




1、背景
标签系统存储使用Doris、ES进行存储,需要定时将hive表中的标签数据导入到Doris和ES。其中Doris主要用于进行标签历史趋势查询。
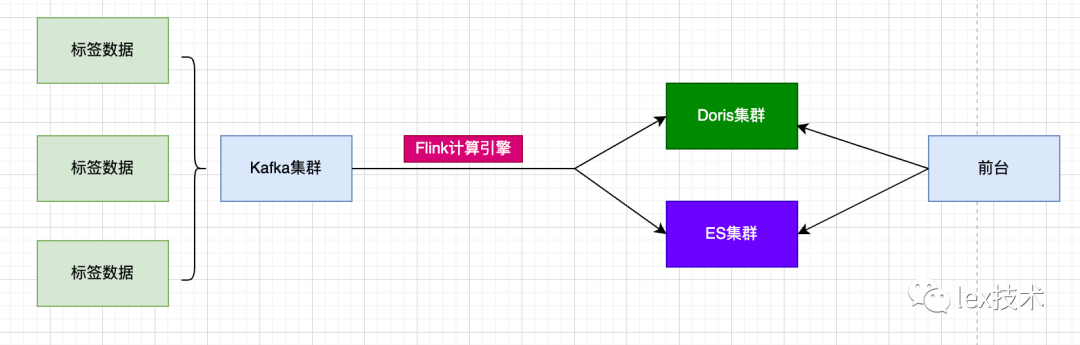 1.1 Doris工作原理
1.1 Doris工作原理
Doris 是分布式、面向交互式查询的分布式数据库。Doris 的整体架构如图所示,Doris 中的模块包括 FE(Frontend)、BE(Backend):FE 主要负责元数据的管理、存储,以及查询的解析等;一个用户请求经过 FE 解析、规划后,具体的执行计划会发送给 BE,BE 则会完成查询的具体执行。BE 节点主要负责数据的存储、以及查询计划的执行。

1.2 Doris数据导入
目前Doris 系统提供了6种不同的导入方式。Broker load、Stream load、Insert、Multi load、Routine load、通过S3协议直接导入。这里我们采用了Stream load方式进行导入。
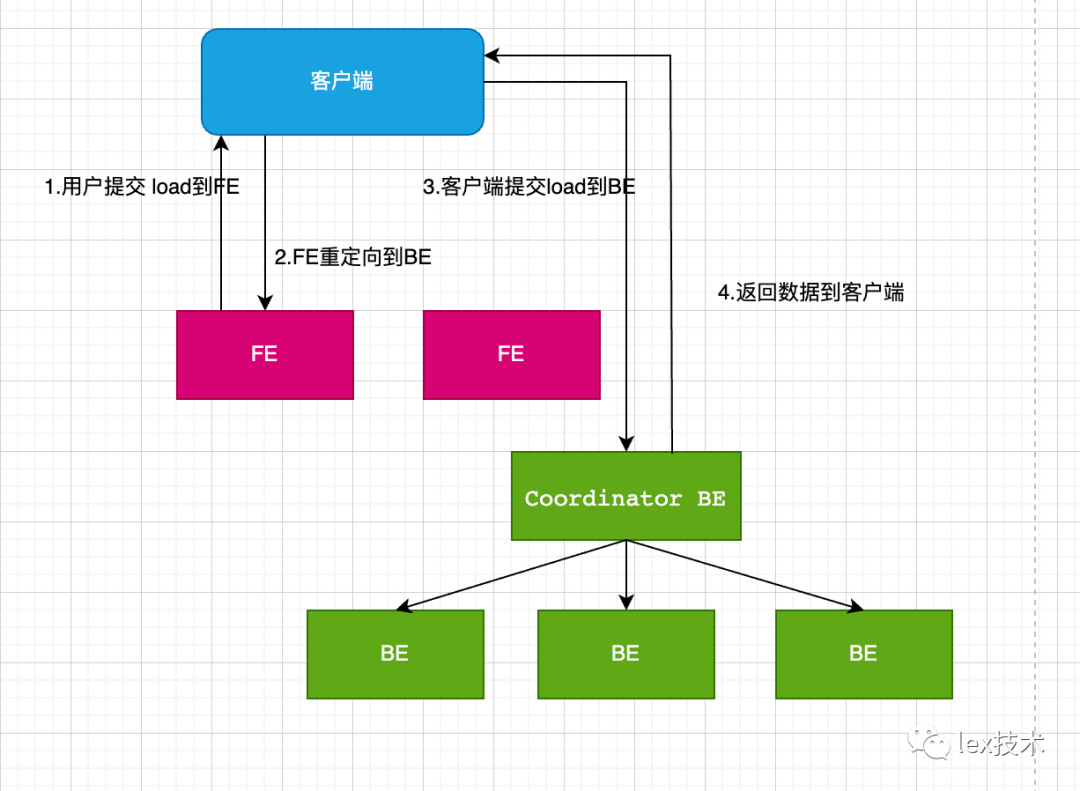
Stream load 中,Doris 会选定一个节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。导入的最终结果由 Coordinator BE 返回给用户。
1.3 标签导入需求
标签数据是来源不同的业务需要导入到不同的Doris表,并且需要支持随时增加、修改、删除标签字段。因此,一个Flink任务需要支持写入不同的Doris表,并且导入同一个表的数据包含列不一样。
2、表元数据修改优化
由于每天会自动的增删改标签,因此对应的需要对Doris表字段进行动态的增删改。发现频繁对某表进行新增字段时,会不停的报错。
s.jdbc4.MySQLSyntaxErrorException: errCode = 2, detailMessage = Table[xxxx]'s state is not NORMAL. Do not allow doing ALTER ops
优化手段:
新增前先判断是否存在,只有不存在的字段才添加
批量添加字段,一条命令添加一批待新增的字段
<update id="addTableColumns" parameterType="com.xxx.xxx.tag.service.bean.po.doris.TableColumnList">ALTER TABLE ${tableName}ADDCOLUMN<foreach collection="tableColumnInfos" index="index" item="item" open="(" separator="," close=")">${item.columnName}<choose><when test="item.columnType=='varchar'">VARCHAR(${item.columnLength}) REPLACE_IF_NOT_NULL NULL COMMENT ""</when><otherwise>${item.columnType} REPLACE_IF_NOT_NULL NULL COMMENT ""</otherwise></choose></foreach></update>
添加失败则按照失败次数和重试间隔进行重试
经过以上优化,解决了上述报错问题
3、导入优化
从Doris源码flink connector中的flink-demo看到Flink Example实例。第一步先先FE发起load请求,然后返回重定向后的BE地址,然后再向BE发送load请求。
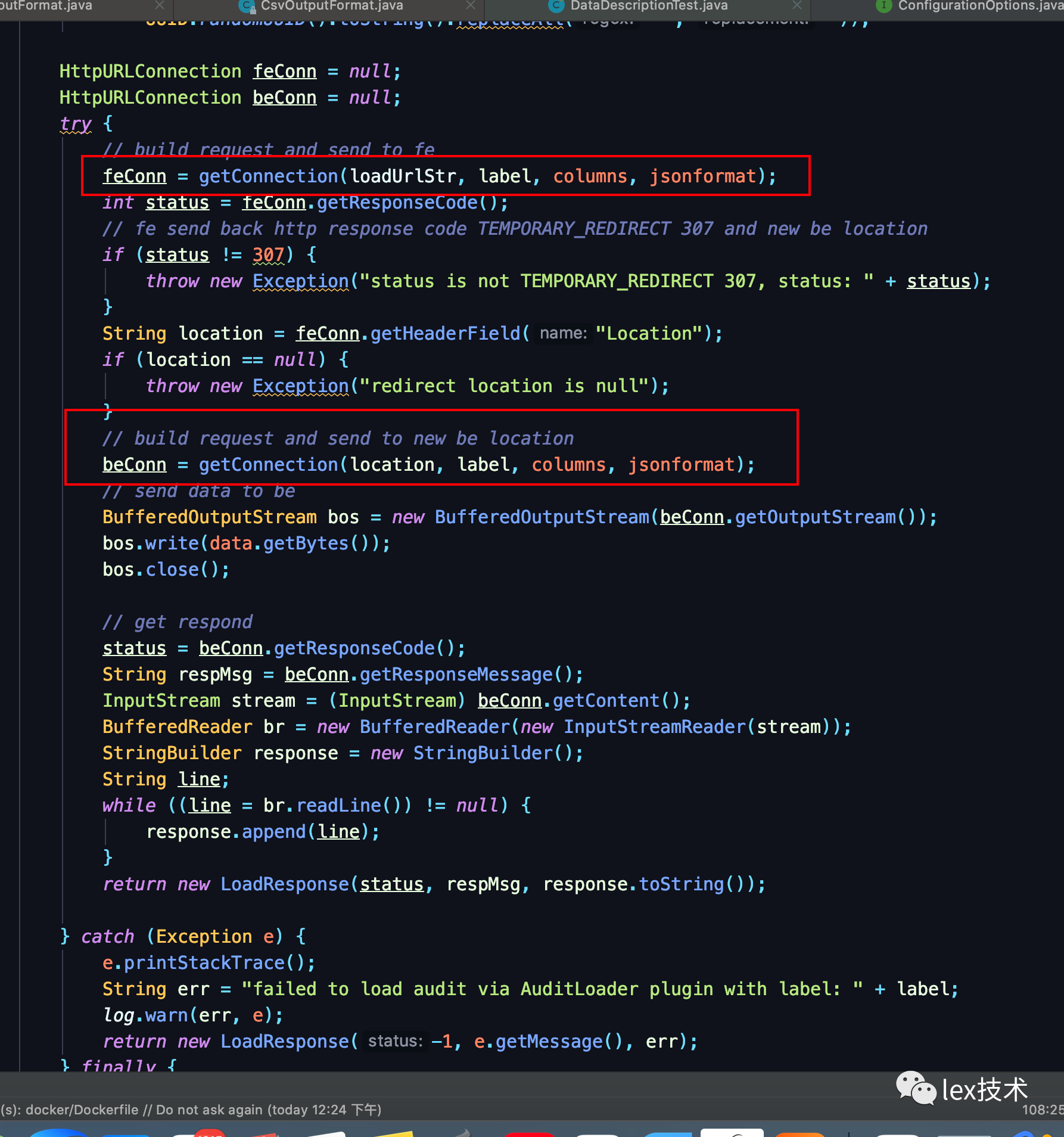
采用此方式测试写入以后,发现写入异常。
java.io.IOException: com.xxx.stream.connector.doris.exception.StreamLoadException: stream load error: close wait failed coz rpc error. NodeChannel[256816-10007], load_id=43436f36e46f9448-cdb02eaf00f03282, txn_id=203598, node=10007:8060, add batch req success but status isn't ok, err: tablet writer write failed, tablet_id=260878, txn_id=203598, err=-235, see more in nullat com.xxx.stream.connector.doris.format.DorisDynamicOutputFormat.flush(DorisDynamicOutputFormat.java:224)at com.xxx.stream.connector.doris.format.DorisDynamicOutputFormat.writeRecord(DorisDynamicOutputFormat.java:165)at com.xxx.stream.connector.doris.config.GenericDorisSinkFunction.invoke(GenericDorisSinkFunction.java:53)at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:54)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:46)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:26)at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50)at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28)at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollectWithTimestamp(StreamSourceContexts.java:322)at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collectWithTimestamp(StreamSourceContexts.java:426)at org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher.emitRecordsWithTimestamps(AbstractFetcher.java:365)at org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.partitionConsumerRecordsHandler(KafkaFetcher.java:183)at org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.runFetchLoop(KafkaFetcher.java:142)at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:826)at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:269)
同时查看BE监控页面,BE不停地做Compaction,BE IO Util很高。原因是我一次load只发送一条数据,导致导入的频率过高,大于后台数据的Compaction速度,导致数据版本推挤超过了默认500的限制。因此需要改造成批量导入数据,减少导入的频率。
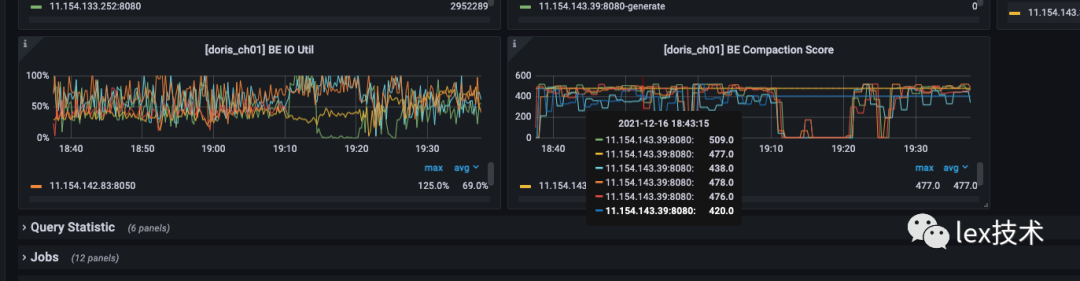
批量导入:
参考flink mysql批量写入,JdbcBatchingOutputFormat类有一个集合list,用于存放一批记录。另外open方法里创建一个线程,以间隔定时发送一批记录。即指定时间间隔如(10s)、批次大小大于(1000)时触发flush操作。特别注意,由于两个不同的线程同时操作同一个集合对象,因此需要加锁。
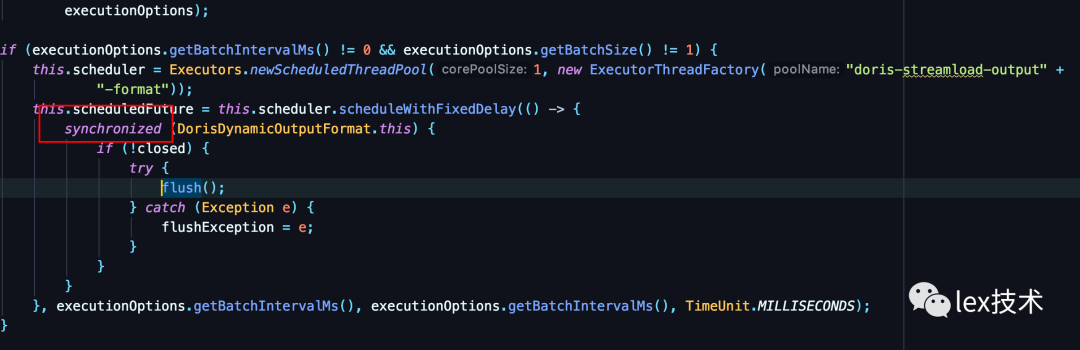
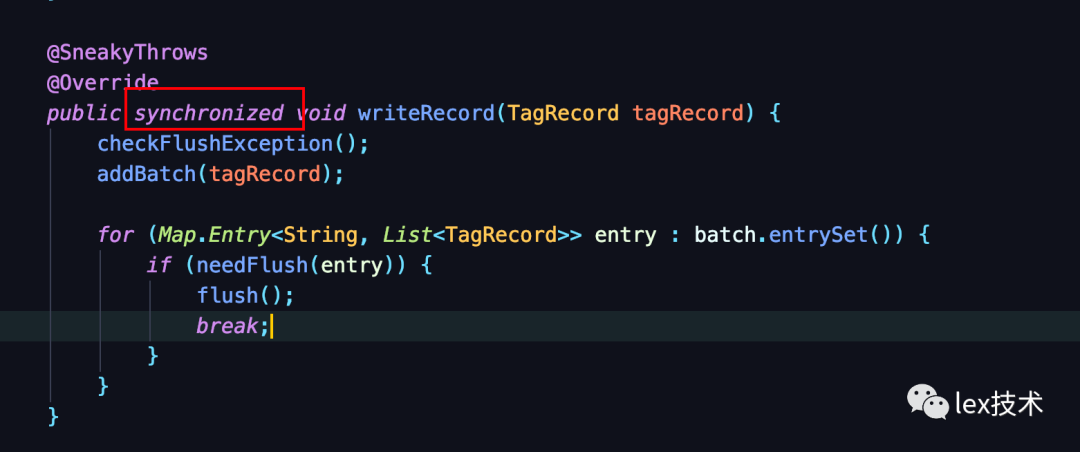 另外由于需要写入不同的Doris表。因此,需要使用一个Map来存放不同的表下的一批记录。key是Doris表,Value是待写入的一批记录集合。
另外由于需要写入不同的Doris表。因此,需要使用一个Map来存放不同的表下的一批记录。key是Doris表,Value是待写入的一批记录集合。

改造以后,batchSize设置为1000,发现还是偶尔会出现上述异常。官网建议一批导入的数据量在 1G 到 10G 之间。因此直接将批次大小设置为20w,批次间隔设置为20s。发现写入不再报错,BE IO Util、Compaction处于正常水平。2个TM,TM内存10G,写入qps达到70w/min,且消费速度有下降趋势。
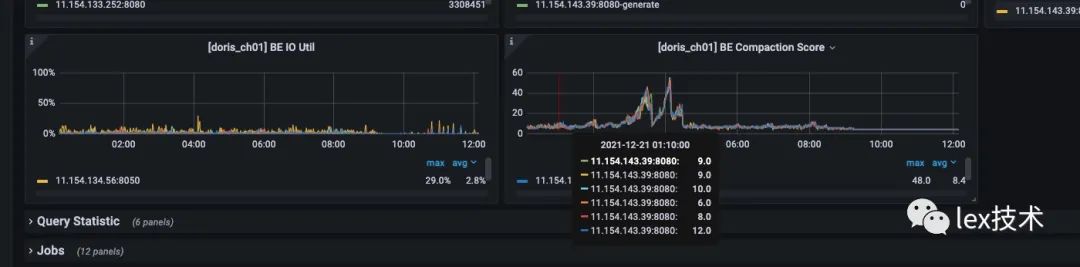
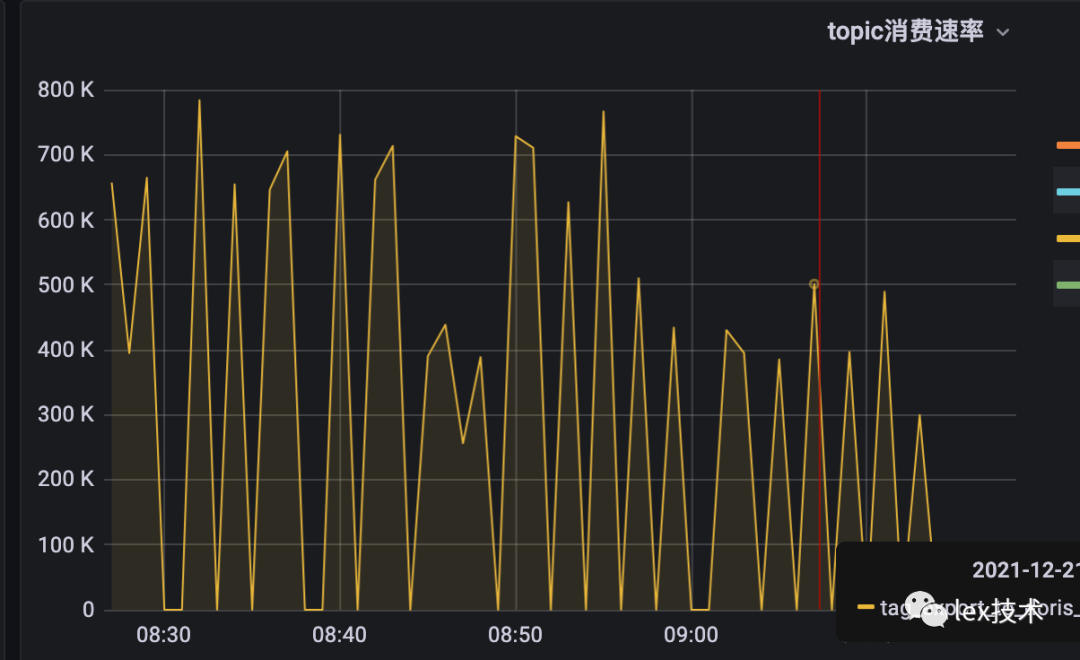
运行一段时间发现作业GC很严重,并且出现Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded。
通过Arthas工具进行定位发现,GC很严重。不停地进行YGC和FGC。业务线程执行的时间较少,导致吞吐量总上不去。
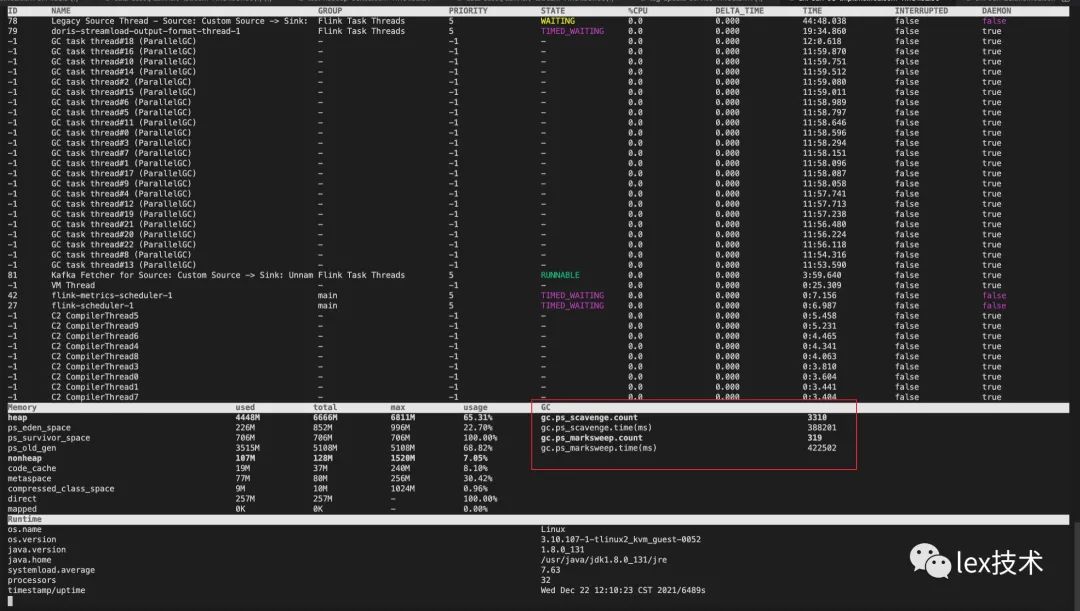
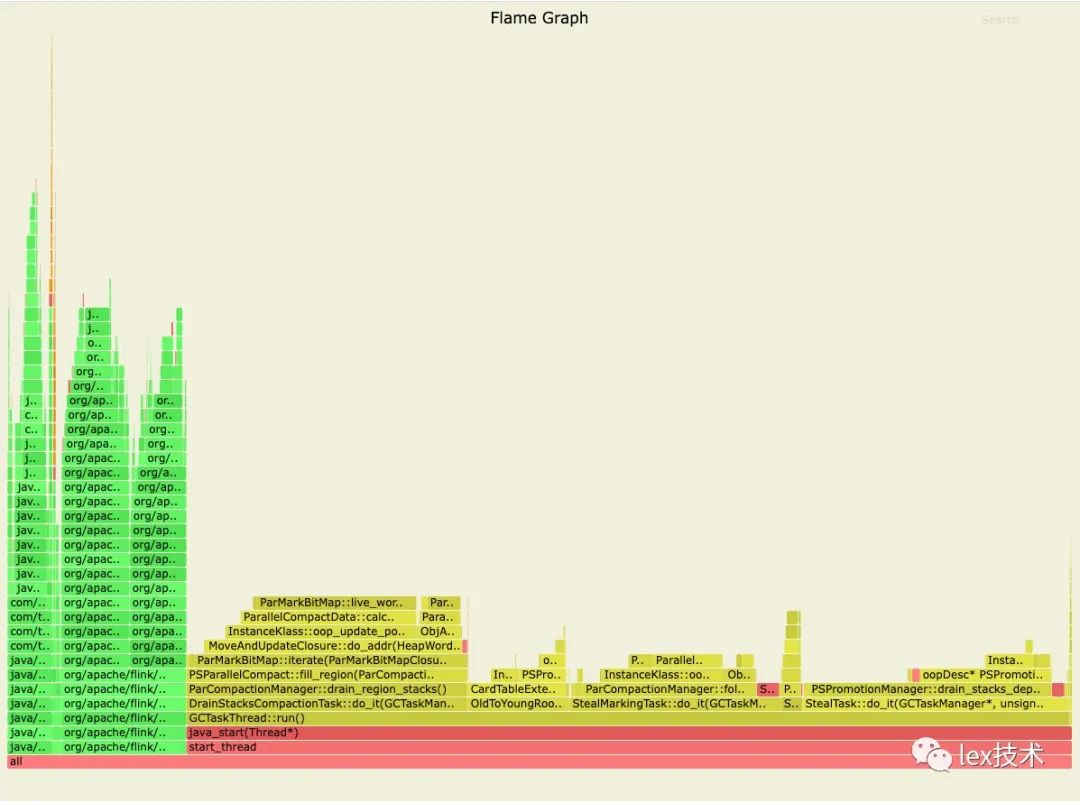
dump进程的内存进行分析,发现每条记录大小为占用内存较大,当集合较大时20w,这批数据占用内存很大。经分析是业务方录入的一大批标签,标签多值分布很大,导致一条记录存储占用较大。
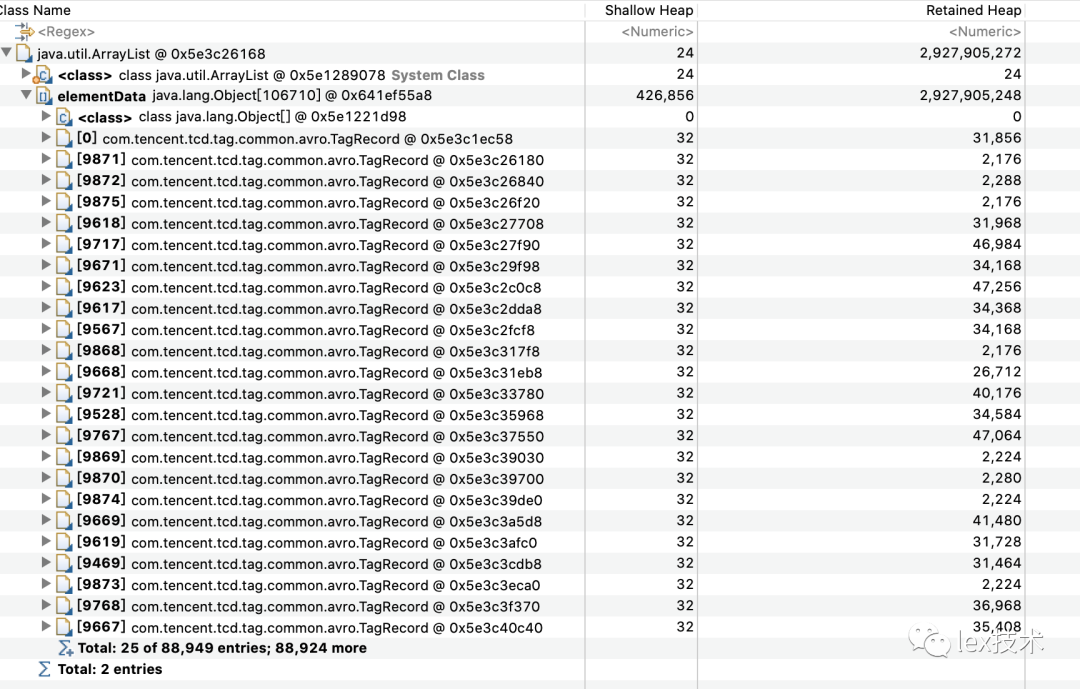

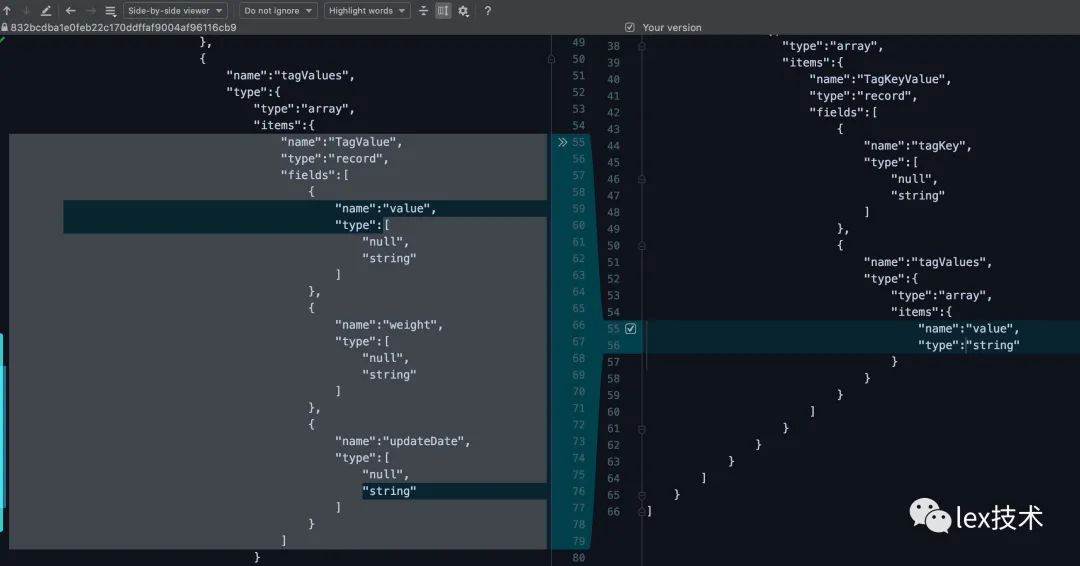
优化每条记录的avro结构,去除不必要的字段和信息,并且减少中间集合数据开销。如下图是将weigh、update_date等字段去除。
经过内存方面的调优,降低了GC,使得吞吐量大大增加。2个TM,TM内存10G,消费速度提升到583w/min。

参考文档:
https://www.jianshu.com/p/d3742af8ecce
https://segmentfault.com/a/1190000040692728
https://doris.apache.org/master/zh-CN/administrator-guide/load-data/stream-load-manual.html
