层调用rebuild_relation、copy_heap_data、tableam_relation_copy_for_cluster、heapam_relation_copy_for_cluster、copy_heap_data_internal、reform_and_rewrite_tuple、rewrite_heap_tuple。其中,“rewrite_heap_tuple”接口将每一条扫描的未死亡元组进行重构(去除被删除的字段)之后,插入到新的紧密排列的堆表中。在这个过程中,对原来多个元组之间的更新链关系采用两个哈希表来进行暂存。当一对更新元组的双方都扫描到之后,就进行新表的填充,并将更新后元组的新的TID(transaction ID,事务ID)保存到更新前的元组中。上述机制保证重量级清理过程中并发更新事务的执行机制不会受到破坏。
重量级清理的关键数据结构是RewriteStateData结构体,其定义代码如下:
typedef struct RewriteStateData {
Relation rs_old_rel; /* 源表 */
Relation rs_new_rel; /* 整理后的目标表 */
Page rs_buffer; /* 当前整理的源表页面 */
BlockNumber rs_blockno; /* 当前写入的目标表页面号 */
bool rs_buffer_valid; /* 当前缓冲区是否有效 */
bool rs_use_wal; /* 整理操作是否产生日志 */
TransactionId rs_oldest_xmin; /* 用于可见性判断的最老活跃事务号 */
TransactionId rs_freeze_xid; /* 用于元组冻结判断的事务号 */
MemoryContext rs_cxt; /* 哈希表内存上下文 */
HTAB *rs_unresolved_tups; /* 未匹配的更新前元组版本 */
HTAB *rs_old_new_tid_map; /* 未匹配的更新后元组版本 */
/* 元组压缩相关信息 */
PageCompress *rs_compressor;
Page rs_cmprBuffer;
HeapTuple *rs_tupBuf;
Size rs_size;
int rs_nTups;
bool rs_doCmprFlag;
/* 异步-同步读写相关 */
char *rs_buffers_queue; /* adio write queue */
char *rs_buffers_queue_ptr; /* adio write queue ptr */
BufferDesc *rs_buffers_handler; /* adio write buffer handler */
BufferDesc *rs_buffers_handler_ptr; /* adio write buffer handler ptr */
int rs_block_start; /* adio write start block id */
int rs_block_count; /* adio write block count */
} RewriteStateData;
其中,rs_old_rel是被清理的表,rs_new_rel是清理之后的表,rs_oldest_xmin是判断元组是否死亡的xid阈值,rs_freeze_xid是判断是否进行freeze操作的xid阈值。rs_unresolved_tups是保存一对更新元组中老元组的哈希表,rs_old_new_tid_map是保存一对更新元组中新元组的哈希表,这两个成员共同保证更新链信息不被丢失(在原表中更新后的元组的物理位置可能比更新前的元组的物理位置还要小)。
最后,重量级操作实际上是一种数据重聚簇操作,对于其他行存储子格式和cstore列存储格式同样适用,只是具体实现机制略有不同。
