





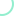
本文通过对业务模型、系统架构、StarRocks数据导入方式进行简要说明,最后列出了SR 2022年对大数据的一些支持计划。
注: 文中内容由StarRocks官方公布资料整理而成;
业务架构图来自Apache doris。
本文仅限技术交流,如有侵权请联系作者(wx: landnow)删除。


业务模型
Apache Doris业务模型图
StarRocks是什么?
StarRocks是新一代极速全场景MPP数据库。
StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果,在业界实践的基础上,进一步改进优化、升级架构,并增添了众多全新功能,形成了全新的企业级产品。
StarRocks致力于构建极速统一分析体验,满足企业用户的多种数据分析场景,支持多种数据模型(明细模型、聚合模型、更新模型),多种导入方式(批量和实时),可整合和接入多种现有系统(Spark、Flink、Hive、 ElasticSearch)。
StarRocks兼容MySQL协议,可使用MySQL客户端和常用BI工具对接StarRocks来进行数据分析。
StarRocks采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持10PB级别的数据分析; 支持MPP框架,并行加速计算; 支持多副本,具有弹性容错能力。
StarRocks采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;使用向量化执行方式,充分挖掘多核CPU的并行计算能力,从而显著提升查询性能。
StarRocks系统架构
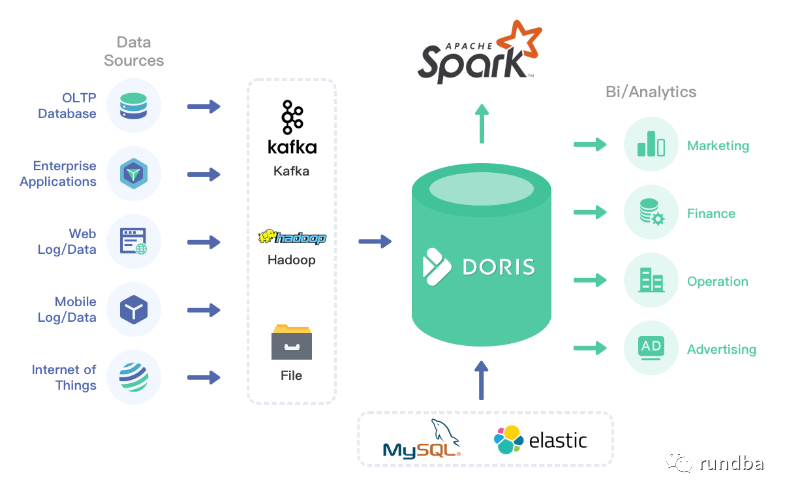
2.1 系统架构图
StarRocks系统架构图
2.2 组件介绍
StarRocks集群由FE和BE构成, 可以使用MySQL客户端访问StarRocks集群。
2.2.1 FE
FE接收MySQL客户端的连接, 解析并执行SQL语句。
管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。元数据的读写满足顺序一致性。FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
FE协调数据导入, 保证数据导入的一致性。
2.2.2 BE
BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
BE受FE指导, 创建或删除子表。
BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
BE后台执行compact任务, 减少查询时的读放大。
数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
2.2.3 其他组件
管理平台, 在后面会专门的章节介绍。
Hdfs Broker: 用于从Hdfs中导入数据到StarRocks集群,见数据导入章节。
支持数据导入方式
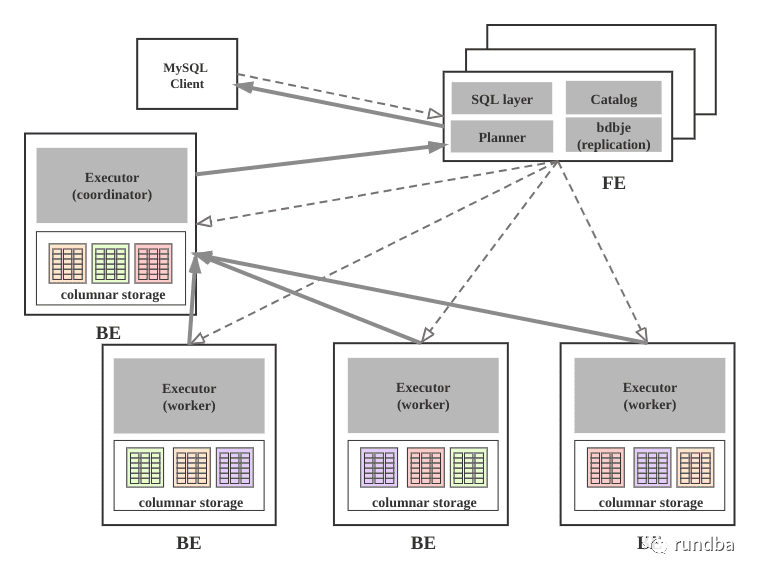
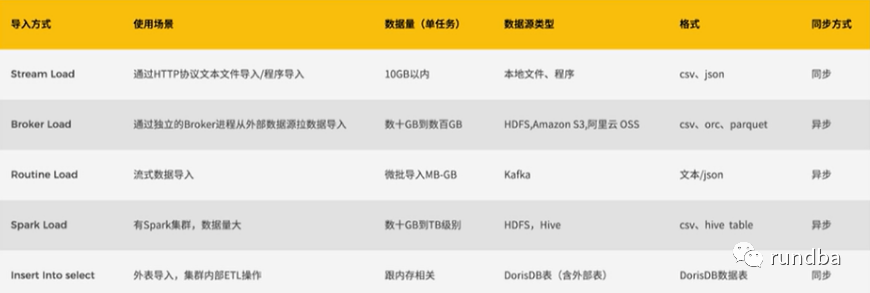
3.1 支持的数据导入方式
StarRocks数据导入
根据不同的数据来源可以选择不同的导入方式:
离线数据导入,如果数据源是Hive/HDFS,推荐采用Broker Load导入, 如果数据表很多导入比较麻烦可以考虑使用Hive外表直连查询,性能会比Broker load导入效果差,但是可以避免数据搬迁,如果单表的数据量特别大,或者需要做全局数据字典来精确去重可以考虑Spark Load导入。
实时数据导入,日志数据和业务数据库的binlog同步到Kafka以后,优先推荐通过Routine load 导入StarRocks,如果导入过程中有复杂的多表关联和ETL预处理可以使用Flink处理以后用stream load写入StarRocks,我们有标准的Flink-connector可以方便Flink任务使用。
程序写入StarRocks,推荐使用Stream Load,可以参考例子中有Java/Python/Shell的demo。
文本文件导入推荐使用 Stream load
Mysql数据导入,推荐使用Mysql外表,insert into new_table select * from external_table 的方式导入
其他数据源导入,推荐使用DataX导入,我们提供了DataX-starrocks-writer
StarRocks内部导入,可以在StarRocks内部使用insert into tablename select的方式导入,可以跟外部调度器配合实现简单的ETL处理。
3.2 大数据平台和StarRocks数据导入
3.2.1 本地文件导入-Stream load
数据存储在本地文件中,数据量小于10GB,可采用Stream Load方法将数据快速导入StarRocks系统。采用HTTP协议创建导入作业,作业同步执行,用户可通过HTTP请求的返回值判断导入是否成功。
3.2.2 HDFS导入-Broker Load
源数据存储在HDFS中,数据量为几十GB到上百GB时,可采用Broker Load方法向StarRocks导入数据。此时要求部署的Broker进程可以访问HDFS数据源。导入数据的作业异步执行,用户可通过SHOW LOAD命令查看导入结果。
源数据存储在HDSF中,数据量达到TB级别时,可采用Spark Load方法向StarRocks导入数据。此时要求部署的Spark进程可以访问HDFS数据源。导入数据的作业异步执行,用户可通过SHOW LOAD命令查看导入结果。
对于其它外部数据源,只要Broker或Spark进程能读取对应数据源,也可采用Broker Load或Spark Load方法导入数据。
3.2.3 Kafka导入-Routine Load
数据来自于Kafka等流式数据源,需要向StarRocks系统导入实时数据时,可采用Routine Load方法。用户通过MySQL协议创建例行导入作业,StarRocks持续不断地从Kafka中读取并导入数据。
3.2.4 Spark Load
Spark Load 通过外部的 Spark 资源实现对导入数据的预处理,提高 StarRocks 大数据量的导入性能并且节省 StarRocks 集群的计算资源。主要用于初次迁移、大数据量导入 StarRocks 的场景(数据量可到TB级别)。
Spark Load 是一种异步导入方式,用户需要通过 MySQL 协议创建 Spark 类型导入任务,并可以通过 SHOW LOAD 查看导入结果。
3.3 其它方式数据导入
3.3.1 Insert Into 导入
Insert Into 语句的使用方式和 MySQL 等数据库中 Insert Into 语句的使用方式类似。但在 StarRocks 中,所有的数据写入都是 一个独立的导入作业 ,所以这里将 Insert Into 也作为一种导入方式介绍。
3.3.2 Json数据导入
1) 介绍
对于一些半结构化的比如Json类型的数据,我们可以用stream load 或者 routine load的方式进行导入。
2) 使用场景
Stream Load:对于文本文件存储的Json数据,我们可以使用 stream load进行导入。
Routine Load:对于Kafka中的json格式数据,可以使用Routine load的方式导入。
3.3.3 Flink Connector
flink的用户想要将数据sink到StarRocks当中,但是flink官方只提供了flink-connector-jdbc, 不足以满足导入性能要求,为此我们新增了一个flink-connector-starrocks,内部实现是通过缓存并批量由stream load导入。
3.3.4 Datax writer
StarRocksWriter 插件实现了写入数据到 StarRocks 的目的表的功能。在底层实现上,StarRocksWriter 通过Stream load以csv或 json 格式导入数据至StarRocks。内部将reader读取的数据进行缓存后批量导入至StarRocks,以提高写入性能。总体数据流是 source -> Reader -> DataX channel -> Writer -> StarRocks。
3.4 导入方式对比
对大数据平台的增强(2022年度)
4.1 极速数据湖分析
当前 StarRocks 更多承载的是数据仓库的能力。用户会把价值含量更高的数据导入到 StarRocks 中完成极速分析。价值含量不高的原始数据都存放在数据湖中。综合来看,用户既有针对数据湖数据的极速分析需求,也有数仓数据与数据湖数据的关联分析需求。
为了能够让用户具备更好的湖仓分析体验。StarRocks 将在新的一年里重点增强数据湖分析能力。我们期待通过 StarRocks 的努力,不仅能实现用户对数据湖进行极速的分析,也能够让用户通过 StarRocks 完成数据湖与数据仓库的统一分析。据传本年度将实现StarRocks直接查询hive的功能。
当前 StarRocks 社区已经联合阿里云完成了支持 Iceberg 查询的第一期开发工作。从最新的测试效果上看相比于 Trino 会有5倍的性能提升。未来还会陆续完成对 Hudi的支持,以及完善更多的功能。StarRocks 诚挚的邀请社区有兴趣的小伙伴参与进来共同建设。与此同时,在1月份阿里云 EMR 即将开启 StarRocks 服务公测,更多云厂商的服务也在路上,敬请期待!
4.2 批流一体化
不少用户都期待将 StarRocks的极速能力用于数据加工处理场景(比如当前用 Spark 或者 Flink 完成的 WorkFlow),甚至已经有不少用户已经在这条路上开始了真正的实践。
StarRocks 会在2022年增强批处理以及流处理的能力(这并不意味着会解决所有用户的所有批处理场景)。在数百台节点规模下,StarRocks 非常有信心能够提供流批一体解决方案。这样用户既可以通过StarRocks完成对于原始数据的加工,同时加工后的数据又可以StarRocks分析。届时,通过StarRocks,用户将可以打通数据极速处理到数据极速分析的链路,从而实现更多层面的统一。
旨在交流,不足之处,还望抛砖。
作者:王坤,微信公众号:rundba,欢迎转载,转载请注明出处。
如需公众号转发,请联系wx: landnow。


