




1、背景
业务方需求如下背景,需要对几个亿级基数的维度进行天去重。举例如下,用户维度、歌曲(或者文章、电影本文以歌曲为例)、行为(播放、收藏、分享等行为)。用户维度基数假定亿级、歌曲维度基数假定亿级、行为基数20。需求是对某个用户在某首歌播放次数超过10次以后的进行去重。
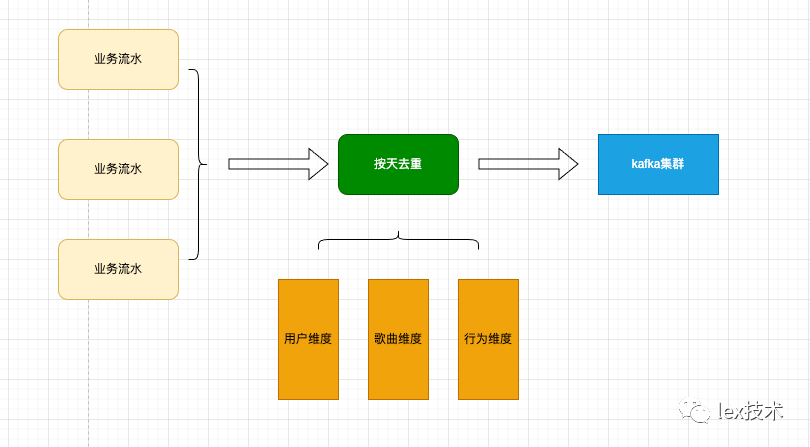
2、去重方案
一般flink去重的话有几种方式可选择。
布隆过滤器,不过由于布隆过滤器有误差,所以我们这里并没有采用。
引入外部存储比如redis、hbase,即将各个维度数据组合作为key,一天次数作为value。经过计算一天大概是500G量。由于redis成本较大,并且涉及网络io,以及引入外部组件的不稳定性,该没有采取该方案。
Flink RocksDb状态后端去重。该方案是Flink自身保证,稳定性高,并且RocksDb是存储在本地磁盘。存储量大、并且不涉及网络IO。而且Flink sql 原生支持row number方式去重,Sql方式维护方便。因此最终我们选择了此方案。
3、Flink Sql 去重
如下Flink sql提供了标准去重语法
SELECT [column_list]FROM (SELECT [column_list],ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownumFROM table_name)WHERE rownum <= N [AND conditions]
| 参数 | 说明 |
|---|---|
| ROW_NUMBER() | 计算行号的OVER窗口函数。行号从1开始计算。 |
| PARTITION BY col1[, col2..] | 可选。指定分区的列,即去重的KEYS。 |
| ORDER BY timeAttributeCol asc desc | 指定排序的列,必须是一个的字段(即Proctime或Rowtime)。可以指定顺序(Keep FirstRow)或者倒序 (Keep LastRow)。 |
| rownum | 外层查询中对排名进行过滤,只取前N条 |
3.1 Deduplication方式
当rownum<=1时,flink采用的是Deduplication方式进行去重。该方式有两种去重方案:有保留第一条(Deduplicate Keep FirstRow)和保留最后一条(Deduplicate Keep LastRow)2种。
Deduplicate Keep FirstRow保留首行的去重策略:保留KEY下第一条出现的数据,之后出现该KEY下的数据会被丢弃掉。因为STATE中只存储了KEY数据,所以性能较优。
SELECT *FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNumFROM T)WHERE rowNum = 1
Deduplicate Keep LastRow保留末行的去重策略:保留KEY下最后一条出现的数据。因此过程中会产生变更的记录,会下下游发送变更的消息。因此,sink表需要支持update操作。
SELECT *FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNumFROM T)WHERE rowNum = 1
Deduplicate Keep FirstRow方式去重原理是在flink中维护一个boolean类型的状态,来判断是否已经存在该记录。例如:如果对应的key不存在,则将该值设置为true,后续的记录通过key获取该值来判断是否是重复。Deduplicate Keep LastRow也是类似的实现,不过需要保留最后一个的记录,且会产生变更的记录。
/*** Processes element to deduplicate on keys with process time semantic, sends current element if* it is first row.** @param currentRow latest row received by deduplicate function* @param state state of function* @param out underlying collector*/static void processFirstRowOnProcTime(RowData currentRow, ValueState<Boolean> state, Collector<RowData> out)throws Exception {checkInsertOnly(currentRow);// ignore record if it is not first rowif (state.value() != null) {return;}state.update(true);// emit the first row which is INSERT messageout.collect(currentRow);}
3.2 top N 方式
3.2.1 去重原理
经典的TopN算法:从已经存在的数组中,找出最大(或最小)的前n个元素。算法(以找最大的n个元素为例):
取出数组的前n个元素,创建长度为n的小根堆;
从n开始循环数组的剩余元素,如果当前元素比小根堆的根节点大,则将当前元素设置成小根堆的根节点,并通过调整让堆保持小根堆;
循环完成后,小根堆中的所有元素就是需要找的最大的n个元素;
根据需要对小根堆中的所有元素继续利用堆排序算法进行排序。
最终,堆中的结果就是top N。
flink 也是采用一个类似处理,每一个需要去重的key,维护了一个堆,然后对后续对应key过来的数据更新这个堆。这些堆信息存储在flink状态中。
3.2.2 去重策略
AppendFast:结果只追加,不更新;
Retract:类似于回撤流,结果会更新,前提是输入数据没有主键,或者主键与partitionKey不同;
UpdateFast:快速更新,前提是输入数据有主键,且结果单调递增/递减,还要求orderKey的排序规则与结果的单调性相反(例:ORDER BY sum(quantity) DESC )。可见它的效率最高,但是也最苛刻。
3.2.3 状态保存
前面可以看到,去重是基于状态实现的。因此,控制好状态的大小,即可以实现按照1 hour 1day等进行去重。如下所示:
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build());tEnv.getConfig().setIdleStateRetention(Duration.ofDays(1));
4、Flink sql改造
由于我们的场景比较特殊,不需要求出top N数据,只需要按照时间过滤掉当天出现N次以后的数据即可。因此,这种场景可以进行优化,在flink中维护一个integer的状态。对于同一个key值,用integer来统计次数,如果次数大于指定的值,则丢弃该数据,否则保留该数据并且状态值+1。这种方式只用了一个integer类型的值,来替代一个具有N个元素的堆。时间和空间复杂度大大减低。(该方案由jerry哥提出和改造)
部分代码如下:

@Overridepublic void processElement(RowData input, Context context, Collector<RowData> out)throws Exception {initRankEnd(input);// check message should be insert only.Preconditions.checkArgument(input.getRowKind() == RowKind.INSERT);int currentRank = state.value() == null ? 0 : state.value();// ignore record if it does not belong to the first-n rowsif (currentRank >= rankEnd) {return;}currentRank += 1;state.update(currentRank);if (outputRankNumber) {collectInsert(out, input, currentRank);} else {collectInsert(out, input);}}
5、Flink sql问题
初始去重sql如下:
select SELECT_COLUMNS from(select SELECT_COLUMNSfrom(SELECT *, ROW_NUMBER() OVER (PARTITION BY song_id, user_id, cmd, FLOOR(proc_time TO day) order by proc_time asc ) as row_numfrom tableAwhere cmd = 1 and user_id > 0 and playtime >=(duration*0.8) and duration>0)where row_num <=10)union all(select SELECT_COLUMNS from(SELECT *, ROW_NUMBER() OVER (PARTITION BY song_id, user_id, cmd, FLOOR(proc_time TO day) order by proc_time asc) as row_numfrom tableAwhere cmd = 2 and user_id > 0 and playtime >=(duration*0.8) and duration>0)where row_num <=3)union all(select SELECT_COLUMNS fromSELECT *, ROW_NUMBER() OVER (PARTITION BY song_id, user_id, cmd, FLOOR(proc_time TO day) order by proc_time asc) as row_numfrom tableAwhere cmd =3 and user_id > 0 and playtime >=(duration*0.8) and duration>0)where row_num <= 1)
如上述sql所示。cmd是行为(假定为1是播放歌曲、2是收藏歌曲、3是分享歌曲),PARTITION BY后的是不同的维度歌曲、用户、行为、日期(天去重)。对同一个table的不同的行为进行不同的次数的去重,然后将去重后的结果union起来,就是我们的数据结果。
5.1 sql union问题
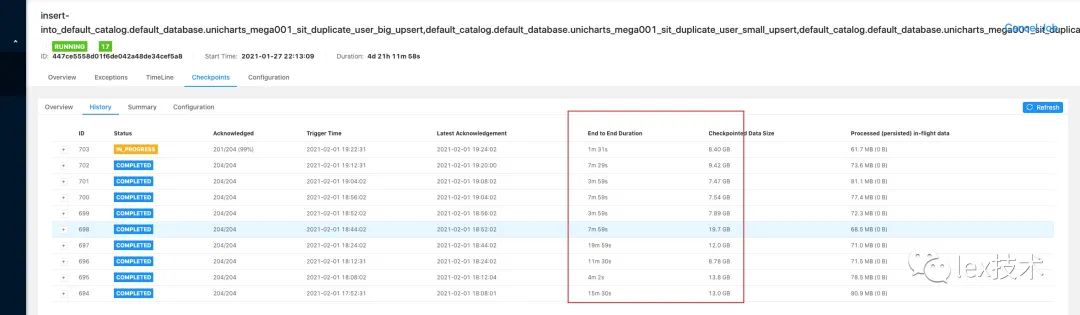
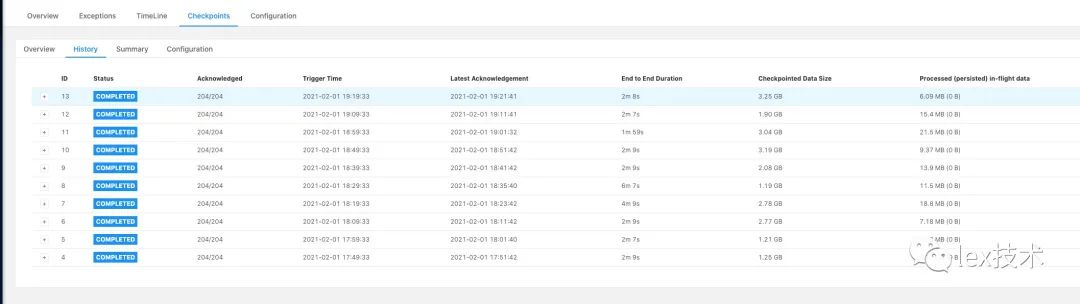
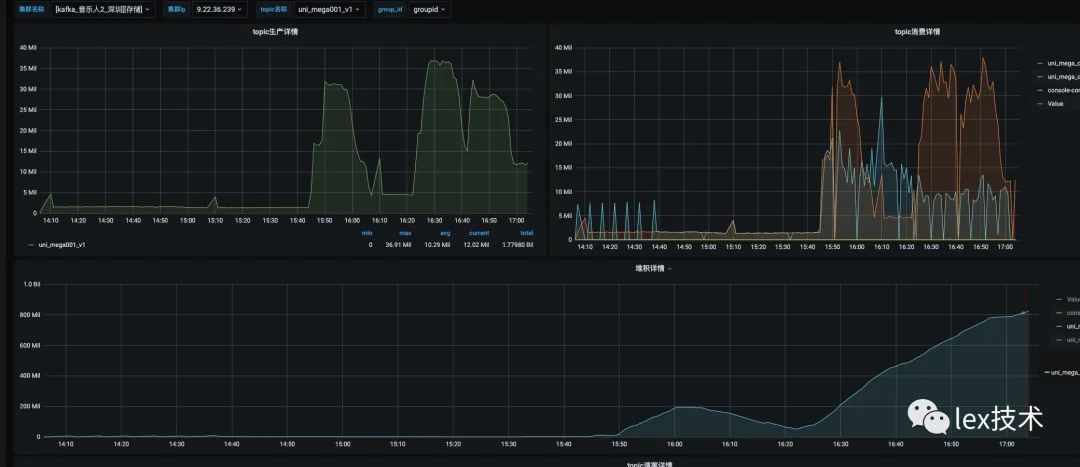
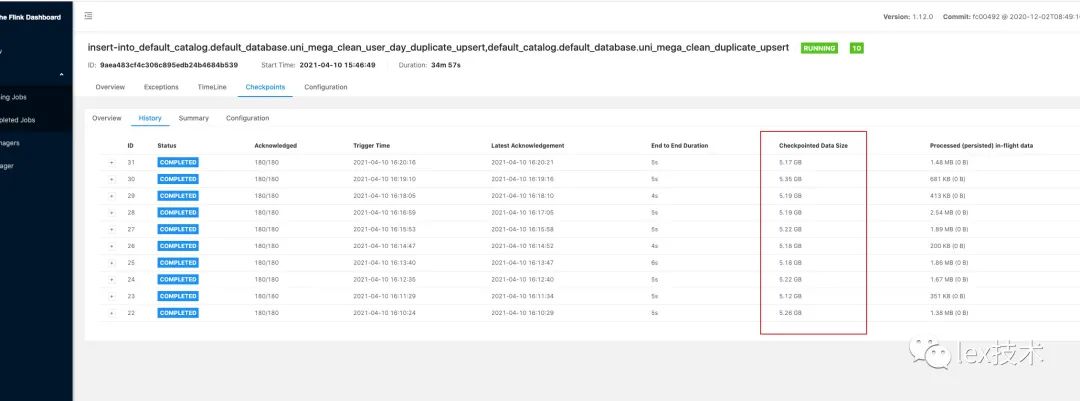
最开始时union all写成了union,发现性能极低,flink operator中出现了GroupAggregate算子,且是对所有的字段进行group by。分析原因是由于使用union关键字。union关键字不允许重复,会对结果再次进行去重,union相当于 union all + distinct。因此,后续改成了union all将各个cmd行为下的去重结果合并。如下图所示,状态明显降低。
union状态:
修改为union all的状态:
另外写sql的时候,有小伙伴过滤条件是写在外层,导致状态中存储了大量无效的key。比如如下过滤条件: user_id > 0 and playtime >=(duration*0.8) and duration>0。可以过滤大量的脏数据,但是如果放在外层,将会导致里层的ROW_NUMBER() OVER PARTITION BY 时,会将大量的脏数据也加入到状态中了。
select SELECT_COLUMNS fromSELECT *, ROW_NUMBER() OVER (PARTITION BY song_id, user_id, cmd, FLOOR(proc_time TO day) order by proc_time asc) as row_numfrom tableAwhere cmd =3)where row_num <= 1 and user_id > 0 and playtime >=(duration*0.8) and duration>0
6、flink性能优化
6.1 flink背压问题解决
对应的sql已经写好,提交到集群上运行。作业运行2个小时后,发现有严重背压。
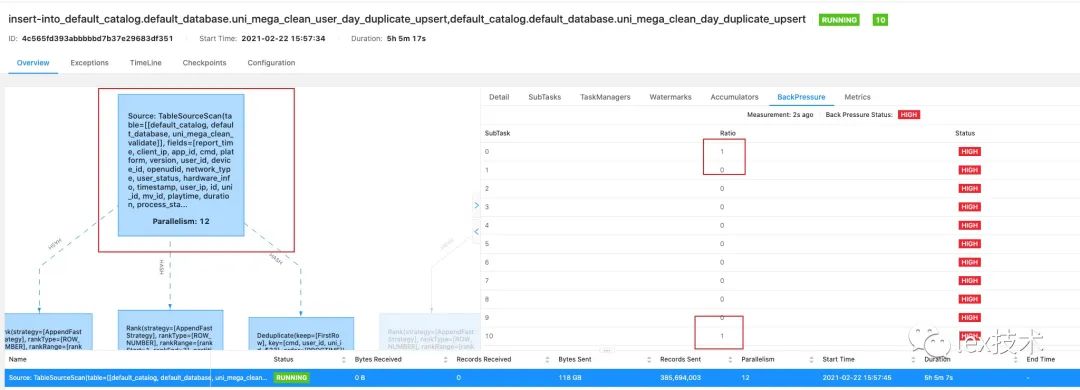
通过arthas命令代码总是在执行backend.db.get(),也就是在执行从状态中获取状态值。如前所述,flink会把PARTITION BY后的各个维度的组合为key,value为对应的key出现的次数。每来一条记录,都会去状态中获取key对应的value(次数),来判断该条记录是否被丢弃。
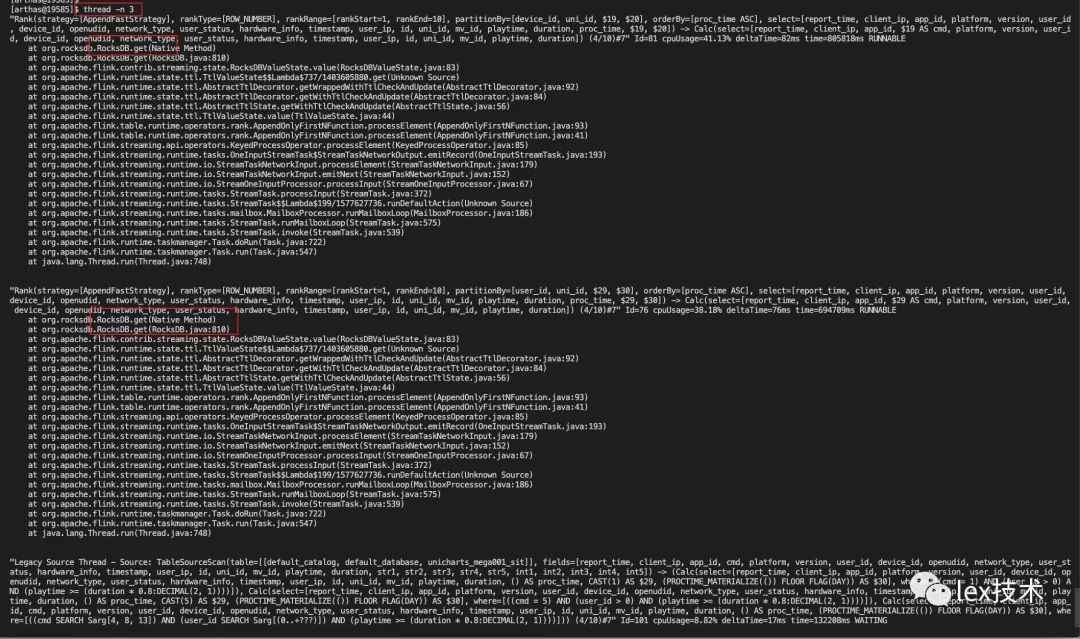
AppendOnlyFirstNFunction.processElement()-->RocksDBValueState.value()-->backend.db.get()
AppendOnlyFirstNFunction类:
@Overridepublic void processElement(RowData input, Context context, Collector<RowData> out)throws Exception {initRankEnd(input);// check message should be insert only.Preconditions.checkArgument(input.getRowKind() == RowKind.INSERT);Integer stateValue = state.value();int currentRank = stateValue == null ? 0 : stateValue;// ignore record if it does not belong to the first-n rowsif (currentRank >= rankEnd) {return;}currentRank += 1;state.update(currentRank);if (outputRankNumber) {collectInsert(out, input, currentRank);} else {collectInsert(out, input);}}
RocksDBValueState类
@Overridepublic V value() {try {byte[] valueBytes = backend.db.get(columnFamily,serializeCurrentKeyWithGroupAndNamespace());if (valueBytes == null) {return getDefaultValue();}dataInputView.setBuffer(valueBytes);return valueSerializer.deserialize(dataInputView);} catch (IOException | RocksDBException e) {throw new FlinkRuntimeException("Error while retrieving data from RocksDB.", e);}}
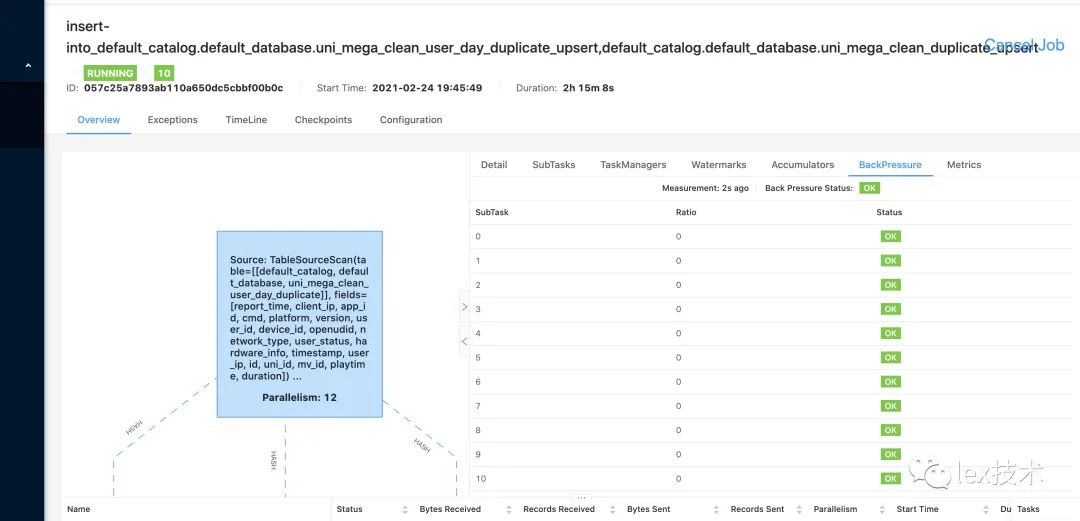
该db.get该函数是由rocksdb提供,是否可以增加缓存来提升速度。如下图所示,能否增大rocksdb缓存来提升rocksdb读性能。查询rocksdb缓存设置,发现flink rocksdb的读缓存(state.backend.rocksdb.block.cache-sizeblock)默认为8MB,设置的太小,导致大量的读打到磁盘。随机增加flink taskManger内存,并将state.backend.rocksdb.block.cache-sizeblock内存设置为512MB。

调整flink内存和rocksdb读缓存以后,flink作业背压解决。
6.2 flink beyond the 'PHYSICAL' memory limit.
如上调优以后,运行2天左右,作业内存超过了yarn容器分配的物理内存的限制,被yarn kill掉了。
2021-02-25 06:49:25,593 WARN akka.remote.transport.netty.NettyTransport [] - Remote connection to [null] failed with java.net.ConnectException: Connection refused: hadoop02.tcd.com/9.44.33.8:608992021-02-25 06:49:25,593 WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://flink@hadoop02.tcd.com:60899] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://flink@hadoop02.tcd.com:60899]] Caused by: [java.net.ConnectException: Connection refused: hadoop02.tcd.com/9.44.33.8:60899]2021-02-25 06:49:32,762 INFO org.apache.flink.runtime.resourcemanager.active.ActiveResourceManager [] - Worker container_e26_1614150721877_0021_01_000004 is terminated. Diagnostics: [2021-02-25 06:49:31.879]Container [pid=24324,containerID=container_e26_1614150721877_0021_01_000004] is running 103702528B beyond the 'PHYSICAL' memory limit. Current usage: 4.1 GB of 4 GB physical memory used; 6.3 GB of 8.4 GB virtual memory used. Killing container.Dump of the process-tree for container_e26_1614150721877_0021_01_000004 :|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE|- 24551 24324 24324 24324 (java) 1130639 94955 6799687680 1073522 /usr/java/jdk1.8.0_131/bin/java -Xmx1664299798 -Xms1664299798 -XX:MaxDirectMemorySize=493921243 -XX:MaxMetaspaceSize=268435456 -Dlog.file=/data4/yarn/container-logs/application_1614150721877_0021/container_e26_1614150721877_0021_01_000004/taskmanager.log -Dlog4j.configuration=file:./log4j.properties -Dlog4j.configurationFile=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner -D taskmanager.memory.framework.off-heap.size=134217728b -D taskmanager.memory.network.max=359703515b -D taskmanager.memory.network.min=359703515b -D taskmanager.memory.framework.heap.size=134217728b -D taskmanager.memory.managed.size=1438814063b -D taskmanager.cpu.cores=1.0 -D taskmanager.memory.task.heap.size=1530082070b -D taskmanager.memory.task.off-heap.size=0b --configDir . -Djobmanager.rpc.address=hadoop02.tcd.com -Djobmanager.memory.jvm-overhead.min=201326592b -Dpipeline.classpaths= -Dtaskmanager.resource-id=container_e26_1614150721877_0021_01_000004 -Dweb.port=0 -Djobmanager.memory.off-heap.size=134217728b -Dexecution.target=embedded -Dweb.tmpdir=/tmp/flink-web-30926c2a-4700-49a4-89d6-6b8485785ae8 -Dinternal.taskmanager.resource-id.metadata=hadoop03.tcd.com:8041 -Djobmanager.rpc.port=54474 -Dpipeline.jars=file:/data1/yarn/nm/usercache/user_00/appcache/application_1614150721877_0021/container_e26_1614150721877_0021_01_000001/unipro-interval-index-stat-v2-1.0-SNAPSHOT.jar -Drest.address=hadoop02.tcd.com -Djobmanager.memory.jvm-metaspace.size=268435456b -Djobmanager.memory.heap.size=1073741824b -Djobmanager.memory.jvm-overhead.max=201326592b|- 24324 24315 24324 24324 (bash) 1 0 11046912 372 /bin/bash -c /usr/java/jdk1.8.0_131/bin/java -Xmx1664299798 -Xms1664299798 -XX:MaxDirectMemorySize=493921243 -XX:MaxMetaspaceSize=268435456 -Dlog.file=/data4/yarn/container-logs/application_1614150721877_0021/container_e26_1614150721877_0021_01_000004/taskmanager.log -Dlog4j.configuration=file:./log4j.properties -Dlog4j.configurationFile=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner -D taskmanager.memory.framework.off-heap.size=134217728b -D taskmanager.memory.network.max=359703515b -D taskmanager.memory.network.min=359703515b -D taskmanager.memory.framework.heap.size=134217728b -D taskmanager.memory.managed.size=1438814063b -D taskmanager.cpu.cores=1.0 -D taskmanager.memory.task.heap.size=1530082070b -D taskmanager.memory.task.off-heap.size=0b --configDir . -Djobmanager.rpc.address='hadoop02.tcd.com' -Djobmanager.memory.jvm-overhead.min='201326592b' -Dpipeline.classpaths='' -Dtaskmanager.resource-id='container_e26_1614150721877_0021_01_000004' -Dweb.port='0' -Djobmanager.memory.off-heap.size='134217728b' -Dexecution.target='embedded' -Dweb.tmpdir='/tmp/flink-web-30926c2a-4700-49a4-89d6-6b8485785ae8' -Dinternal.taskmanager.resource-id.metadata='hadoop03.tcd.com:8041' -Djobmanager.rpc.port='54474' -Dpipeline.jars='file:/data1/yarn/nm/usercache/user_00/appcache/application_1614150721877_0021/container_e26_1614150721877_0021_01_000001/unipro-interval-index-stat-v2-1.0-SNAPSHOT.jar' -Drest.address='hadoop02.tcd.com' -Djobmanager.memory.jvm-metaspace.size='268435456b' -Djobmanager.memory.heap.size='1073741824b' -Djobmanager.memory.jvm-overhead.max='201326592b' 1> /data4/yarn/container-logs/application_1614150721877_0021/container_e26_1614150721877_0021_01_000004/taskmanager.out 2> /data4/yarn/container-logs/application_1614150721877_0021/container_e26_1614150721877_0021_01_000004/taskmanager.err[2021-02-25 06:49:31.896]Container killed on request. Exit code is 143[2021-02-25 06:49:31.908]Container exited with a non-zero exit code 143.
同时发现虚拟内存占用挺大,于是顺便解决了一下glibc Thread Arena 问题,flink-conf.yaml中添加该参数containerized.taskmanager.env.MALLOC_ARENA_MAX: 1。不过没啥作用,真正原因是物理内存超用了。
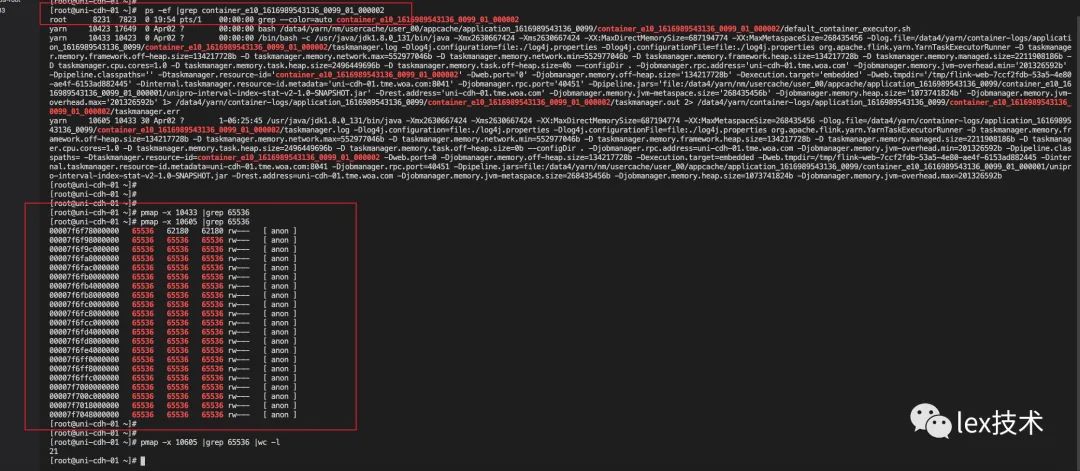
只好通过tcmalloc来分析一下task的堆外内存,经过安装tcmalloc工具。将对应的内存都dump下来观察。没发现啥异常。。。推测是不是由于rocksdb的内存不可控,导致超用了物理内存。因此,降rocksdb缓存有512MB降低到128MB,同时将flink manager内存增加。

在此时,偶然发现flink状态并没有按天过期被清理。导致state不停地在增加。
6.3 flink状态定期清理
flink中有两种状态清理机制:Flink State TTL 机制、Idle State Retention Time 。
目前该去重算子采用Flink State TTL 机制。该机制默认方案是:需要再次访问,才能清理过期的状态。而我们这里按照flink状态中key包含的是LOOR(proc_time TO day)时间。举个例子,今天是12月28日,那么新的flink状态中的key就会包含12月28日,而到了12月29日的记录key都是12月29日,而12月28日的key永远也不会被访问了。不能被访问那么就不会被Flink State TTL 机制清理掉。如此,flink中的状态将无限制增加。
/*** Utility to create a {@link StateTtlConfig} object.* */public class StateTtlConfigUtil {/*** Creates a {@link StateTtlConfig} depends on retentionTime parameter.* @param retentionTime State ttl time which unit is MILLISECONDS.*/public static StateTtlConfig createTtlConfig(long retentionTime) {if (retentionTime > 0) {return StateTtlConfig.newBuilder(Time.milliseconds(retentionTime)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();} else {return StateTtlConfig.DISABLED;}}}
有两种办法解决:
1、Flink State TTL 机制增加了cleanupFullSnapshot和cleanupInRocksdbCompactFilter方法进行清理老的状态,即使没有被访问。
cleanupFullSnapshot:完整快照时的过期状态剔除老的状态。
cleanupInRocksdbCompactFilter:可指定queryTimeAfterNumEntries参数。当写入多少条状态数据后,更新当前的时间戳。当 RocksDB 在后台执行 Compaction 操作时,根据当前的时间戳来判断该状态是否过期,然后过滤掉那些失效的 Key 及 Value. 如果这个值queryTimeAfterNumEntries设置的小,将会提升清理状态的速度。由于Flink 通过JNI 的方式来调用rocksdb代码的,因此频繁调用会有较大开销。
/*** Cleanup expired state while Rocksdb compaction is running.** <p>RocksDB compaction filter will query current timestamp,* used to check expiration, from Flink every time after processing {@code queryTimeAfterNumEntries} number of state entries.* Updating the timestamp more often can improve cleanup speed* but it decreases compaction performance because it uses JNI call from native code.** @param queryTimeAfterNumEntries number of state entries to process by compaction filter before updating current timestamp*/@Nonnullpublic Builder cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) {strategies.put(CleanupStrategies.Strategies.ROCKSDB_COMPACTION_FILTER,new RocksdbCompactFilterCleanupStrategy(queryTimeAfterNumEntries));return this;}
queryTimeAfterNumEntries压测发现当设置为1000时,当增加流量时,性能下降比较明显,产生明显的背压。消费lag持续增加。最终经过线上数据压测,将该值设置为100000L,达到较好的效果。
public static StateTtlConfig createTtlConfig(long retentionTime) {if (retentionTime > 0) {return StateTtlConfig.newBuilder(Time.milliseconds(retentionTime)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).cleanupFullSnapshot().cleanupInRocksdbCompactFilter(100000L).build();} else {return StateTtlConfig.DISABLED;}}
加上这两个配置后,发现老的状态已经被清理了,状态始终维持在一定大小。
2、Idle State Retention Time 机制
修改源代码,将清理机制修改为Idle State Retention Time。该机制是通过timer来清理掉老的状态,因此即使该状态没有被访问也可以被清理。但是Idle State Retention Time会将timer也加入到flink state中,导致总的状态膨胀很多。
实验对比:
Flink State TTL 机制:checkpoint周期为1分钟一次,运行20分钟checkpoint大小

Idle State Retention Time 机制:checkpoint周期为1分钟一次,运行20分钟checkpoint大小

换成idle state 以后状态膨胀了3.26倍 6.2/1.9= 3.26倍
对比发现Flink State TTL 机制状态更小,性能更加,最终采用了Flink State TTL 机制。
6.4 Rocksdb Merge调优
经过上述优化后,作业比较稳定。但是偶发性出现cpu使用率很高的情况。通过perf命令定位发现,cpu爆高时,rocksdb频繁的在做Merge操作。随机调优rocksdb merge。
state.backend.rocksdb.writebuffer.number-to-merge:默认值为 1,决定了 Write Buffer 合并的最小阈值。
state.backend.rocksdb.thread.num:默认值为1,这个参数允许用户增加最大的后台 Compaction 和 Flush 操作的线程数。提高该值可以明显提升后台merge性能。
state.backend.rocksdb.writebuffer.count:默认值为2,内存中允许保留的 MemTable 最大个数,超过count后,就会被 Flush 刷写到磁盘上成为 SST 文件。
经过线上实际压测,将值调整如下,调整以后cpu不在告警。
state.backend.rocksdb.writebuffer.number-to-merge: 2state.backend.rocksdb.thread.num: 8state.backend.rocksdb.writebuffer.count: 3
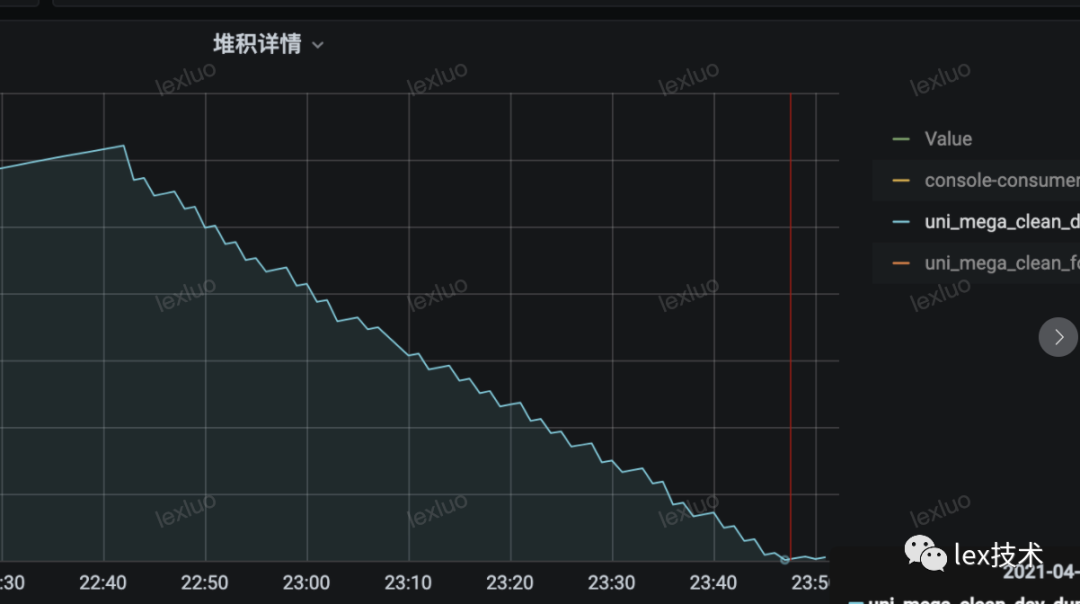
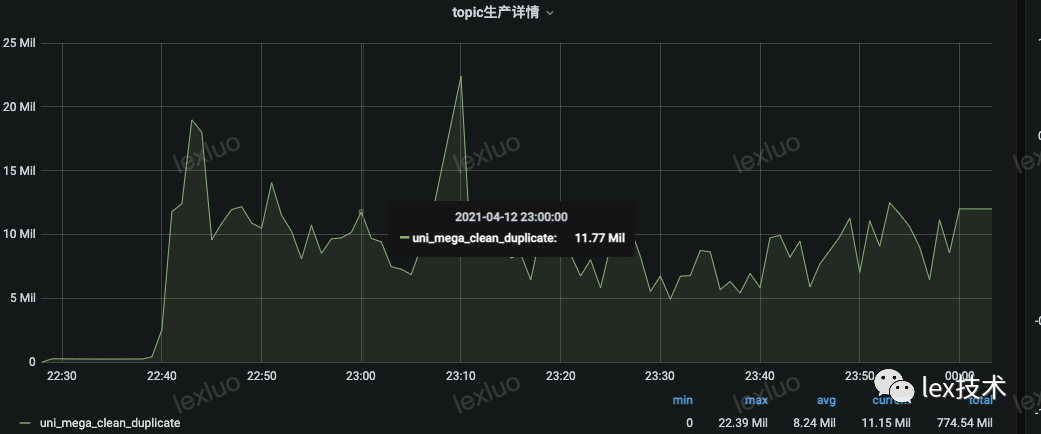
7、线上压测
18个TaskManager,TM内存10G,60亿key,checkpoint 大小250G的条件下,去重作业消费速度约:18w/s,作业是无背压、稳定。
参考文章:
https://developer.aliyun.com/article/772873
https://mp.weixin.qq.com/s?__biz=MzU3Mzg4OTMyNQ==&mid=2247490197&idx=1&sn=b0893a9bf12fbcae76852a156302de95
https://cloud.tencent.com/developer/news/755802
https://cloud.tencent.com/developer/article/1452844
