




1、背景
业务方需求如下背景,流水中的数据是没有详细信息,需要通过流水中id字段去关联维表补全其余信息。以歌曲为例,流水中有歌曲id字段,需要补充歌曲名称、歌曲发布日期等信息。假定百亿流水,曲库维表是亿级基数,峰值qps为20w/s。
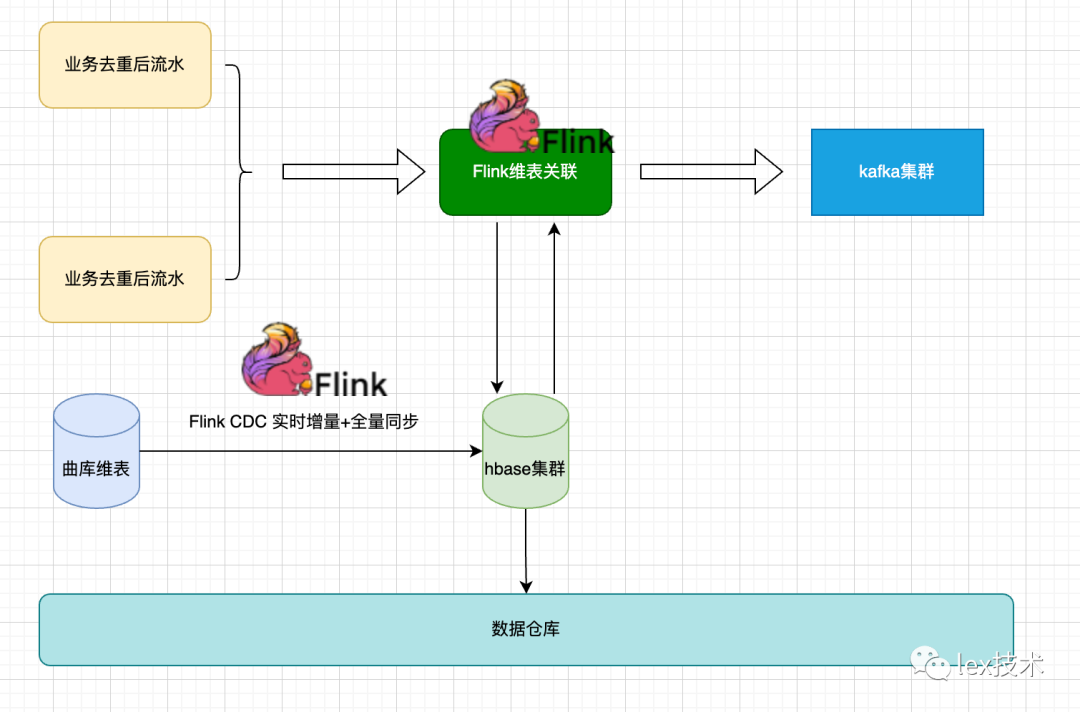
曲库维表数据由于数据量亿级,经过评估如果曲库数据都缓存在redis,内存开销大成本高,经过选型采用hbase集群进行存储。
主要原因是hbase:
有良好的写入性能、高可靠性、易扩容、容量大等特性。
数据本地化较好,可以减少网络传输开销。我们的Flink维表关联任务、Flink CDC任务跑在yarn上,hbase的HFile是存储在hdfs上。hdfs、yarn、hbase混合部署且在同一机房。
Hbase维度数据可以方便同步到数仓(hive集群),提供离线链路关联使用。
2、Flink维表关联性能方案
流水峰值每秒20w/s,每条数据都要补全维度数据。需要在两个方面进行优化。
1)hbase get请求耗时要低。
预先对hbase大表进行分区。目前预分区大小为80,可以显著改善全量写入hbase速度。
扩容hbase集群规模,8台32core/64G region server服务器。提高BucketCache缓存大小,且采用堆外内存。堆内采用G1垃圾回收器。
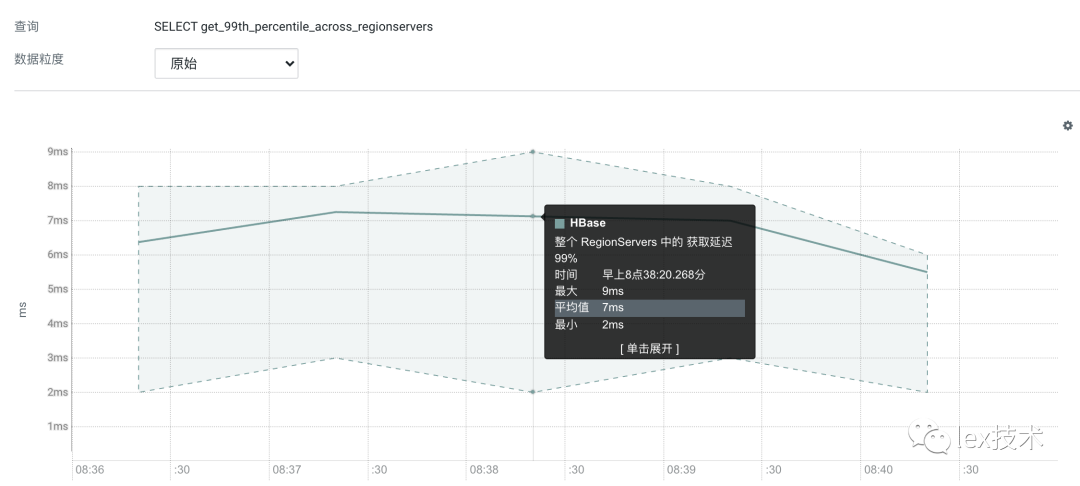
经过上述等优化使得读请求耗时均值在8ms左右。
2)关联任务异步化。
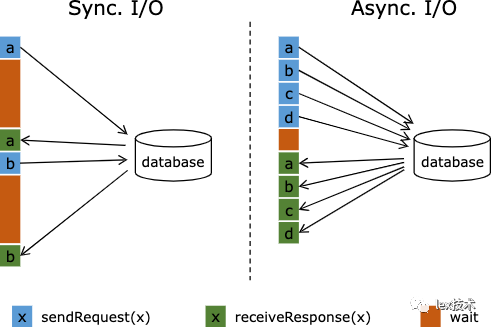
由上可知hbase get请求在8ms,采用同步方式进行关联,1个并行度1秒最多处理1000/8=125条记录。要支持20w/s的流水,需要的并行度巨大。主要原因我们采用了同步IO,一个hbase读请求耗时8ms,在这段时间内一直在等待请求返回结果,不能处理其他的流水记录。flink提供了异步IO支持。如下图所示,一个并行函数实例可以并发地处理多个请求和接收多个响应。这样,函数在等待的时间可以发送其他请求和接收其他响应。这样等待的时间可以被多个请求进行摊分。大多数情况下,异步交互可以大幅度提高流处理的吞吐量。
3)缓存优化。
曲库中有上亿级歌曲,但是真正活跃的歌曲数量不多,并且歌曲的维表数据变化较小,不必每个请求都去访问hbase集群获取结果。可以在flink任务中设置缓存,数据直接从缓存中获取维表数据,减少访问hbase次数。并且可以通过flink keyBy算子将数据按照歌曲id维度进行分组。这样使得每个Flink Task只需要加载分区范围内的缓存数据,可以显著提升缓存命中率。
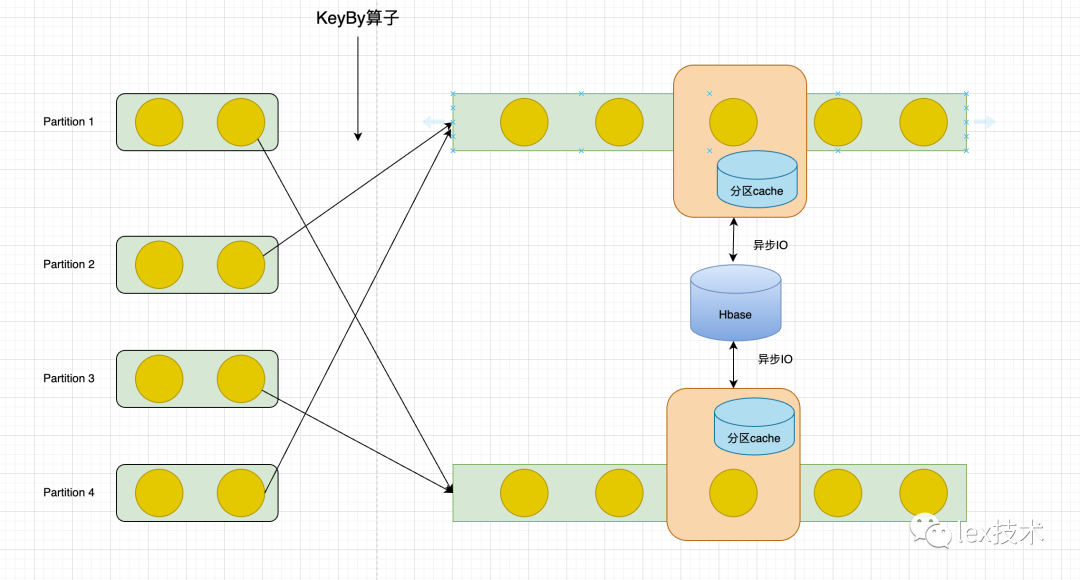
3、优化实践
1)rowkey设计
rowkey的设计对于hbase读写来说较为关键。有几个原则,长度原则、唯一原则、排序原则、散列原则。
长度原则:长度尽量越短越好,尽量设计成定长,可以减少hfile的存储和提高内存的有效利用率。
唯一原则:rowkey用来唯一标识一行记录,所以必须保证 rowkey的唯一性。
排序原则:rowkey是按照字典顺序排序存储。可以充分利用排序的特点,将经常读取的数据存储到一起,将最近可能被访问的数据放到一块。
散列原则:rowkey需要尽可能均匀的分布到各个 RegionServer。避免大量数据集中到某个RegionServer上,造成热点问题。
最开始我们设计的rowkey方式是:固定是11位,将歌曲id反转后补0。发现有时候,全量写入时候,某些region所在节点负载很高,FGC很频繁。FGC耗时很久,无法及时响应实时任务读取请求,导致出现读取超时。原因是hbase数据不太均衡,有些region数据量很大,有些很小。且目前rowkey都是数字,导致有些region是空的数据。
Caused by: java.util.concurrent.TimeoutException: Async function call has timed out.
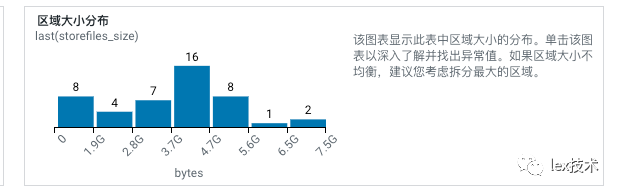
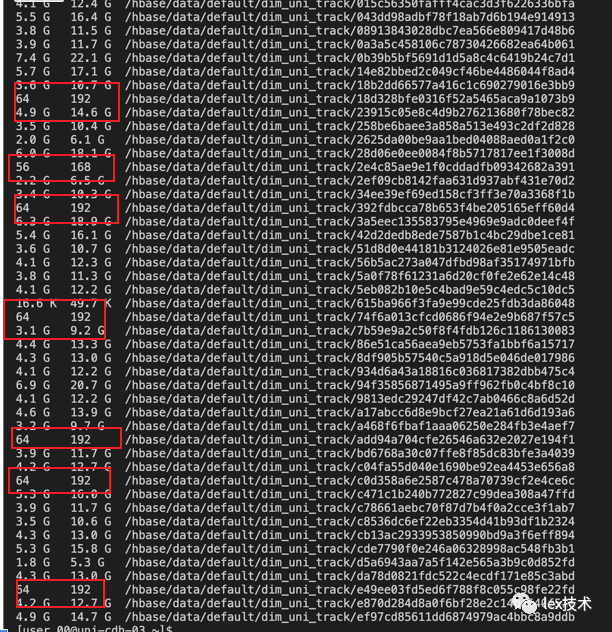
后续将rowkey的高3位设置为:歌曲id进行hash散列然后截取3位。经过调整以后region数据分布比较均衡。使得读写都比较均衡,不至于某个节点集中出现大量的写入和读取。
2)、Flink异步化改造
a、异步hbase改造
笔者实践的时间是在2021年4月,当时最新版本是flink1.12,flink未提供异步化的Hbase连接器。因此需要自己进行改造适配。异步 I/O 交互需要支持异步请求的数据库客户端。如果没有异步化的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端。不过,这种方法通常比异步客户端效率低不少。
线程池方式:
@Overridepublic void asyncInvoke(final Integer input, final ResultFuture<String> resultFuture) {executorService.submit(() -> {Get get = new Get(Bytes.toBytes(row));// 发送同步请求,接收 future 结果List<String> ret = hbase.get(get);resultFuture.complete(ret);} catch (InterruptedException e) {resultFuture.complete(new ArrayList<>(0));}});}
异步客户端方式:
public void asyncInvoke(String row, final ResultFuture<String> result) throws Exception {Get get = new Get(Bytes.toBytes(row));// 发送异步请求,接收 future 结果ListenableFuture<Result> future = hbase.asyncGet(get);Futures.addCallback(future, new FutureCallback<Result>() {public void onSuccess(Result result) {List<String> ret = process(result);result.complete(ret);}public void onFailure(Throwable thrown) {result.completeExceptionally(thrown);}});}
经过调研,我们选择了asynchbase客户端。asynchbase(Asynchronous HBase)是完全异步,非阻塞的,线程安全的,高性能的 HBase 客户端。
不过需要注意一点,需要采用自定义的NioClientSocketChannelFactory类,因为默认的该客户端默认的NioClientSocketChannelFactory是CustomChannelFactory,该类在close时候,并不会释放该Factory管理的连接资源(socket fd)。这样会导致大量的socket fd一直被占用没有关闭,导致出现java.io.IOException: Too many open files。
HBaseClient类中:
/** A custom channel factory that doesn't shutdown its executor. */private static final class CustomChannelFactoryextends NioClientSocketChannelFactory {CustomChannelFactory(final Executor executor) {super(executor, executor);}@Overridepublic void releaseExternalResources() {// Do nothing, we don't want to shut down the executor.}}
b、缓存优化
在本地缓存的使用上,我们选择了Caffeine,而不是Guava缓存。主要是由于我们的流水中有大量的是热歌(周杰伦的歌)。Caffeine 采用了一种结合 LRU、LFU 优点的算法:W-TinyLFU,其特点是:高命中率、低内存占用。对于那些短时间内高频的歌曲能够不容易被淘汰,可以显著地提升缓存命中率。
c、异步队列优化
经过上述异步化改造、hbase集群读写优化后、使用Caffeine缓存。在hbase维表数据只有400万数据的时候,维表关联任务性能可达30w/s。
当hbase表数据在亿级时,维表关联任务出现严重背压,维表关联性能急剧下降,吞吐量维持在2.7w/s左右。原因是hbase表数据在400万时,表的数据都存储在hbase的读缓存中,99%的请求耗时在1ms以内。而用真实线上维表数据时,99%的请求耗时在10ms左右。

经过线上jstack分析堆栈,发现线程总是卡在AsyncWaitOperator中的addToWorkQueue方法中。
"LookupJoin(table=[default_catalog.default_database.dim_uni_track], joinType=[InnerJoin], async=[true], lookup=[rowkey=$f30], select=[report_time, client_ip, platform, version, user_id, device_id, openudid, network_type, user_status, hardware_info, timestamp, user_ip, id, uni_id, mv_id, playtime, $f30, rowkey, tb]) -> Calc(select=[report_time, client_ip, CAST(_UTF-16LE'100000':VARCHAR(2147483647) CHARACTER SET "UTF-16LE") AS app_id, CAST(1) AS cmd, platform, version, user_id, device_id, openudid, network_type, user_status, hardware_info, timestamp, user_ip, id, uni_id, mv_id, playtime, CAST(tb.duration) AS duration]) (32/50)#0" Id=79 cpuUsage=0.68% deltaTime=1ms time=2947ms WAITING on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@410fa325at sun.misc.Unsafe.park(Native Method)- waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@410fa325at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at org.apache.flink.streaming.runtime.tasks.mailbox.TaskMailboxImpl.take(TaskMailboxImpl.java:146)at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxExecutorImpl.yield(MailboxExecutorImpl.java:78)at org.apache.flink.streaming.api.operators.async.AsyncWaitOperator.addToWorkQueue(AsyncWaitOperator.java:258)at org.apache.flink.streaming.api.operators.async.AsyncWaitOperator.processElement(AsyncWaitOperator.java:180)at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:193)at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:179)at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:152)at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:67)at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:372)at org.apache.flink.streaming.runtime.tasks.StreamTask$$Lambda$192/1338658580.runDefaultAction(Unknown Source)at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:186)at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:575)at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:539)at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:722)at org.apache.flink.runtime.taskmanager.Task.run(Task.java:547)at java.lang.Thread.run(Thread.java:748)
经过源码分析,异步IO有两种输出模式,有序和无序。LookUp维表异步join默认是以异步IO有序输出。因此本文以有序模式来分析,AsyncWaitOperator中有一个队列。该队列默认大小为100,如图元素1、3暂未向hbase发送get请求;元素4已向hbase发送get请求,但是请求未返回;元素2、元素5发送已接收请求结果,因此Emiter会从队列中取出元素5然后发生到下游。而元素2虽然也获取结果,但是只有等元素3、4、5都发射以后才能向下游发送。

而我们的代码总卡在addToWorkQueue中,说明该队列早已经满了,但是还有元素没有处理掉(受限于Hbase访问耗时)。因此,将该队列大小调大可使得并行处理性能大大增强。经过压测将队列大小table.exec.async-lookup.buffer-capacity设置为5000时,维表关联性能在50+w/s,图中是3000+w/min。

本文,讲述了通过hbase优化、rowkey设计优化、缓存优化、异步化改造和调优异步队列等手段,将维表关联性能提升到50w/s。
参考文档:
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/datastream/operators/asyncio/
https://xie.infoq.cn/article/3f8918d3ef064b7b6b2382e1b
http://wuchong.me/blog/2017/05/17/flink-internals-async-io/
