




第一章 场景分析
对于SQL的优化工作,最常用也是十分有效的手段之一,就是建立合适、高性能的索引。那对于不同场景涉及到的知识点及优化方式又分多钟情况。本篇仅从简单、常用的SQL查询来分析,如何让一条SQL更高效。衍生出复杂场景下的优化思路。
为了阐述后续的分析结果,首先要明确一个概念:可选择率。

可选择率越大,返回结果集的Cardinality越大,估算出的成本值越大。同理也可以近似的认为,实际的查询开销越大。我们重点关注的是施加谓词条件后的记录数。
那如果通过索引访问,返回的记录数都相同呢,是否可以说消耗的资源一定相同?
答案是否定的,同样访问对应索引中的数据,索引结构不同,访问的路径及扫描的索引条目均会有很大的差别,因此也就会造成性能差异明显。
由于本篇仅讨论实际的查询开销,因此后续实验对COST成本等不再做分析。仅从逻辑读维度来印证实际的开销更高还是更低。
第二章 单表查询场景
2.1 创建测试脚本:
--创建测试表t1co;
create table t1co as select * from dba_objects;
--调整列类型以便让以下实验效果更明显;
alter table t1co modify(EDITION_NAME char(500));
update t1co set EDITION_NAME=object_id;
--创建对应列上的不同顺序索引,以下用不同索引分别测试:
create index idx_t1co_own_edi on t1co(owner,EDITION_NAME);
create index idx_t1co_edi_own on t1co(EDITION_NAME,owner);
--收集统计信息:
exec dbms_stats.gather_table_stats('szt','T1CO');
2.2 等值查询
首先测试等值查询情况下,不同索引顺序查询效率是否相同:
--SQL文本如下:
select count(*) from t1co where owner='SYS' and EDITION_NAME ='200';
--查询表中施加了谓词的列值数量。
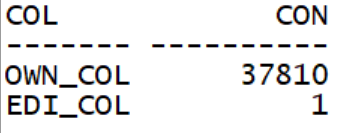
通过分析可知,OWNER列过滤性较差,EDITION_NAME列过滤性较好。如下测试采用不同的索引性能开销。


可以看到,通过不同顺序的两个索引访问,其逻辑读完全相同。思考一下索引的结构?
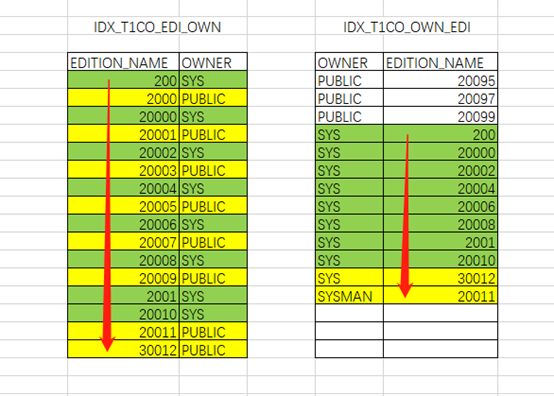
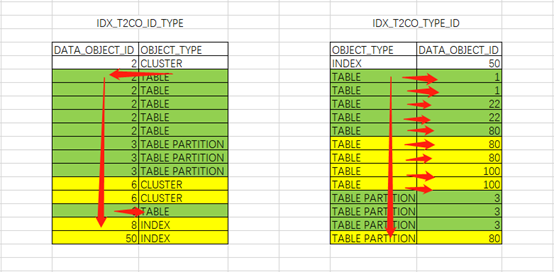
以下通过EXCEL形象的展示一下:
绿色代表扫描并满足条件的记录,黄色代表扫描但不满足条件需要过滤的记录。以下同。
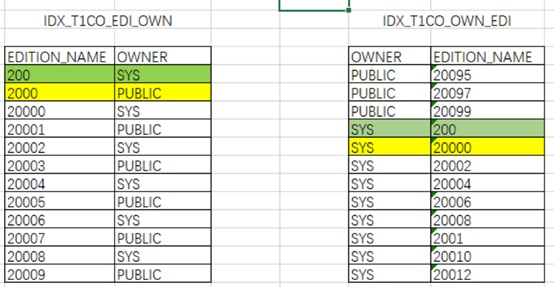
IDX_T1CO_EDI_OWN索引:
根据索引特性直接访问到两列均满足条件的第一行记录,再多扫描一行记录判断EDITION_NAME列不满足即可停止。
IDX_T1CO_OWN_EDI索引:
根据索引特性直接访问到两列均满足条件的第一行记录,再多扫描一行记录判断EDITION_NAME列不满足即可停止。
得出结论:等值查询时索引列顺序访问效率一样。
2.3 等值+范围查询
测试等值+范围查询的情况,不同索引顺序查询效率是否相同:
--SQL文本如下:
select count(*) from t1co where owner='SYS' and EDITION_NAME like '200%';
--查询表中施加了谓词的列值数量。
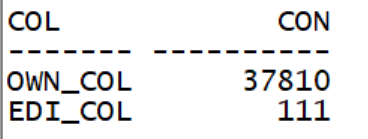
通过分析可知,OWNER列过滤性较差,EDITION_NAME列过滤性较好。如下测试采用不同的索引性能开销。

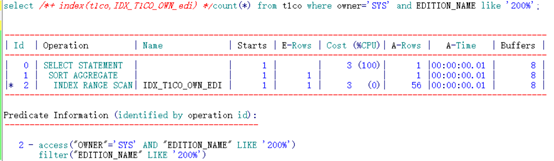
可以看到,通过不同顺序的两个索引访问,其逻辑读有了一定的差异。
以下通过EXCEL形象的展示一下:
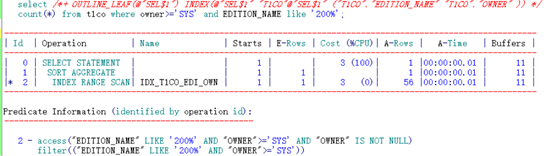
IDX_T1CO_EDI_OWN索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“EDITION_NAME” LIKE ‘200%’ AND “OWNER”=‘SYS’),之后顺序扫描,由于索引中首列为范围查询,扫描到第二行时,还需判断第二列是否等于SYS。因此还需要做额外的filter((“OWNER”=‘SYS’ AND “EDITION_NAME” LIKE ‘200%’))。需要访问过多的结果集。直到第一列中超过范围查询的边界,才能停止。
IDX_T1CO_OWN_EDI索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“OWNER”=‘SYS’ AND “EDITION_NAME” LIKE ‘200%’),之后按照首列顺序扫描即可,扫描过程需要再次过滤满足条件filter(“EDITION_NAME” LIKE ‘200%’)的记录。最后扫描到首列不满足条件后即可停止。
得出结论:等值+范围查询时的索引建立原则:等值查询在前、范围查询在后。索引高效。不用考虑施加了谓词的记录数多少。如本例。
2.4 范围+范围查询
测试范围+范围查询的情况,不同索引顺序查询效率是否相同:
--SQL文本如下:
select count(*) from t1co where owner>='SYS' and EDITION_NAME like '200%';
--查询表中施加了谓词的列值数量。

通过分析可知,OWNER列过滤性较差,EDITION_NAME列过滤性较好。如下测试采用不同的索引性能开销。

可以看到,通过不同顺序的两个索引访问,其逻辑读差异巨大。
以下通过EXCEL形象的展示一下:
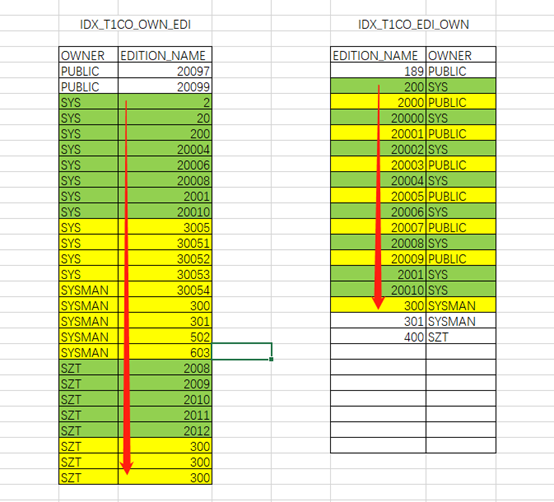
IDX_T1CO_EDI_OWN索引:
根据索引特性直接访问到两列均满足条件的第一行记录access(“OWNER”>=‘SYS’ AND “EDITION_NAME” LIKE ‘200%’ AND “OWNER” IS NOT NULL),之后顺序扫描,由于索引首先按照OWNER列排序,扫描过程中还需要过滤大量数据filter(“EDITION_NAME” LIKE ‘200%’),由于满足首列条件记录数很多,还需要扫描完全部记录才能停止。
IDX_T1CO_OWN_EDI索引:
根据索引特性直接访问到两列均满足条件的第一行记录access(“EDITION_NAME” LIKE ‘200%’ AND “OWNER”>=‘SYS’ AND “OWNER” IS NOT NULL),之后顺序扫描,由于索引首先按照EDITION_NAME列排序,扫描过程中扫到不满足首列条件时即可直接跳过本条目的判断,减少了访问的开销。只需要在扫描过程中进行filter((“EDITION_NAME” LIKE ‘200%’ AND “OWNER”>=‘SYS’)条件的过滤步骤即可,实际访问数据小于按照owner列排序的情况。当扫描到首列超出边界值时,即可停止扫描。
得出结论:范围+范围查询时的索引建立原则:过滤性好的列在前、过滤性差的列在后。
第三章 多表连接查询场景
实际的查询中仅对单表查询还是很少见的。大部分查询都是多表连接。但为了减少测试的复杂度,本部分仅以两表作为分析。
同时考虑到HASH连接对索引的依赖性较小,排序合并连接在实际环境中出现较少。本部分主要以两表NL连接的方式进行测试分析。NL连接时驱动表的连接条件过滤性对性能影响不大,因此下面测试主要以被驱动表的连接及限制条件的过滤性作为对比目标。
3.1 创建测试脚本:
--创建测试表t2co;用作被驱动表
create table t2co as select * from dba_objects;
--调整列类型以便让以下实验数据分布更直观;
alter table t2co modify(EDITION_NAME int);
update t2co set EDITION_NAME=object_id;
--创建被驱动表上的不同可选择率及列顺序的索引,以下用不同的列及索引分别测试:
create index idx_t2co_id_edi on t2co(data_object_id,edition_name);
create index idx_t2co_edi_id on t2co(edition_name,data_object_id);
create index idx_t2co_id_type on t2co(data_object_id,object_type);
create index idx_t2co_type_id on t2co(object_type,data_object_id);
--创建驱动表过滤条件加连接条件索引,减少额外回表步骤
create index idx_t1co_id_oid on t1co(object_id,data_object_id);
--收集统计信息:
exec dbms_stats.gather_table_stats('szt','T1CO');
exec dbms_stats.gather_table_stats('szt','T2CO');
3.2 等值连接+等值限制条件
测试大多数的等值连接+等值限制条件的场景。
3.2.1 限制条件过滤性很差:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id=t2co.data_object_id and t2co.object_type ='TABLE';
--查询表中满足连接列及施加了谓词过滤的列值数量。
通过分析可知,object_type列过滤性较差。如下测试采用不同的索引性能开销。
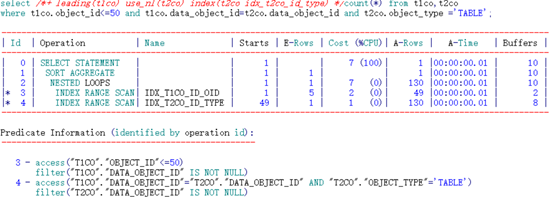
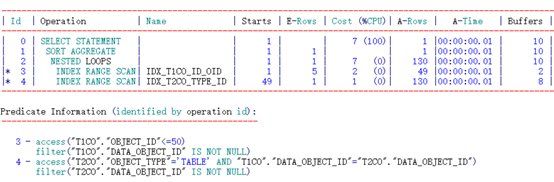
可以看到,通过不同顺序的两个索引访问,其逻辑读完全相同。思考一下索引的结构?
以下通过EXCEL形象的展示一下:
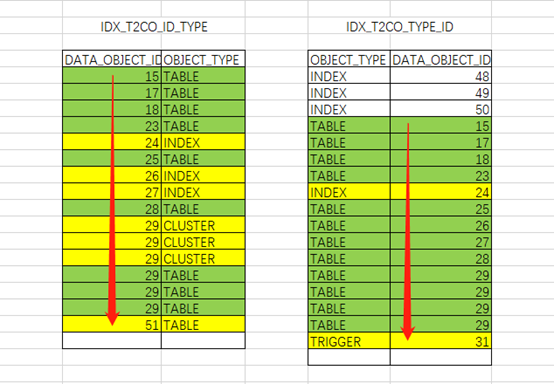
IDX_T2CO_ID_TYPE索引:
根据索引特性直接访问到两列均满足条件的第一行记录access(“T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“OBJECT_TYPE”=‘TABLE’),之后按照access顺序扫描,过程中只需要再过滤判断filter(“T2CO”.“DATA_OBJECT_ID” IS NOT NULL)记录即可
定位到DATA_OBJECT_ID列不满足连接条件时即可停止。
IDX_T2CO_TYPE_ID索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T2CO”.“OBJECT_TYPE”=‘TABLE’ AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID”),之后按照access顺序扫描,过程中只需要再过滤判断filter(“T2CO”.“DATA_OBJECT_ID” IS NOT NULL)记录即可。定位到OBJECT_TYPE不满足限制条件时即可停止。
得出结论:访问的索引条目基本相等。等值连接+等值限制条件时,被驱动表不同的索引列顺序对性能影响不大。
3.2.2 限制条件过滤性很好:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id=t2co.data_object_id and t2co.edition_name ='88';
--查询表中满足连接列及施加了谓词过滤的列值数量:
通过分析可知,edition_name列过滤性较好。如下测试采用不同的索引性能开销。
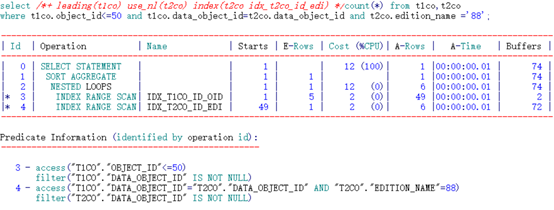
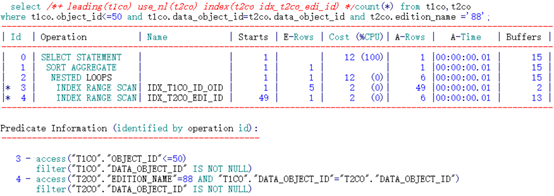
可以看到,通过不同顺序的两个索引访问,其逻辑读有了一定的差异。
限制条件在前的索引列访问更高效。
以下通过EXCEL形象的展示一下:
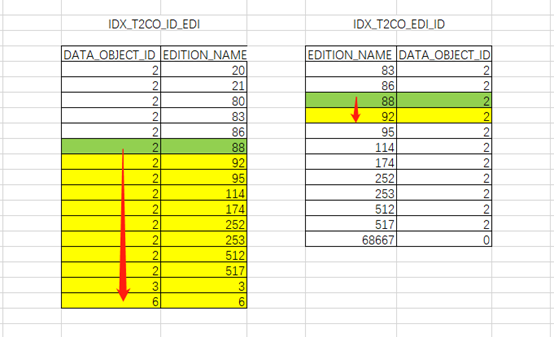
IDX_T2CO_ID_EDI索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“EDITION_NAME”=88),之后需要继续扫描后续的索引条目,并判断限制条件是否满足,直到连接条件不满足记录时才可停止。中途抛弃了大量无用数据。
IDX_T2CO_EDI_ID索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T2CO”.“EDITION_NAME”=88 AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID”),之后只需要判断不再满足过滤条件后即可停止。扫描的索引条目较少。
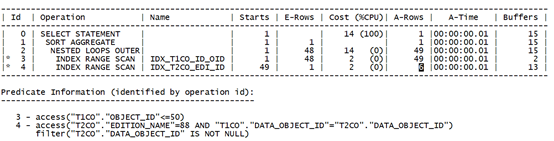
针对于外连接的场景,只是在内连接情况下不过滤原表数据。因此其访问效率与内连接一致,不再单独测试。
得出结论:访问的索引条目差异较大。过滤性好的限制条件列在前时,可以有效过滤掉大部分数据减少访问的索引条目。
当限制条件列过滤性较好时,限制条件在前连接条件在后时索引的效率较好。
3.3 等值连接+范围限制条件
测试等值连接条件+被驱动表范围限制条件的场景。
3.3.1 限制条件过滤性很差:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id=t2co.data_object_id and t2co.object_type >='TABLE';
--查询表中满足连接列及施加了谓词过滤的列值数量:
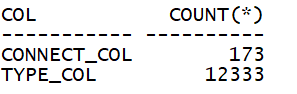
通过分析可知,object_type列过滤性较差。如下测试采用不同的索引性能开销。
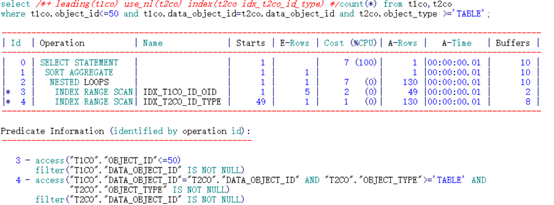
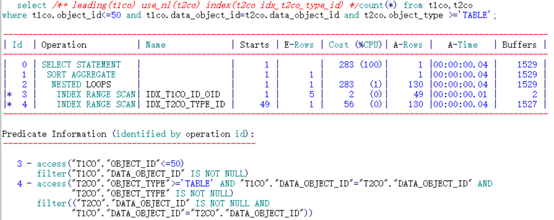
可以看到,通过不同顺序的两个索引访问,其逻辑读有了较大幅度的差异。
范围限制条件在前、连接条件在后的索引消耗了巨大的逻辑读。究其原因,是由于通过被驱动表索引访问后还不能完全确定是否全部满足连接条件,还要在索引上过滤一次连接条件。造成了额外的逻辑读消耗。
以下通过EXCEL形象的展示一下:
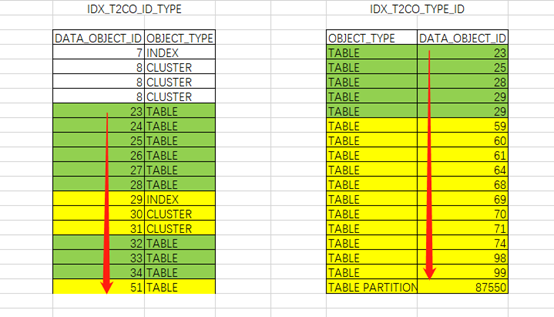
IDX_T2CO_ID_TYPE索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“OBJECT_TYPE”>=‘TABLE’ AND “T2CO”.“OBJECT_TYPE” IS NOT NULL),之后根据access顺序扫描记录,根据filter (“T2CO”.“DATA_OBJECT_ID” IS NOT NULL)抛弃不满足的,定位到DATA_OBJECT_ID列不满足连接条件时即可停止。
IDX_T2CO_TYPE_ID索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T2CO”.“OBJECT_TYPE”>=‘TABLE’ AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND"T2CO".“OBJECT_TYPE” IS NOT NULL),之后根据access顺序扫描记录,由于连接条件为索引第二列,因此需要获得过滤条件后访问大量数据,并扫描不满足连接条件的条目并去掉。中途需要通过条件filter ((“T2CO”.“DATA_OBJECT_ID” IS NOT NULL AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID”))过滤。之后还要继续扫描限制范围条件,直到超出范围条件后才可停止。
得出结论:限制条件为范围查询时,限制列在前的情况扫描了大量的索引条目,造成大量的查询开销。
限制条件过滤性较差且为范围查询时,限制列在前、连接列在后的索引性能极差。
3.3.2 限制条件过滤性很好:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id=t2co.data_object_id and t2co.edition_name <=10;
--查询表中满足连接列及施加了谓词过滤的列值数量:
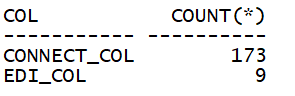
通过分析可知,edition_name列过滤性较好。如下测试采用不同的索引性能开销。
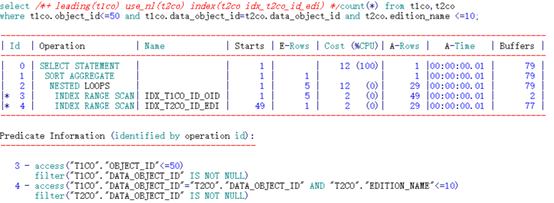
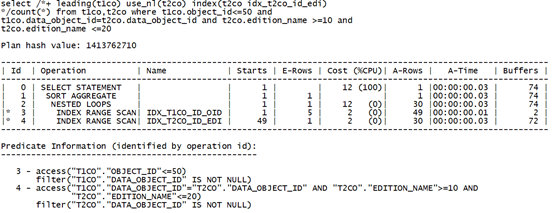
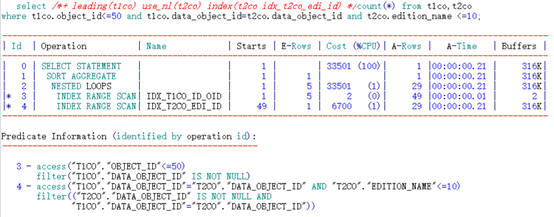
可以看到,通过不同顺序的两个索引访问,其逻辑读同样有较大的性能差异。
限制条件列在前的索引列访问异常低效。
改变过滤条件取值范围:
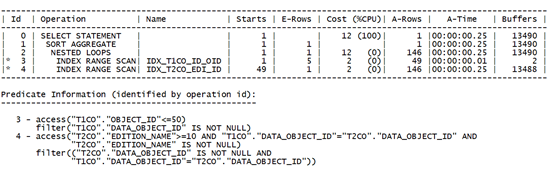
可以看到,增大了过滤条件范围,实际消耗的逻辑读反而更小。
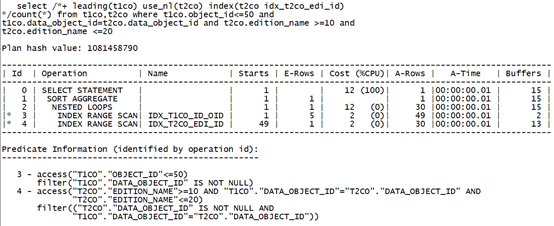
改变限制条件的结构,让数据库可以按首列索引顺序直接定位到第一条记录。资源消耗比连接列在前还有低。尽管同样是返回30行数据。
通过比较上述范围条件谓词部分的不同可知:
范围条件为大于时,优化器只需要按照查询条件列直接定位到满足条件的第一条记录,之后按照索引顺序扫描即可。
范围条件为小于时,数据库无法直接定位到满足条件的第一条记录。因此只能通过索引的第二列连接条件去定位记录。那就造成会从开头顺序访问,过程中才会判断索引首列是否满足记录。更加剧了巨大逻辑读的消耗。
以下通过EXCEL形象的展示一下:
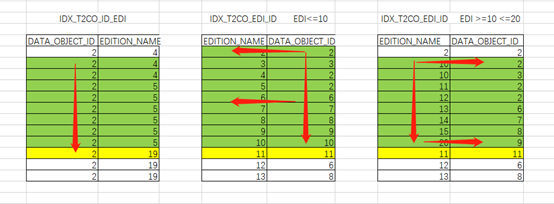
IDX_T2CO_ID_EDI索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T2CO”.“EDITION_NAME”>=10 and “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“EDITION_NAME”<=20),之后根据access顺序扫描,直到连接条件不满足记录时即可停止。访问路径取决于连接条件。
IDX_T2CO_EDI_ID索引>=10 <=20:
限制条件为大于某值并小于某值,数据库可以直接访问到两列均满足条件的第一行记录(“T2CO”.“EDITION_NAME”>=10 AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND
“T2CO”.“EDITION_NAME”<=20)。
之后根据access顺序扫描,由于索引按照限制条件列顺序存储,扫描过程中还需要过滤连接条件记录filter((“T2CO”.“DATA_OBJECT_ID” IS NOT NULL AND “T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID”))。扫描到限制条件终点后直接停止。实际访问的索引条目比连接条件在前还要少,因此高效。
IDX_T2CO_EDI_ID索引<=10:
限制条件为小于某值,只能从索引的开头扫描索引第二列,再判断第一列是否在范围条件内(“T1CO”.“DATA_OBJECT_ID”=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“EDITION_NAME”<=10)。再依次顺序访问。造成的了访问条目的无序性。实际消耗了巨大的逻辑读。
得出结论:
对于限制条件过滤性较好且指定了限制条件的起点时,限制条件在前连接条件在后索引更高效。
如果没有指定限制条件起点,由于访问路径的关系反而会造成查询开销巨增。实际开销还会远远高于连接条件在前的情况。
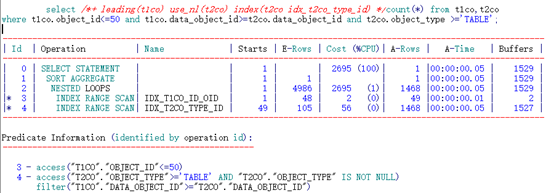
3.4 范围连接+等值限制条件
测试连接条件为范围连接+被驱动表限制条件为等值的场景。
3.4.1 限制条件过滤性很差:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id>=t2co.data_object_id and t2co.object_type ='TABLE';
--查询表中满足连接列及施加了谓词过滤的列值数量:
通过分析可知,object_type列过滤性较差。如下测试采用不同的索引性能开销。
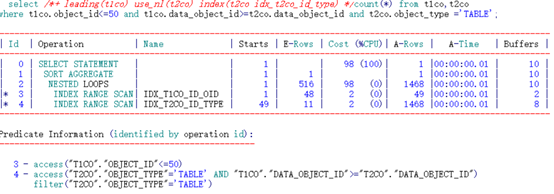
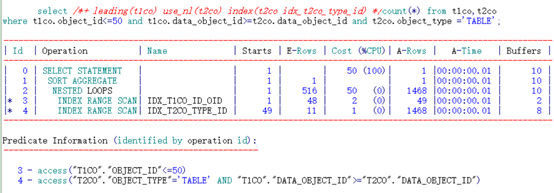
可以看到,通过不同顺序的两个索引访问,其逻辑读完全相同。
以下通过EXCEL形象的展示一下:
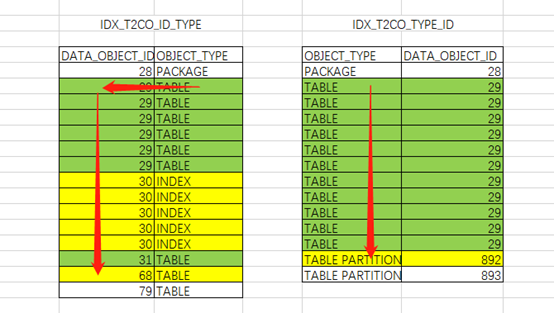
IDX_T2CO_ID_TYPE索引:
由于限制条件为等值查询,数据库可以提前将限制条件判断提前,用于定位扫描的起点。
(“T2CO”.“OBJECT_TYPE”=‘TABLE’)。之后按照索引列DATA_OBJECT_ID根据access顺序扫描即可。过程中需要根据条件filter(“T2CO”.“OBJECT_TYPE”=‘TABLE’)过滤数据。定位到DATA_OBJECT_ID列不满足连接条件时即可停止。
IDX_T2CO_TYPE_ID索引:
根据索引特性直接访问到两列均满足条件的第一行记录(“T2CO”.“OBJECT_TYPE”=‘TABLE’ AND “T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”),之后根据access顺序扫描由于限制条件相等,扫描过程中只需要判断连接条件是否满足条件。定位到OBJECT_TYPE不满足限制条件时即可停止。
得出结论:访问的索引条目基本相等。范围连接+等值限制条件对索引列的顺序影响不大。
尽管两种方式逻辑读一致,但从访问索引的步骤来看仍然是后者更高效。
3.4.2 限制条件过滤性很好:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id>=t2co.data_object_id and t2co.edition_name =10;
--查询表中满足连接列及施加了谓词过滤的列值数量:

通过分析可知,edition_name列过滤性较好。如下测试采用不同的索引性能开销。
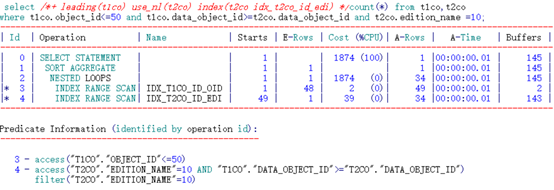
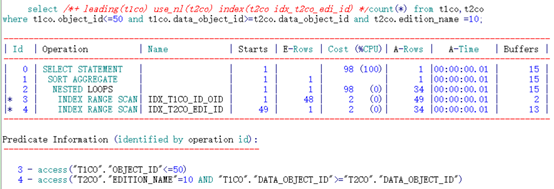
可以看到,通过不同顺序的两个索引访问,其逻辑读有了一定的差异。
限制条件在前的索引列访问更高效。
以下通过EXCEL形象的展示一下:
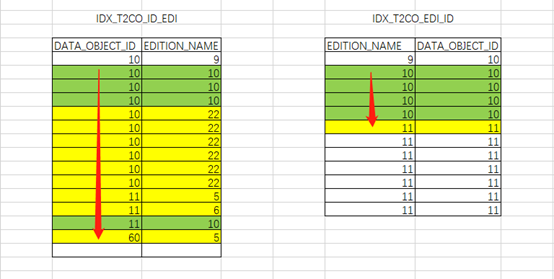
IDX_T2CO_ID_EDI索引:
由于限制条件为等值查询,数据库可以提前将限制条件判断提前,用于定位扫描的起点。
(“T2CO”.“EDITION_NAME”=10)。之后按照索引列DATA_OBJECT_ID根据access顺序扫描即可。过程中需要根据条件filter(“T2CO”.“EDITION_NAME”=10)过滤数据。定位到DATA_OBJECT_ID列不满足连接条件时停止。中途抛弃了大量无用数据。
IDX_T2CO_EDI_ID索引:
直接根据限制条件定位扫描的起点。(“T2CO”.“EDITION_NAME”=10)。之后按照索引通过access(“T2CO”.“EDITION_NAME”=10 AND “T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)顺序扫描。最后只需要判断不再满足限制条件后即可停止。扫描的索引条目较少。
得出结论:过滤性好的限制条件列在前时,可以有效过滤掉大部分数据减少访问的索引条目。因此当限制条件过滤性较好时,限制条件在前连接条件在后时索引的效率较好。
3.5 范围连接+范围限制条件
测试连接条件和被驱动表限制条件均为范围连接的场景。
3.5.1 限制条件过滤性很差:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id>=t2co.data_object_id and t2co.object_type >='TABLE';
--查询表中满足连接列及施加了谓词过滤的列值数量:
通过分析可知,object_type列过滤性较差。如下测试采用不同的索引性能开销。
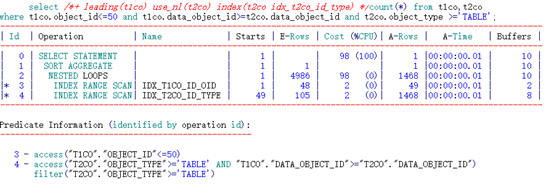
可以看到,限制条件列在前的索引,其逻辑读开销巨大。通过谓词部分可以看出,其索引只能采用限制条件object_type的过滤,甚至都无法对同样是索引列的连接条件进行过滤,只能通过 filter方式进行过滤,因此就造成了需要在索引中过滤掉大部分不满足的数据,造成了逻辑读的消耗过大。
以下通过EXCEL形象的展示一下:
IDX_T2CO_ID_TYPE索引:
由于记录了限制条件起点,数据库可以提前将限制条件起点判断提前,用于定位扫描的起点。
之后通过access扫描顺序扫描,过程中只需要再判断条件filter(“T2CO”.“OBJECT_TYPE”>=‘TABLE’)抛弃不满足的,定位到DATA_OBJECT_ID列不满足连接条件时即可停止。
IDX_T2CO_TYPE_ID索引:
由于连接条件及限制条件均为范围查询,数据库只能通过索引访问限制条件的首列"T2CO".“OBJECT_TYPE”>=‘TABLE’,对于连接条件无法在范围扫描时同时判断是否满足条件,因此访问的大量的数据后再通过filter(“T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)过滤。消耗了大量的逻辑读资源。
得出结论:限制条件在前的索引访问的索引条目会远远大于连接条件在前的索引。因此消耗逻辑读较大。
3.5.2 限制条件过滤性很好:
--SQL文本如下:
select count(*) from t1co,t2co
where t1co.object_id<=50 and t1co.data_object_id>=t2co.data_object_id and t2co.edition_name <=10;
--查询表中满足连接列及施加了谓词过滤的列值数量:
通过分析可知,edition_name列过滤性较好。如下测试采用不同的索引性能开销。
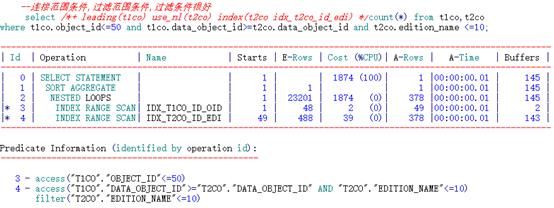
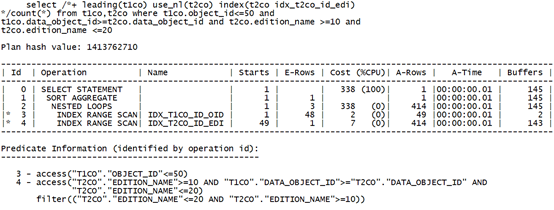
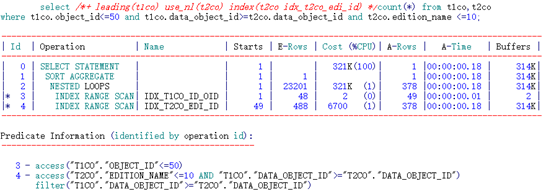
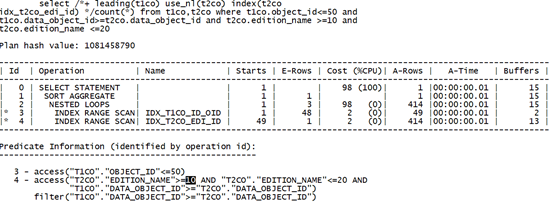
可以看到,限制条件在前的索引消耗逻辑读巨大。究其原因,是由于数据库无法定位到限制条件的起点。调整限制条件范围后,性能提升明显。
以下通过EXCEL形象的展示一下:
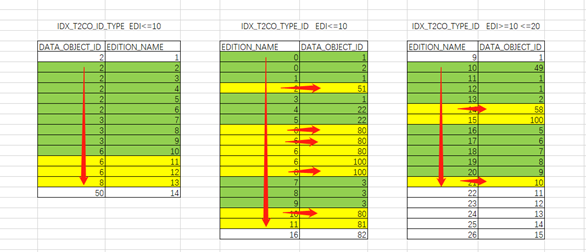
IDX_T2CO_ID_TYPE索引 EDI<=10:
由于限制条件为小于查询,数据库无法提前获取被驱动表限制条件的起点。因此只能通过(“T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID” AND “T2CO”.“EDITION_NAME”<=10)获取访问的起点,之后通过access扫描顺序扫描。过程中需要判断filter(“T2CO”.“EDITION_NAME”<=10)限制条件是否满足。直到DATA_OBJECT_ID列不满足连接条件才可以停止。
IDX_T2CO_TYPE_ID索引 EDI<=10:
由于限制条件均为小于查询,数据库无法提前获取被驱动表限制条件的起点。只能通过索引的最开始条目开始扫描满足access(“T2CO”.“EDITION_NAME”<=10 AND “T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)的条件。过程中还需要再次过滤一遍连接条件:filter(“T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)。访问了大量的索引条目,直到限制列超过限制条件时才可停止。
IDX_T2CO_TYPE_ID索引 EDI>=10 <=20:
由于限制条件均为大于+小于查询,数据库可以获取被驱动表限制条件的起点。可以从起点开始条目开始扫描满足access(“T2CO”.“EDITION_NAME”>=10 AND “T2CO”.“EDITION_NAME”<=20 and “T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)的条件。过程中需要过滤一遍连接条件:filter(“T1CO”.“DATA_OBJECT_ID”>=“T2CO”.“DATA_OBJECT_ID”)。当限制列超出边界值时即可停止。
得出结论:限制条件在前的索引访问,当可以有效获取限制条件起点时,访问的索引条目较少。访问效率更高。
第四章 总结
基于以上分析及测试,得出以下结论:
单表查询:
等值查询时索引列顺序访问效率一样;
等值查询在前、范围查询在后。索引高效;
都是范围查询时,过滤性好的列在前、过滤性差的列在后。索引高效。
多表NL连接查询:
被驱动表限制条件过滤性很好,且能获取到条件起点时,索引高效。
其余情况还是建议采用连接条件在前、限制条件在后的索引。效率更高效。
注:以上过滤性的判断还是需要与连接条件列返回的数据量做比较去判断,并非单纯通过限制条件返回的记录数多少来定。某些表现还受数据库版本影响,但总体结论不变。
