




事务
幂等性
Kafka在引⼊幂等性之前,Producer向Broker发送消息,然后Broker将消息追加到消息流中后给Producer返回Ack信号值。实现流程如下:

但是⽣产中,会出现各种不确定的因素,⽐如在Producer在发送给Broker的时候出现⽹络异常。⽐如以下这种异常情况的出现:
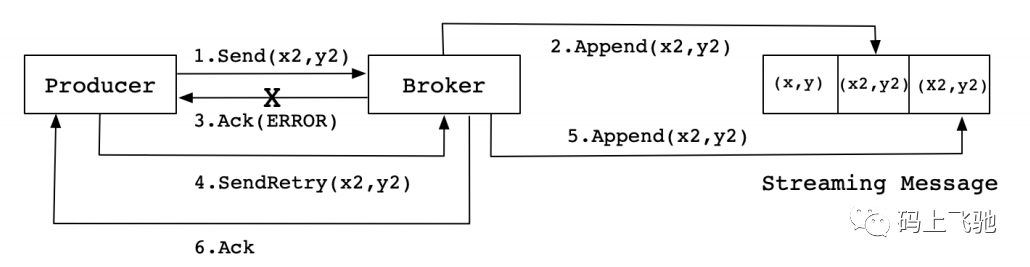
上图这种情况,当Producer第⼀次发送消息给Broker时,Broker将消息(x2,y2)追加到了消息流中,但是在返回Ack信号给Producer时失败了(⽐如⽹络异常) 。此时,Producer端触发重试机制,将消息(x2,y2)重新发送给Broker,Broker接收到消息后,再次将该消息追加到消息流中,然后成功返回Ack信号给Producer。这样下来,消息流中就被重复追加了两条相同的(x2,y2)的消息。
所谓幂等性,数学概念就是:f(f(x)) = f(x) 。f函数表示对消息的处理。⽐如,银⾏转账,如果失败,需要重试。不管重试多少次,都要保证最终结果⼀定是⼀致的。
保证在消息重发的时候,消费者不会重复处理。即使在消费者收到重复消息的时候,重复处理,也要保证最终结果的⼀致性。
幂等性实现
添加唯⼀ID,类似于数据库的主键,⽤于唯⼀标记⼀个消息。
Kafka为了实现幂等性,它在底层设计架构中引⼊了ProducerID和SequenceNumber。
ProducerID:在每个新的Producer初始化时,会被分配⼀个唯⼀的ProducerID,这个ProducerID对客户端使⽤者是不可⻅的。
SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应⼀个从0开始单调递增的SequenceNumber值。
同样,这是⼀种理想状态下的发送流程。实际情况下,会有很多不确定的因素,⽐如Broker在发送Ack信号给Producer时出现⽹络异常,导致发送失败。异常情况如下图所示:
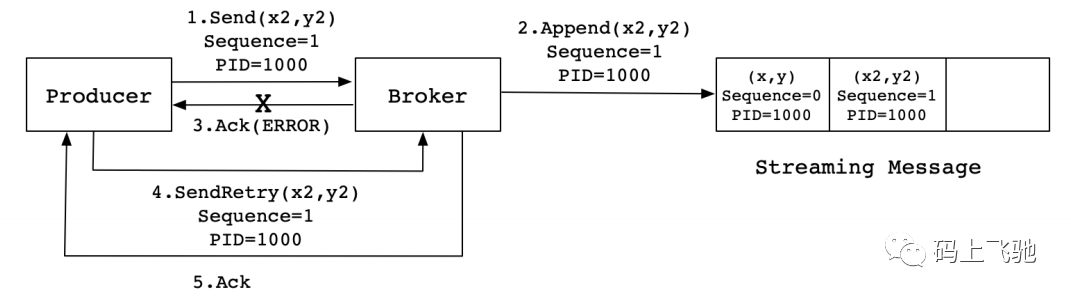
当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发⽣异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引⼊了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,⽽之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有⼀条(x2,y2),不会出现重复发送的情况。
客户端在⽣成Producer时,会实例化如下代码:
// 实例化⼀个Producer对象Producer<String, String> producer = new KafkaProducer<>(props);
在org.apache.kafka.clients.producer.internals.Sender类中,在run()中有⼀个maybeWaitForPid()⽅法,⽤来⽣成⼀个ProducerID,实现代码如下:
private void maybeWaitForPid() {if (transactionState == null)return;while (!transactionState.hasPid()) {try {Node node = awaitLeastLoadedNodeReady(requestTimeout);if (node != null) {ClientResponse response = sendAndAwaitInitPidRequest(node);if (response.hasResponse() && (response.responseBody() instanceofInitPidResponse)) {InitPidResponse initPidResponse = (InitPidResponse)response.responseBody();transactionState.setPidAndEpoch(initPidResponse.producerId(),initPidResponse.epoch());} else {log.error("Received an unexpected response type for anInitPidRequest from {}. " +"We will back off and try again.", node);}} else {log.debug("Could not find an available broker to sendInitPidRequest to. " +"We will back off and try again.");}} catch (Exception e) {log.warn("Received an exception while trying to get a pid. Will backoff and retry.", e);}log.trace("Retry InitPidRequest in {}ms.", retryBackoffMs);time.sleep(retryBackoffMs);metadata.requestUpdate();}}
事务操作
在Kafka事务中,⼀个原⼦性操作,根据操作类型可以分为3种情况。情况如下:
1:只有Producer⽣产消息,这种场景需要事务的介⼊;
2:消费消息和⽣产消息并存,⽐如Consumer&Producer模式,这种场景是⼀般Kafka项⽬中⽐较常⻅的模式,需要事务介⼊;
3:只有Consumer消费消息,这种操作在实际项⽬中意义不⼤,和⼿动Commit Offsets的结果⼀样,⽽且这种场景不是事务的引⼊⽬的。
// 初始化事务,需要注意确保transation.id属性被分配void initTransactions();// 开启事务void beginTransaction() throws ProducerFencedException;// 为Consumer提供的在事务内Commit Offsets的操作void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException;// 提交事务void commitTransaction() throws ProducerFencedException;// 放弃事务,类似于回滚事务的操作void abortTransaction() throws ProducerFencedException;
控制器
Kafka集群包含若⼲个broker,broker.id指定broker的编号,编号不要重复。Kafka集群上创建的主题,包含若⼲个分区。每个分区包含若⼲个副本,副本因⼦包括了Follower副本和Leader副本。副本⼜分为ISR(同步副本分区)和OSR(⾮同步副本分区)。
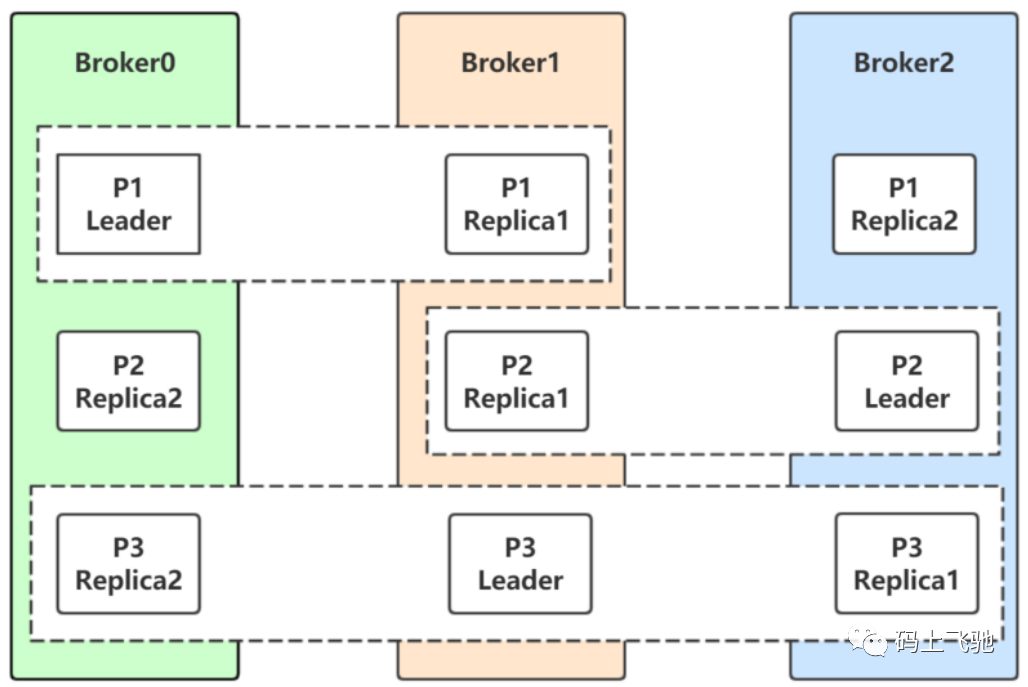
控制器就是⼀个broker。控制器除了⼀般broker的功能,还负责Leader分区的选举。
broker选举
集群⾥第⼀个启动的broker在Zookeeper中创建临时节点 <KafkaZkChroot>/controller 。其他broker在该控制器节点创建Zookeeper watch对象,使⽤Zookeeper的监听机制接收该节点的变更。
即:Kafka通过Zookeeper的分布式锁特性选举集群控制器。
每个新选出的控制器通过 Zookeeper 的条件递增操作获得⼀个全新的、数值更⼤的 controller epoch。其他broker 在知道当前 controller epoch 后,如果收到由控制器发出的包含较旧epoch 的消息,就会忽略它们,以防⽌“脑裂”。
⽐如当⼀个Leader副本分区所在的broker宕机,需要选举新的Leader副本分区,有可能两个具有不同纪元数字的控制器都选举了新的Leader副本分区,如果选举出来的Leader副本分区不⼀样,听谁的?脑裂了。有了纪元数字,直接使⽤纪元数字最新的控制器结果。
当控制器发现⼀个 broker 已经离开集群,那些失去Leader副本分区的Follower分区需要⼀个新Leader(这些分区的⾸领刚好是在这个 broker 上)。
控制器遍历这些Follower副本分区,并确定谁应该成为新Leader分区,然后向所有包含新Leader分区和现有Follower的 broker 发送请求。该请求消息包含了谁是新Leader副本分区以及谁是Follower副本分区的信息。随后,新Leader分区开始处理来⾃⽣产者和消费者的请求,⽽跟随者开始从新Leader副本分区消费消息。
当控制器发现⼀个 broker 加⼊集群时,它会使⽤ broker ID 来检查新加⼊的 broker 是否包含现有分区的副本。如果有,控制器就把变更通知发送给新加⼊的 broker 和其他 broker,新 broker上的副本分区开始从Leader分区那⾥消费消息,与Leader分区保持同步。
结论:
1:Kafka使⽤ Zookeeper 的分布式锁选举控制器,并在节点加⼊集群或退出集群时通知控制器。
2:控制器负责在节点加⼊或离开集群时进⾏分区Leader选举。
3:控制器使⽤epoch来避免“脑裂”。“脑裂”是指两个节点同时认为⾃⼰是当前的控制器。
可靠性保证
概念:
1:创建Topic的时候可以指定 --replication-factor 3 ,表示分区的副本数,不要超过broker的数量。
2:Leader是负责读写的节点,⽽其他副本则是Follower。Producer只把消息发送到Leader,Follower定期地到Leader上Pull数据。
3:ISR是Leader负责维护的与其保持同步的Replica列表,即当前活跃的副本列表。如果⼀个Follow落后太多,Leader会将它从ISR中移除。落后太多意思是该Follow复制的消息Follow⻓时间没有向Leader发送fetch请求(参数:replica.lag.time.max.ms 默认值:10000)。
4:为了保证可靠性,可以设置 acks=all 。Follower收到消息后,会像Leader发送ACK。⼀旦Leader收到了ISR中所有Replica的ACK,Leader就commit,那么Leader就向Producer发送ACK。
副本的分配:
当某个topic的 --replication-factor 为N(N>1)时,每个Partition都有N个副本,称作replica。原则上是将replica均匀的分配到整个集群上。不仅如此,partition的分配也同样需要均匀分配,为了更好的负载均衡。
副本分配的三个⽬标:
1:均衡地将副本分散于各个broker上。
2:对于某个broker上分配的分区,它的其他副本在其他broker上。
3:如果所有的broker都有机架信息,尽量将分区的各个副本分配到不同机架上的broker。
在不考虑机架信息的情况下:
1:第⼀个副本分区通过轮询的⽅式挑选⼀个broker,进⾏分配。该轮询从broker列表的随机位置进⾏轮询。
2:其余副本通过增加偏移进⾏分配。
副本复制
⽇志复制算法(log replication algorithm)必须提供的基本保证是,如果它告诉客户端消息已被提交,⽽当前Leader出现故障,新选出的Leader也必须具有该消息。在出现故障时,Kafka会从挂掉Leader的ISR⾥⾯选择⼀个Follower作为这个分区新的Leader。
每个分区的 leader 会维护⼀个in-sync replica(同步副本列表,⼜称 ISR)。当Producer向broker发送消息,消息先写⼊到对应Leader分区,然后复制到这个分区的所有副本中。ACKS=ALL时,只有将消息成功复制到所有同步副本(ISR)后,这条消息才算被提交。
什么情况下会导致⼀个副本与 leader 失去同步?
⼀个副本与 leader 失去同步的原因有很多,主要包括:
慢副本(Slow replica):follower replica 在⼀段时间内⼀直⽆法赶上 leader 的写进度。造成这种情况的最常⻅原因之⼀是 follower replica 上的 I/O瓶颈,导致它持久化⽇志的时间⽐它从 leader 消费消息的时间要⻓。
卡住副本(Stuck replica):follower replica 在很⻓⼀段时间内停⽌从 leader 获取消息。这可能是以为GC 停顿,或者副本出现故障。
刚启动副本(Bootstrapping replica):当⽤户给某个主题增加副本因⼦时,新的 follower replicas 是不同步的,直到它跟上 leader 的⽇志。
当副本落后于 leader 分区时,这个副本被认为是不同步或滞后的。在 Kafka中,副本的滞后于Leader是根据 replica.lag.time.max.ms 来衡量。
如何确认某个副本处于滞后状态?
通过 replica.lag.time.max.ms 来检测卡住副本(Stuck replica)在所有情况下都能很好地⼯作。它跟踪follower 副本没有向 leader 发送获取请求的时间,通过这个可以推断 follower 是否正常。另⼀⽅⾯,使⽤消息数量检测不同步慢副本(Slow replica)的模型只有在为单个主题或具有同类流量模式的多个主题设置这些参数时才能很好地⼯作,但我们发现它不能扩展到⽣产集群中所有主题。

